
En 2015, un grand nombre d'articles ont commencé à proclamer que Data Scientist était le job le plus séduisant du 21e siècle. Les progrès réalisés dans le domaine du machine learning et des capacités technologiques ont permis aux entreprises de finalement "révolutionner" leur mode de travail et de tirer des tendances des données collectées.
En 2019, une nouvelle statistique est apparue, révélant que 87% des projets de machine learning ne réussissent pas et ne parviennent jamais à atteindre les serveurs de production. Cette information a suscité l'émergence d'une nouvelle tendance, celle du MLOps et des outils visant à simplifier votre travail.
Il existe plusieurs définitions du MLOps. Une approche intègre les principes du DevOps avec des ajustements spécifiques pour répondre aux besoins du machine learning. Il aborde les enjeux de l'intégration continue, du déploiement continu et du ré-entraînement continu.
Une autre école souligne l'importance d'incorporer le MLOps dès la phase de définition des besoins. Il est essentiel de définir précisément les besoins et d'étudier leur faisabilité. Nous nous assurons d'avoir les données requises pour effectuer les prédictions, de fournir une réponse dans les délais impartis et, surtout, de répondre au problème réel posé.
Jetons un coup d'œil maintenant aux problèmes, tant organisationnels que techniques, auxquels les entreprises sont confrontées dans les projets de machine learning.
Communication au sein du projet
Pour maximiser vos chances de réussite dans les projets de machine learning, tournez-vous vers vos collègues.
Il existe une blague bien connue dans le domaine de la technologie : "Mais ça fonctionne sur ma machine!". Malgré les avancées des méthodes de développement classique, qui se sont mises à éradiquer cette problématique depuis 15-20 ans, il semblerait que le domaine du machine learning vienne tout juste de la découvrir.
Il y a deux clivages majeurs au sein des équipes data. Le premier se manifeste entre l'équipe métier et les data scientists. Dans ce contexte, il est essentiel de commencer par comprendre les besoins métier réels et d'éviter de résoudre des problèmes imaginaires. Les données possèdent leur propre signification et logique. Certaines valeurs et réponses sont acceptables, tandis que d'autres ne le sont pas. Plutôt que d'inventer les règles du jeu, il est préférable de les demander à vos collègues !
Le deuxième clivage se situe entre les data scientists et les ingénieurs chargés du déploiement et de l'intégration du modèle dans le produit. Il est inutile de célébrer prématurément les performances de son modèle. Cela dépend de la complexité du processus en place. Mais malheureusement, en règle générale, le modèle développé dans le notebook ne peut pas être déployé en production en une après-midi.
D'un point de vue technique, quels sont les premiers obstacles que les entreprises cherchent à surmonter en adoptant le MLOps ?
Traçabilité des expériences
J'ai une bonne nouvelle pour les data scientists ! Certaines pratiques peuvent rendre votre vie beaucoup plus facile, notamment la possibilité de suivre vos expériences.
Imaginons une situation, le modèle entraîné obtient une performance de 86% selon le critère choisi. Cela pourrait être considéré comme un bon résultat, ou peut-être pas, mais vous décidez de poursuivre le travail. Maintenant, si c'était la meilleure performance atteignable jusqu'à présent, comment pouvez-vous retrouver cette combinaison idéale d'architecture du modèle, de paramètres et éventuellement de données ?
Avant que la question du déploiement en production ne se pose, l'équipe data se consacre à la tâche fastidieuse de l'entraînement du modèle parfait. Peu importe si la tentative aboutit ou non, l'entraînement génère des informations utiles. De plus, tous les paramètres d'entrée, tels que la version des données, les features sélectionnées, les hyperparamètres, voire la version de l'architecture, permettent de comparer les expériences ou, le cas échéant, de les reproduire.
Si vous n'êtes pas prêt à mettre en place un pipeline complet pour tracer vos expériences, il est tout à fait possible de vous limiter à l'utilisation d'un notebook.
L'objectif est de consigner toutes les informations pertinentes (la définition de la pertinence dépendra de vos besoins) lors de chaque entraînement. Une base de données permettra une comparaison rapide entre les différentes exécutions, tandis que les requêtes SQL rendront son utilisation facile à tous, si une base de données relationnelle est utilisée. En l'absence d'une meilleure solution, un fichier .txt ou .json peut servir de point de repère, bien que la recherche puisse s'avérer complexe dans ce cas.
Déploiement automatique
Un autre défi à relever concerne le déploiement automatique. Bien entendu, il est possible de réaliser toutes les actions manuellement à chaque fois. Cependant, cela peut entraîner des erreurs, même si la version automatisée n'est pas infaillible non plus. De plus, ces actions sont chronophages. Dans le domaine de la technologie, nous cherchons toujours à automatiser les processus, car les avantages sont nombreux, et le domaine du machine learning ne fait pas exception.
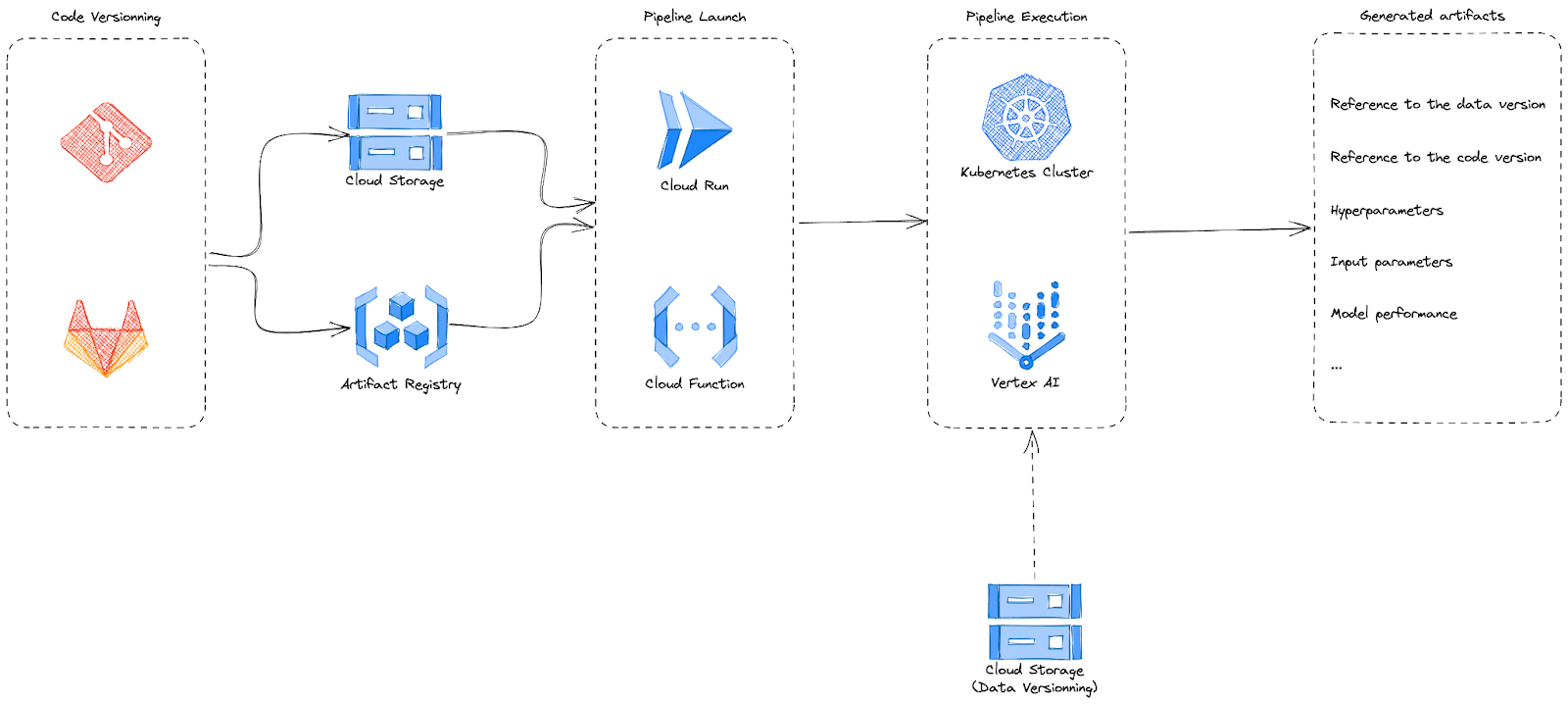
Le pipeline de machine learning comprend différentes étapes, dont la lecture des données, la génération des métadonnées, le prétraitement, l'entraînement du modèle et la validation. Cette définition du pipeline est dissociée du modèle et peut être gérée séparément. Conformément aux pratiques courantes dans la tech, le code associé aux deux éléments sera géré dans git.
Le code peut être déposé dans le Cloud Storage afin d'être utilisé comme module externe lors de l'exécution du pipeline ou pour construire une image docker. Étant donné la durée souvent élevée de l'entraînement, le lancement du pipeline peut être asynchrone. En cas d'erreur, le pipeline communiquera le résultat.
Une fois que le modèle a été entraîné, validé et déployé sur un endpoint, il devient essentiel d'assurer son monitoring. Cela implique le suivi des métriques techniques pour s'assurer de l'accessibilité du modèle, ainsi que des métriques relatives à son utilisation et, dans la mesure du possible, des données transmises à l'endpoint. Étant donné que notre monde évolue constamment, les variations dans la distribution des données peuvent avoir un impact sur les performances du modèle.
Un exemple d'architecture ressemblera à ceci :
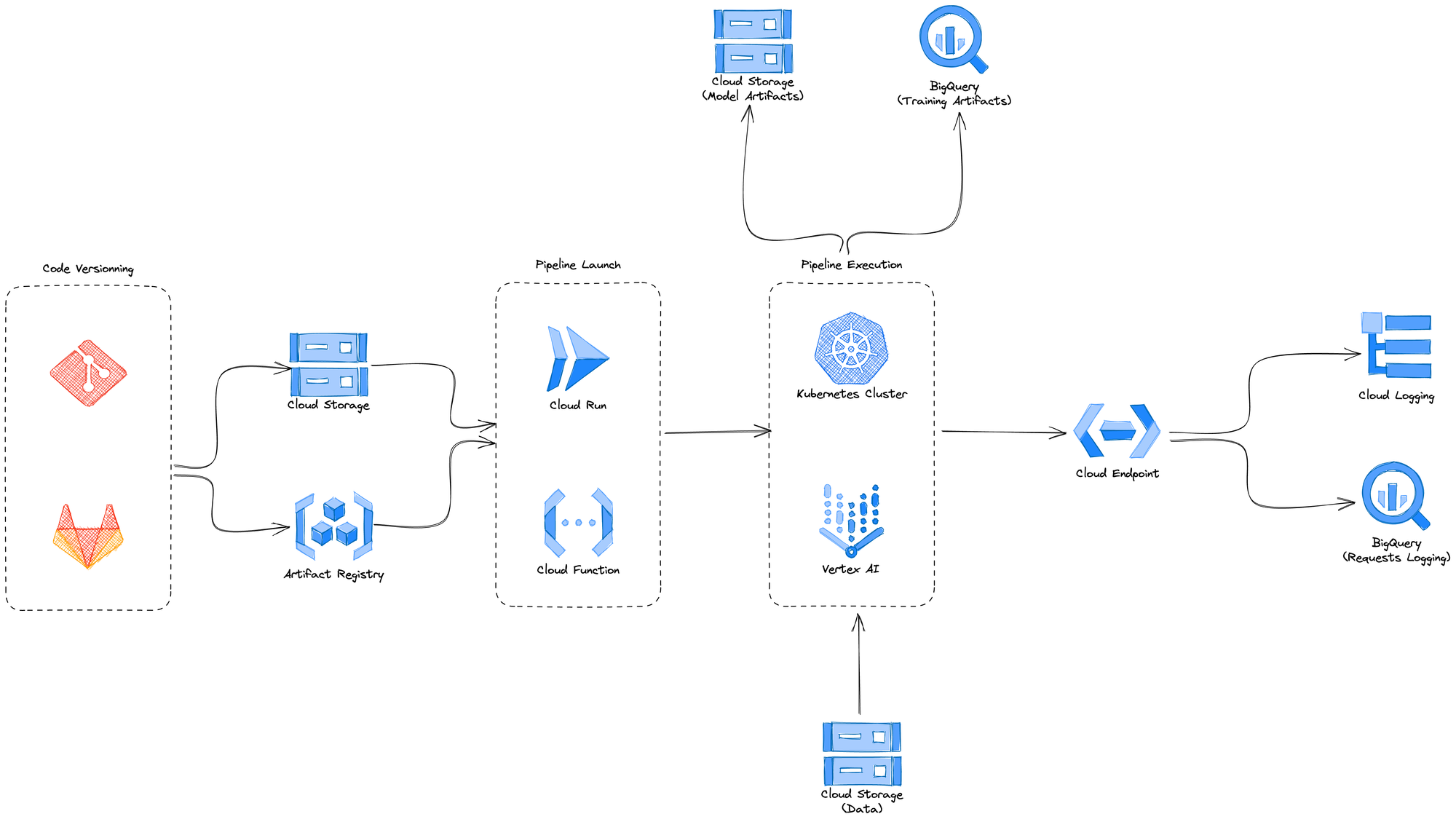
Les étapes suivantes peuvent consister à monitorer les données envoyées à l'endpoint de prédiction pour détecter le data skew / data drift ; à planifier le ré-entraînement automatique, soit de manière récurrente, soit en utilisant une feedback loop ; à rendre le logging plus complet, etc. Certains composants apparaîtront plus fréquemment dans les pipelines, mais cela ne signifie en aucun cas que tous ces éléments seront nécessaires.
Le fameux notebook
Les ingénieurs responsables du déploiement des modèles en production sont souvent terrifiés par l'utilisation du notebook, car le code qu'il contient n'est souvent pas conforme aux meilleures pratiques de développement. Bien que le métier de Data Scientist diffère de celui de l'ingénierie, est-ce que cela signifie qu'il faut abandonner complètement ce mode de fonctionnement ?
Si vous en êtes à votre premier modèle, il est peu probable qu'il soit rentable de mobiliser toute une équipe pour le déploiement, la création de pipelines et l'automatisation de tous les aspects. L'objectif principal est de pouvoir effectuer des tests le plus rapidement possible et de déterminer si le modèle apporte une valeur ajoutée.
En effet, une fois le modèle entraîné, il est possible de l'exporter et de le sauvegarder en dehors du notebook, puis de l'uploader sur un endpoint. Même si ces étapes doivent être effectuées manuellement, cela ne signifie pas qu'il faut s'en priver totalement.
Dans le cadre de l'entreprise, l'objectif est d'obtenir rapidement de la valeur. Certes, le déploiement manuel peut entraîner des erreurs, car nous, les êtres humains, sommes prônes aux erreurs. Toutefois, il peut parfois être plus rapide d'effectuer une action manuelle que de chercher à optimiser la procédure. Et lors de la phase de POC (Proof of Concept), la rapidité est cruciale.
Nous avons débuté en parlant des tendances et nous terminerons également en mettant l'accent sur ce point.
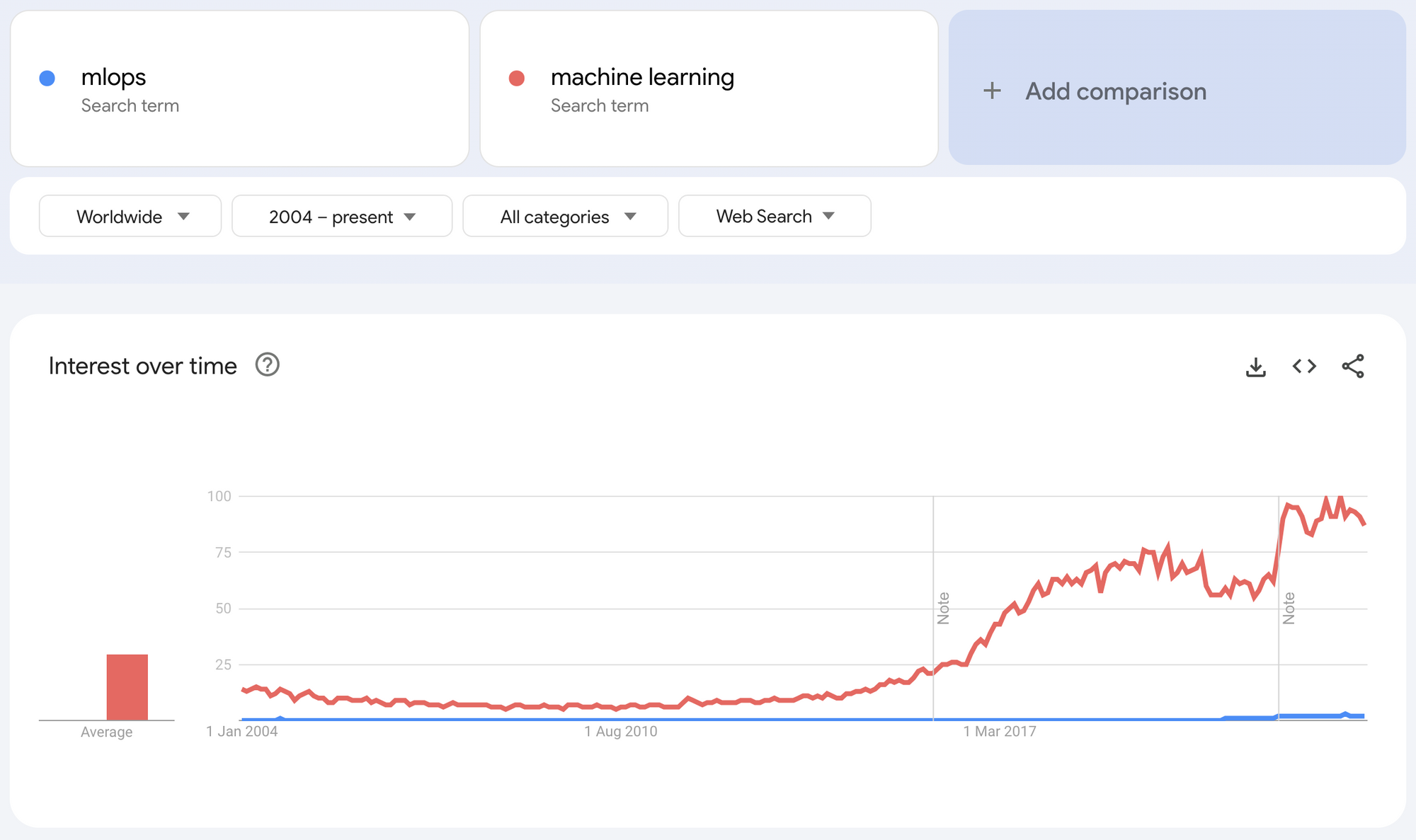
En comparant les recherches sur Google entre "mlops" et "machine learning", on observe une dynamique intéressante. Malgré l'attrait croissant du machine learning qui continue de captiver de plus en plus de personnes et dépasse MLOps, faut-il considérer la situation comme alarmante ? Il est important de noter que MLOps ne garantit ni le succès ni la qualité, mais représente plutôt un outil à utiliser de manière intelligente.








{kind=link}