Pour enrichir la série d'articles sur les jeux vidéo initiée par Alexandre, un fait marquant de 2023 a retenu notre attention : en France, le jeu Mario Kart maintient sa position de leader incontesté en termes de popularité. Dans un contexte marqué par des avancées significatives et des tournants majeurs dans le domaine de l'intelligence artificielle, je me suis lancé le défi de créer un petit bot python qui utilise le machine learning pour diriger le kart de manière autonome. Conscient des contraintes liées aux droits d'auteur et animé par le désir d'intégrer un pilote original sous les traits d'un axolotl, mon choix s'est porté sur le jeu en open source "Super Tux Kart".
Objectifs:
Pour que le kart navigue correctement sur le circuit, le bot doit être capable de décider à quel moment effectuer un virage à gauche ou à droite, en se basant sur les images du circuit qu'il reçoit en entrée. Cela constitue un problème de classification binaire : "0" indiquant de tourner à gauche, et "1" pour tourner à droite. Le script est programmé pour maintenir en continu la pression sur la touche de mouvement et d'accélération. Il effectue périodiquement des captures d'écran, similaires à celles qu'un joueur verrait, et, en fonction du résultat de la classification, décide si les touches de direction gauche ou droite doivent être activées.
Extraction des données:
L’extraction des données se fait en deux parties con-jointes. Un screenshot pris chaque seconde qui sera sauvegardée en portant son timestamp, par exemple ‘2023-12-07 23:11:14.jpg’. Ces images sont stockées et gardées pour davantage de traitement. Simultanément, un keylogger va récupérer les pressions sur le clavier, pour récupérer les touches gauche et droite et le timestamp de pression.
Nettoyage de la donnée.
J'étais en possession de deux catégories de données : une série d'images et un ensemble de données relatives aux pressions de touches sur un clavier. Il était nécessaire de procéder à un nettoyage et à une standardisation de ces données.
Pour les pressions sur le clavier, il a suffi de retirer les lignes qui n’étaient pas ‘Key.left’ ou ‘Key.right’ et de retirer les millisecondes dans les timestamps qui étaient sous forme ‘2023-12-07 23:11:10,453’, transformées en ‘2023-12-07 23:11:10’ puis ‘2023-12-07 23:11:10.jpg’ afin d’utiliser cela comme clé de jointure avec les données images. Enfin, j’ai transformé les ‘Key.left’ et ‘Key.right’ en 0 et 1 que les modèles de machine learning peuvent comprendre.
Concernant les images, elles contiennent beaucoup d’informations et représentent donc un traitement lourd avec beaucoup de bruit qui n’aident pas le modèle à vraiment apprendre.
C'est la raison pour laquelle j'ai choisi d'utiliser le filtre de détection de contours de Canny sur les images. Ce filtre est efficace pour identifier les bords dans une image, permettant ainsi d'extraire des caractéristiques importantes. Il est couramment employé dans les systèmes de voitures autonomes pour la détection de bordures. Ce choix me paraissait judicieux pour déterminer les moments opportuns pour tourner à gauche ou à droite.

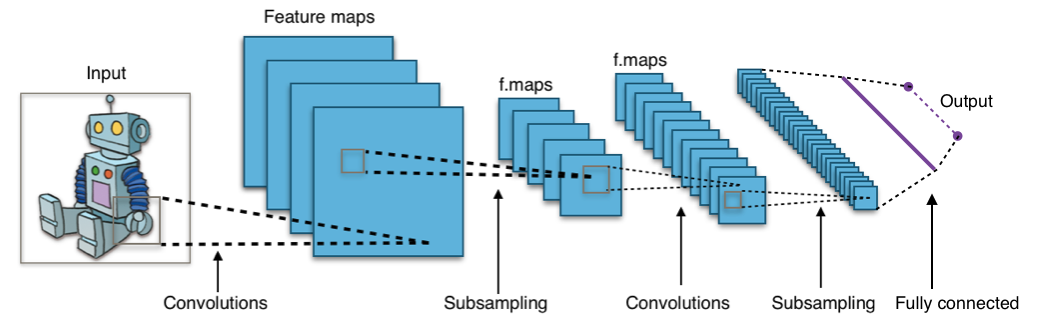
Les réseaux de neurones convolutionnels (CNN) sont fréquemment utilisés dans le domaine de la reconnaissance d'images. Pour en savoir plus sur ces techniques, ça se passe juste ici
Travaillant localement, j’étais limité par ma machine et ne voulait pas passer trop de temps à entraîner le modèle. Afin d’avoir une baseline, il est conseillé d’utiliser d’abord un modèle simple, quitte à passer à une architecture plus complexe dans un second temps. Dans le cadre de cet algorithme de classification binaire, opter pour la régression logistique s'est présenté comme une option pertinente.
La régression logistique ne pouvant pas gérer des matrices comme des images, il a fallu les convertir en listes. Enfin, les données de pression et d’images ont toutes été rassemblées avec les 0 et 1 et les listes en utilisant le nom des images comme clé de jointure.
Pour des raisons de limites matérielles, je n’ai pu utiliser que 120 images pour l’entraînement du modèle.
Pipe de données
Une fois mis en production, le script va récupérer des nouvelles images, appliquer le filtre de canny edge, convertir l’image en liste puis, selon la réponse du modèle, presser gauche ou droite en plus de presser pour accélérer.
Résultats & Limites
Les résultats obtenus avec le modèle par défaut de sci-kit learn se présentent comme suit :
Précision du modèle : 0,6785714285714286
- Cela indique la justesse globale des prédictions du modèle. Dans ce cas, le modèle est précis à environ 67,86 % du temps.
- Précision :
- La précision est le nombre de vrais positifs divisé par la somme des vrais positifs et des faux positifs. Elle mesure l'exactitude des prédictions positives, c'est-à-dire, la proportion des identifications positives qui étaient effectivement correctes.
- Précision pour la classe 0 : 0,86
- Précision pour la classe 1 : 0,62
- Interprétation :
- Pour la classe 0, 86 %, des instances prédites comme classe 0 étaient réellement de la classe 0.
- Pour la classe 1, 62 %, des instances prédites comme classe 1 étaient réellement de la classe 1.
- Rappel (Sensibilité ou Taux de vrais positifs) :
- Le rappel est le nombre de vrais positifs divisé par le nombre total de positifs réels. Il mesure la capacité du modèle à capturer les instances de la classe positive.
- Rappel pour la classe 0 : 0,43
- Rappel pour la classe 1 : 0,93
- Interprétation :
- Pour la classe 0, seulement 43 % des exemples réels de la classe 0 ont été correctement prédits.
- Pour la classe 1, le modèle capture 93 % des exemples de la classe 1.
- Score F1 :
- Le score F1 est la moyenne harmonique de la précision et du rappel. Il offre un équilibre entre la précision et le rappel.
- Score F1 pour la classe 0 : 0,57
- Score F1 pour la classe 1 : 0,74
- Interprétation :
- Le score F1 pour la classe 0 est relativement modéré, indiquant un équilibre entre la précision et le rappel.
- Le score F1 pour la classe 1 est plus élevé, suggérant un meilleur équilibre entre la précision et le rappel.
- Support :
- Le support est le nombre d'occurrences réelles de la classe dans l'ensemble de données spécifié.
- Support pour la classe 0 : 14
- Support pour la classe 1 : 14
- Moyenne Macro et Moyenne Pondérée :
- La moyenne macro calcule la moyenne non pondérée de la précision, du rappel et du score F1 entre les classes.
- La moyenne pondérée prend en compte le nombre d'instances pour chaque classe, accordant plus de poids aux classes plus grandes.
- Interprétation :
- Les valeurs de la moyenne macro et de la moyenne pondérée pour la précision, le rappel et le score F1 sont d'environ 0,74, indiquant une performance globale décente sur les deux classes.
Le modèle actuel ne généralise pas efficacement pour les virages à gauche, bien qu'il soit performant pour reconnaître les virages à droite. De plus, la méthode d'échantillonnage des données est assez lente : la fonctionnalité de capture d'écran ne prend qu'une photo par seconde, ce qui est insuffisant pour une réponse rapide du bot. Un modèle plus complexe, tel qu'un CNN, et un ensemble de données plus large pourraient vraisemblablement améliorer l'efficacité du modèle, en lui permettant d'extraire plus finement la complexité des images et d'accroître ainsi sa capacité à reconnaître les virages à droite.










{kind=link}