
Peut-être avez-vous déjà entendu le terme "fine-tuning" dans le contexte de l'utilisation des LLMs ou du traitement d'images. Le fine-tuning, au sens plus large, désigne le processus d'ajustement des paramètres d'un modèle de machine learning déjà entraîné, en particulier des réseaux de neurones artificiels, à une tâche spécifique. L'intérêt principal du fine-tuning est qu'il permet d'adapter un modèle généraliste à une tâche précise en le ré-entraînant totalement ou partiellement. De plus, ce ré-entraînement ne nécessite qu'une fraction des ressources qu'un développement complet "from scratch" nécessiterait (tant au niveau de la mise en place du jeu de données que de la puissance de calcul).
Les réseaux de neurones, puissants mais coûteux à entraîner
Afin de comprendre l'intérêt des modèles généralistes et du fine-tuning, nous allons nous intéresser brièvement aux réseaux de neurones artificiels (ou tout simplement "réseaux de neurones").
Bien que, dans les faits, les réseaux de neurones soient des enchaînements de fonctions, de sommes et de multiplications de matrices, il est utile de les formaliser en diagrammes afin d'avoir une bonne intuition de ce qui se déroule au sein de ces modèles. Nous pouvons les visualiser sous forme de couches de neurones artificiels, chaque couche consécutive étant interconnectée. Ce sont les poids associés à ces liaisons qui sont les paramètres du réseau, et ceux-ci sont initialisés aléatoirement lors de leur création. En suivant cette architecture, les réseaux de neurones sont capables d'apprendre n'importe quelle fonction, ce qui en fait des outils particulièrement puissants.
Note : les couches décrites sont des couches "denses" et constituent la base de l'architecture classique des réseaux de neurones artificiels. De nombreux autres mécanismes, types de neurones et manières d'agencer les couches existent et permettent notamment de réaliser des réseaux capables de traiter des images, du son, du texte, etc.
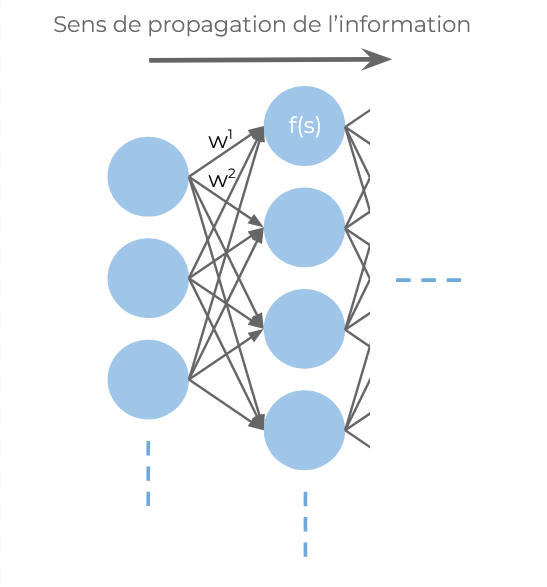
Cependant, plus le problème à traiter est complexe, plus le réseau doit avoir de couches et de neurones, et donc de poids. Bien que certaines tâches ne nécessitent que des réseaux de neurones de taille raisonnable (ou tout simplement d'autres modèles moins coûteux à entraîner), d'autres tâches nécessitent de très nombreux paramètres.
Les modèles généralistes, notamment, sont tous très volumineux, voire même complètement énormes (GPT4 comporte plus de 1,7 billion de paramètres !) Autre exemple, plus susceptible de tomber dans le cadre des use cases d'une entreprise, le nombre de paramètres d'un modèle réalisé from scratch pour faire de la détection d'image peut très facilement dépasser plusieurs dizaines de millions.
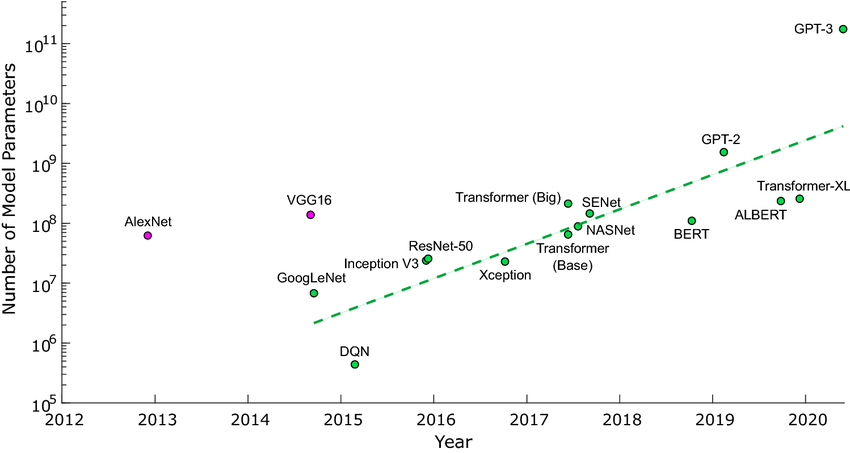
L'impact de la taille des réseaux sur leur entraînement
Comme tout modèle de machine learning (ML, ou apprentissage automatique), les réseaux de neurones nécessitent un entraînement, un "apprentissage", constitué de nombreuses itérations. Lors de chaque itération, l'algorithme d'apprentissage (la rétropropagation, ou backpropagation) expose le modèle à tout le jeu de données d'entraînement (on parle "d'epoch"). Le jeu de données d'entraînement est constitué d'exemples de tâches déjà réalisées (images déjà annotées, textes déjà traduits, etc., tout dépend de ce que vous souhaitez apprendre au modèle).
L'algorithme va alors calculer, pour chaque paramètre, l'influence de celui-ci sur l'erreur du réseau (c'est-à-dire l'écart entre la sortie produite et la sortie attendue) afin de savoir dans quel sens le modifier. Ainsi, les paramètres vont être ajustés petit à petit, jusqu'à ce que ceux-ci n'évoluent plus (on parle alors de convergence). Tout ce processus rend l'entraînement extrêmement coûteux, d'autant plus pour des modèles très grands nécessitant des jeux de données eux aussi massifs. Sam Altman, cofondateur d'OpenAI, a d'ailleurs estimé le coût d'entraînement de GPT-4 à plus de 100 millions de dollars !
Modèles généralistes et fine-tuning
Comme nous venons de le voir, les réseaux de neurones peuvent être très coûteux à entraîner selon la tâche à effectuer, sans compter le temps de mise en place du jeu de données d'entraînement qui, rappelons-le, est constitué de nombreux (milliers, voire millions) exemples de la tâche à réaliser.
Le fine-tuning et les modèles généralistes offrent une solution efficace pour répondre à une tâche en utilisant seulement une fraction du temps et du coût qu'un développement de modèle complet aurait nécessité.
Penchons nous sur les modèles généralistes
Un modèle généraliste est un modèle qui a été entraîné à répondre à de larges éventails de requêtes sans être spécialisé dans un domaine en particulier. Quelques exemples :
- YOLO est entraîné à détecter 80 classes différentes dans des images, c'est-à-dire à reconnaître et positionner 80 types d'éléments différents (de la personne humaine au camion en passant par la brosse à dents).
- Les modèles VGG, quant à eux, sont entraînés à faire de la classification d'images (donc moins complexe que de la détection), mais sur 1000 classes différentes.
- Whisper est entraîné à retranscrire et traduire l'audio venant de 99 langues différentes.
- GPT est capable de prendre en compte et de générer tout type de texte dans 95 langues différentes.
- ...
Ces modèles, ayant tous bénéficié d'un entraînement extrêmement long, constituent une base fantastique pour toute tâche de la même catégorie (détection d'image pour YOLO, classification pour VGG, génération de texte pour GPT...). En effet, il est tout à fait possible de ré-entraîner ces modèles en modifiant une nouvelle fois leurs poids. Seulement, cette fois ceux-ci ne sont pas initialisés au hasard : la tâche généraliste qu'ils permettent au modèle d'effectuer est bien plus proche des poids que le réseau doit atteindre afin d'effectuer la tâche plus précise.
Les différentes façons d'affiner un modèle
Le fine-tuning repose sur le principe de ré-entraînement, mais il existe divers moyens spécifiques d'y parvenir.
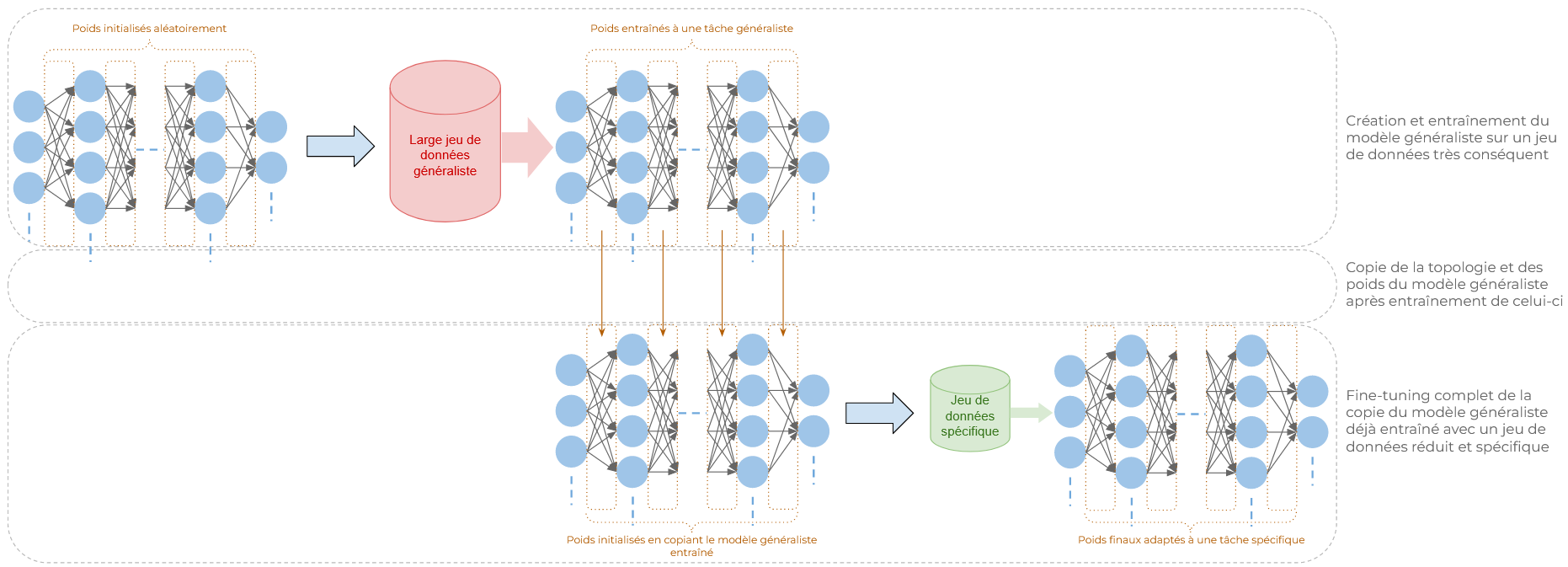
Fine-tuning complet
À utiliser lorsque les ensembles de données dont vous disposez sont assez grands et variés pour permettre un ajustement sans risquer que le modèle "n'apprenne par cœur" les données (on parle "d'overfitting" ou de surapprentissage). Avec ce type de fine-tuning, tous les paramètres sont ajustés.
Exemples :
- Les modèles de langage à grande échelle (LLMs) comme GPT ou BERT sont pré-entraînés sur de vastes corpus de texte. Les ré-entraîner sur des ensembles de données spécifiques les rendra meilleurs sur des tâches plus précises comme la classification de documents ou la génération de texte (spécifique soit au niveau du thème, comme le domaine juridique, soit au niveau du type de formulation, comme la génération de code).
- Nous pouvons aussi citer Whisper, destiné à la base à comprendre de nombreuses langues, qui a été fine-tuné pour être plus performant en français en utilisant le jeu de données Mozilla common voice.
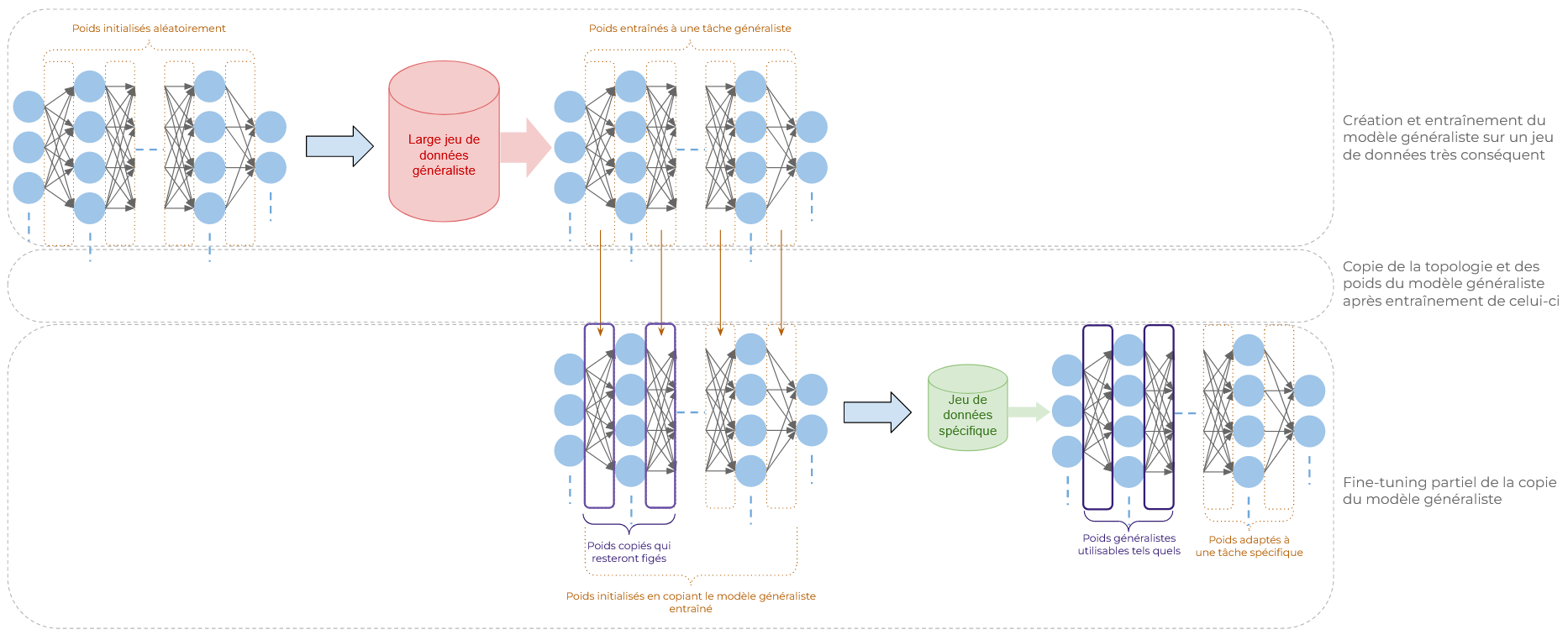
Fine-tuning partiel
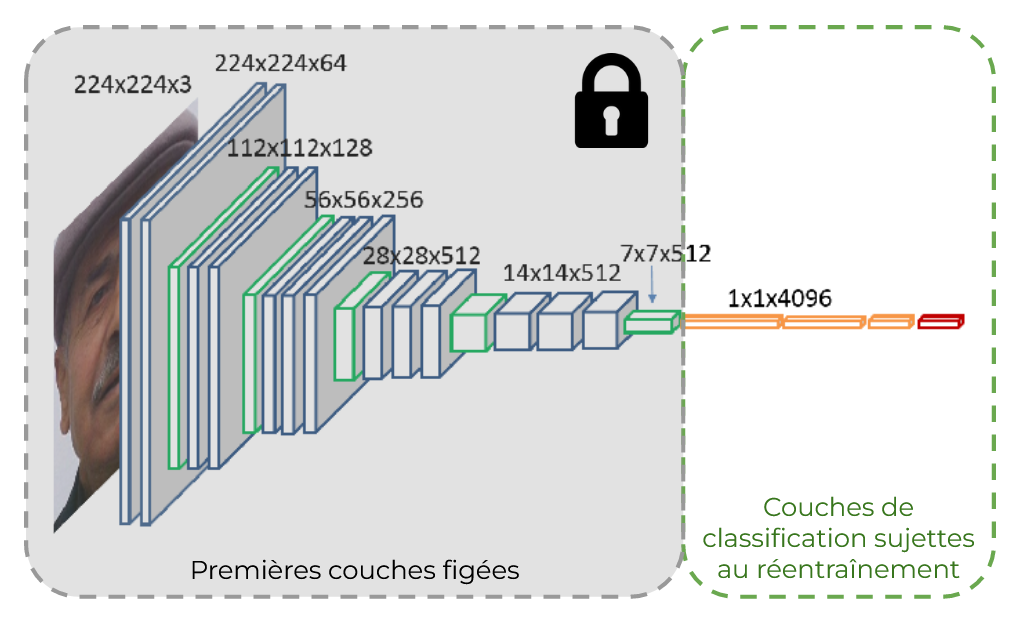
Le fine-tuning partiel se concentre sur l'ajustement de certaines couches ou de certains paramètres du modèle, laissant les autres inchangés. Cela est souvent fait en ne ré-entraînant que les dernières couches du modèle. En effet, ce sont les dernières couches qui sont les plus spécialisées, les plus adaptées à une tâche donnée. Les premières couches, elles, auront tendance à développer des capacités générales. Ce sont ces couches qui resteront figées (cette méthode rentre dans le domaine du Transfer learning).
Exemples :
- Les modèles de détection d'image, tel que YOLO, sont structurés en de nombreuses couches ayant leurs propres rôles. Ses premières couches, de convolution et de pooling, permettent au modèle de traiter des images en mimant la vision humaine. Ses dernières couches sont des couches denses (présentées précédemment) qui classifient et localisent les objets dans une image. Les premières couches apprennent généralement à reconnaître des caractéristiques "bas-niveau" (comme les bords, les textures, etc.) et les couches plus profondes extraient des caractéristiques de plus "haut niveau" (comme des formes ou des objets spécifiques). Ce sont ces couches plus profondes, ainsi que les couches denses qui suivent, qui sont ré-entraînées à la nouvelle tâche de détection. Les premières couches, ayant appris à "voir", restent inchangées. On peut citer comme cas d'utilisation la recherche de visages humains dans une image dans le but de les anonymiser.
Adaptation des têtes de classification
Dans cette approche, seule la tête de classification — les dernières couches denses — est fine-tunée, voire même coupée et remplacée (cette méthode rentre aussi dans le domaine du Transfer Learning). Les autres couches sont laissées intactes. Cette méthode est souvent employée lorsque le modèle de base est déjà performant pour reconnaître les caractéristiques pertinentes, mais doit être adapté à de nouvelles catégories ou classes (souvent moins nombreuses qu'à l'origine).
Exemple:
- Les modèles VGG, entraînés à la base à classifier une image parmi 1000 catégories, sont souvent utilisés comme base et voient leurs couches de classification remplacées par une autre couche bien plus petite, plus adaptée à la tâche de l'utilisateur. On peut citer comme cas d'utilisation la classification de sentiments sur les visages humains.
Les autres bénéfices du fine-tuning
Le fine-tuning ne permet pas seulement d'économiser du temps et de l'argent, un modèle fine-tuné bénéficie d'autres avantages :
- Performances accrues
Les modèles pré-entraînés ont été formés sur de vastes quantités de données pour des tâches générales et leurs architectures ont été largement éprouvées et testées. Affiner un modèle pré-entraîné conduit généralement à de meilleures performances que si un modèle spécifique avait été développé et entraîné. - Données
Dans de nombreux scénarios, obtenir des données et les annoter pour une tâche spécifique peut être difficile et prendre beaucoup de temps. Un autre bénéfice du fine-tuning est que la quantité de données nécessaire est bien moindre, comparée à un entraînement complet.







{kind=link}