
Vous êtes déjà familier avec ChatGPT ?
Découvrez l'architecture RAG ou tout simplement les RAGs, “Retriever-Augmented Generation”, et comment apporter du contexte aux requêtes que vous adressez à votre LLM favori.
L'intérêt principal du RAG est qu’il permet au LLM, au coeur de l'architecture, de ne pas juste fabriquer des réponses à partir de ce qu’il a déjà en tête, mais de rechercher activement des informations pour enrichir ses réponses. C'est comme si vous aviez à votre disposition un assistant qui, non content de vous répondre avec son savoir déjà acquis, pouvait courir à la bibliothèque ou aller sur Google pour se renseigner afin de vous répondre avec les dernières informations les plus fiables.
Les LLMs, efficaces mais limités
Les LLMs (Large Language Models, ou modèles de langage de grande échelle) tels quel GPT, Gemini ou encore LLaMA, bien que constituant une véritable révolution dans le domaine du NLP (Natural Language Processing, ou traitement du langage naturel) et de l'IA Générative, présentent des limites.
La première limite découle du fonctionnement des LLMs. Ces modèles sont exceptionnellement doués pour créer du texte en désignant, au sein de leur vocabulaire, le prochain mot le plus plausible. C'est donc en se basant sur des probabilités et non des faits avérés qu'ils génèrent du contenu.
Bien sûr, si le texte à générer porte sur des éléments très connus et répandus dans leurs corpus d'entraînement (livres, site web, articles, ...), cette limite est moins évidente (si l'on donne comme entrée à un LLM "Quelle est la capitale de la France ?", la suite la plus plausible est le mot "Paris", bien que le modèle n'ait jamais appris la géographie).
Cette limite devient visible quand les éléments requis pour répondre à une requête deviennent très spécifiques ou précis, et donc sous-représentés voire totalement absent du corpus d'entraînement. Le modèle aura alors tendance à produire un résultat plausible mais faux, on parle alors d'hallucination.
(Note : Il est aussi possible qu'un LLM hallucine un résultat notamment pour une tâche complexe tel qu'un calcul arithmétique, mais ce problème s'éloigne du sujet des RAGs).
Les LLMs souffrent d'un second problème majeur : le manque de connaissances récentes. Ces modèles sont entraînés sur des ensembles de données fixes et ne reçoivent pas de mises à jour continues. Par conséquent, ils n'intègrent aucune informations ou événements survenus après leur période d'entraînement. Cela limite leur utilité dans des situations où une connaissance à jour est cruciale, comme pour les actualités récentes ou les avancées scientifiques.
Ré-entraîner continuellement ces modèles avec de nouvelles données pourrait théoriquement résoudre ce problème. Cependant, l'entraînement de LLMs nécessite une quantité considérable de puissance de calcul, ce qui le rend extrêmement coûteux. De plus, le processus d'entraînement peut demander beaucoup de temps, ce qui n'est pas idéal pour les applications nécessitant une réactivité rapide aux nouvelles informations.
Ainsi, bien que le ré-entraînement régulier puisse théoriquement garder un LLM à jour, les contraintes pratiques rendent cette solution difficile à mettre en œuvre.
Le RAG, une utilisation optimisée des LLMs
Comme nous venons de le voir, les LLMs, seuls, présentent des limites. L'architecture RAG, proposée par Lewis et al. dans l'article "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks", a pour but de diviser la création de réponse en deux étapes :
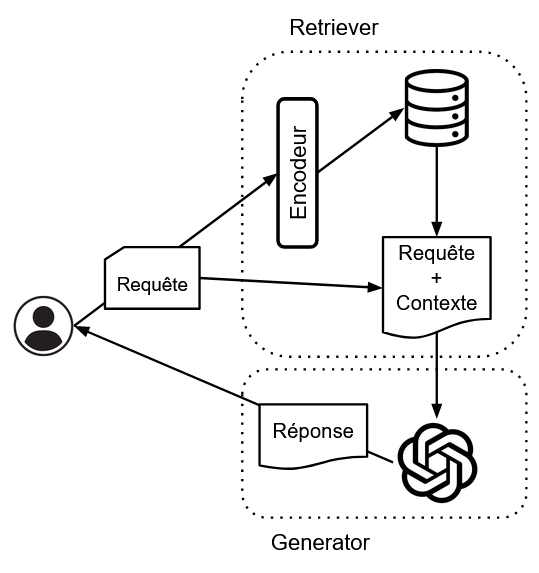
- Une recherche d'information pour agrémenter le prompt et apporter du contexte à la question de l'utilisateur. Ce composant du RAG est le "Retriever", que l'on peut traduire par "chien de chasse" ou "renifleur de bonnes infos".
- Une partie de création de la réponse, assurée par un LLM. Cette partie d'utilisation du contexte, construction et formulation de la réponse est la partie "Generator".
Comment fonctionnent ces deux parties ?
La partie "Retriever" de ce modèle joue un rôle crucial en sélectionnant les documents pertinents qui aideront à la génération de la réponse :
- Encodage de la question : La question posée par l'utilisateur est transformée en un vecteur à l'aide d'un modèle d'encodage. On parle alors de vectorisation, ou d'embedding. Ce modèle est généralement lui-même un LLM (de type BERT ou une variante de celui-ci), spécialisé dans la représentation numérique de texte.
L'intérêt de cette étape réside dans le fait que l'on peut effectuer des opérations mathématiques sur les vecteurs, notamment des évaluations de distances. Ainsi, il devient possible pour une machine d'évaluer à quel point les sens de deux textes sont proches. - Recherche de documents pertinents : Le vecteur de la question est utilisé pour rechercher, dans une base de données, des documents pré-encodés. En effet, dans la base, ces documents sont également représentés sous forme de texte auxquels sont associés comme clef leurs vecteurs, de la même manière que la question. Comme nous le disions précédemment, il est possible d'évaluer la similarité du sens de deux textes en calculant la distance entre leurs vecteurs associés. Les documents associés aux clefs (vecteurs) les plus similaires à la question sont sélectionnés. Le nombre de documents sélectionnés peut être fixé à l'avance (par exemple, les 5 ou 10 documents les plus pertinents).
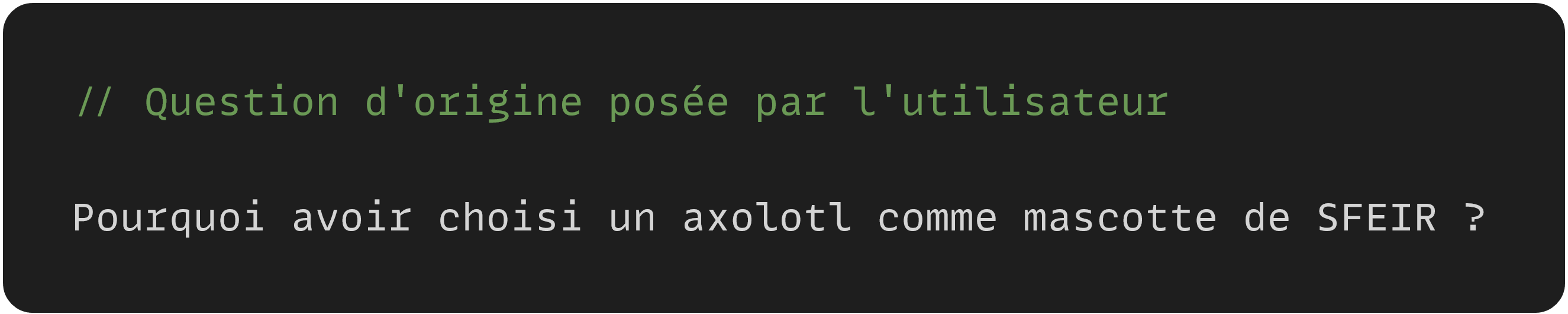
- Utilisation des documents : Une fois les documents pertinents récupérés, la question d'origine peut être "améliorée" en étant reformulée et enrichie d'un contexte pertinent. C'est ce prompt qui va être donné en entrée au LLM.
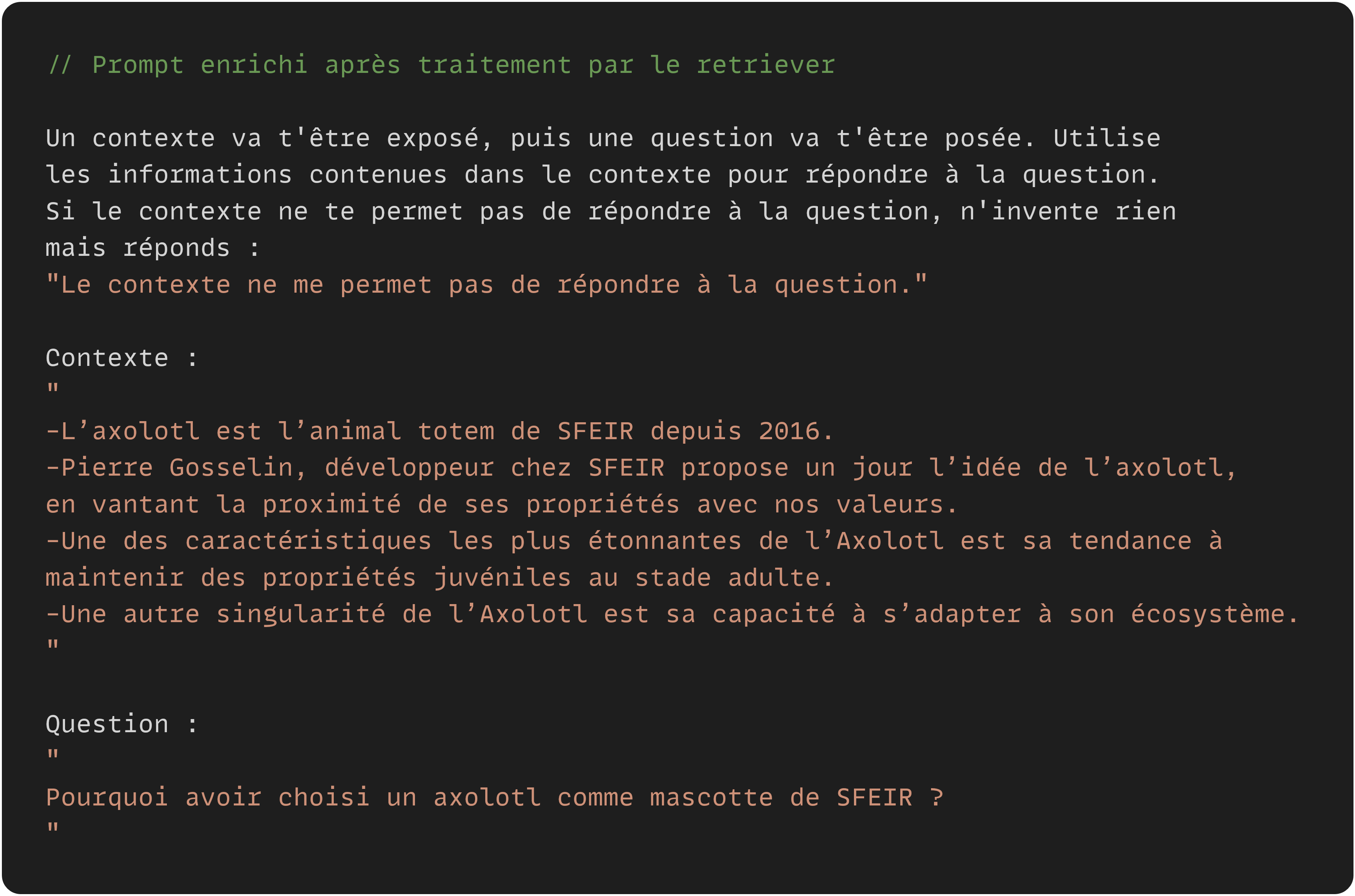
La partie "Generator" ingère la sortie du "Retriever" afin de la transmettre au LLM. Le LLM bénéficiera alors d'un prompt complet avec les informations nécessaires pour répondre à l'utilisateur. Le contexte va soit augmenter la plausibilité de la bonne réponse, soit simplement apporter des éléments qui étaient jusque là inconnus au modèle.
En plus d'apporter du contexte, l'enrichissement du prompt est l'occasion de rendre le LLM plus robuste à la génération d'hallucinations. En effet, il est possible d'apporter des instructions au LLM afin de permettre à celui-ci de répondre qu'il ne sait pas ou qu'il ne dispose pas des informations nécessaires car il est possible que les documents de la base de données ne suffisent pas à donner assez de contexte.
Une architecture polyvalente et évolutive
L'architecture RAG, telle qu'exposée ici, est la base constituant le socle de nombreuses applications. Il est possible d'ajouter des composants et autres plugins complémentaires afin de permettre au système de faire des recherches sur Internet, d'interpréter du code, d'exécuter des requêtes SQL, etc... Il existe même désormais des petits modèles de langage (SLMs, comme GPT-Neo ou Phi-2), pouvant exécuter des tâches au sein d'un RAG telles que la reformulation de la question, l'extraction de thèmes ou de mots clefs...
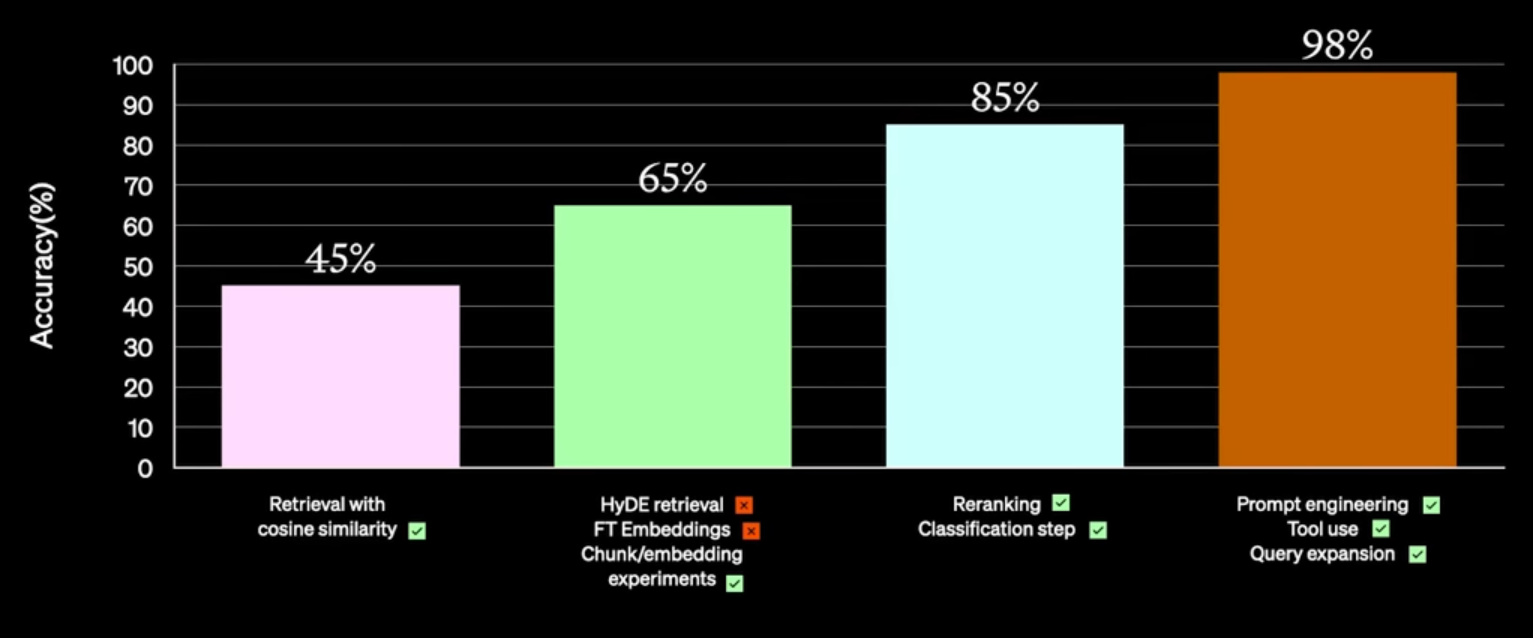
De nombreuses manières d'augmenter un RAG existent, et les projets basés sur cette architecture se prêtent particulièrement aux approches itératives, comme le montre OpenAI.
Les applications qui en découlent sont elles aussi très nombreuses. Parmi celles-ci, les chatbots conversationnels personnalisés, les systèmes de génération automatique de contenu, les outils d'analyse de texte avancés, les assistants virtuels, et bien d'autres (vous pouvez trouver des exemples de case studies sur le blog de Langchain).
Pour aller plus loin :
- Retrouvez nos articles sur les orchestrateurs permettant les échanges entre le Retriever, le Generator et l'utilisateur, et d'autres bibliothèques.
- Découvrez quels sont les risques liés à l'utilisation et au développement d'applications utilisant des LLMs.







{kind=link}