
Imaginez ce scénario : votre agent IA vient d'être ouvert à vos utilisateurs. Des profils variés, des questions sensibles, des attentes élevées. Et là, quelqu'un vous demande : "Si l'agent répond n'importe quoi, vous le savez comment ?"
C'est une question simple, mais qui pointe un angle mort récurrent : on passe des semaines à construire l'architecture agentique, à affiner les prompts, à optimiser les outils — et presque rien à mettre en place un dispositif d'observation sérieux.
Dans cet article, je vous propose de corriger ça. On va voir ensemble pourquoi le monitoring classique ne suffit pas pour des systèmes agentiques, comment structurer une architecture observable dès le départ, et comment Langfuse nous permet de voir enfin ce qui se passe vraiment dans la tête d'un agent en production.
L'architecture : un orchestrateur, des agents, et un serveur LangGraph
Avant de parler monitoring, il faut comprendre ce qu'on monitore. L'objet central, c'est une architecture agentique : un agent orchestrateur qui coordonne des agents spécialisés. Ce type d'architecture peut s'intégrer dans une plateforme IA comme RAISE — la plateforme de SFEIR — qui sert alors de socle applicatif exposé aux utilisateurs. C'est l'intelligence agentique qui tourne à l'intérieur qu'on va instrumenter et observer.
Voici comment l'architecture est organisée :
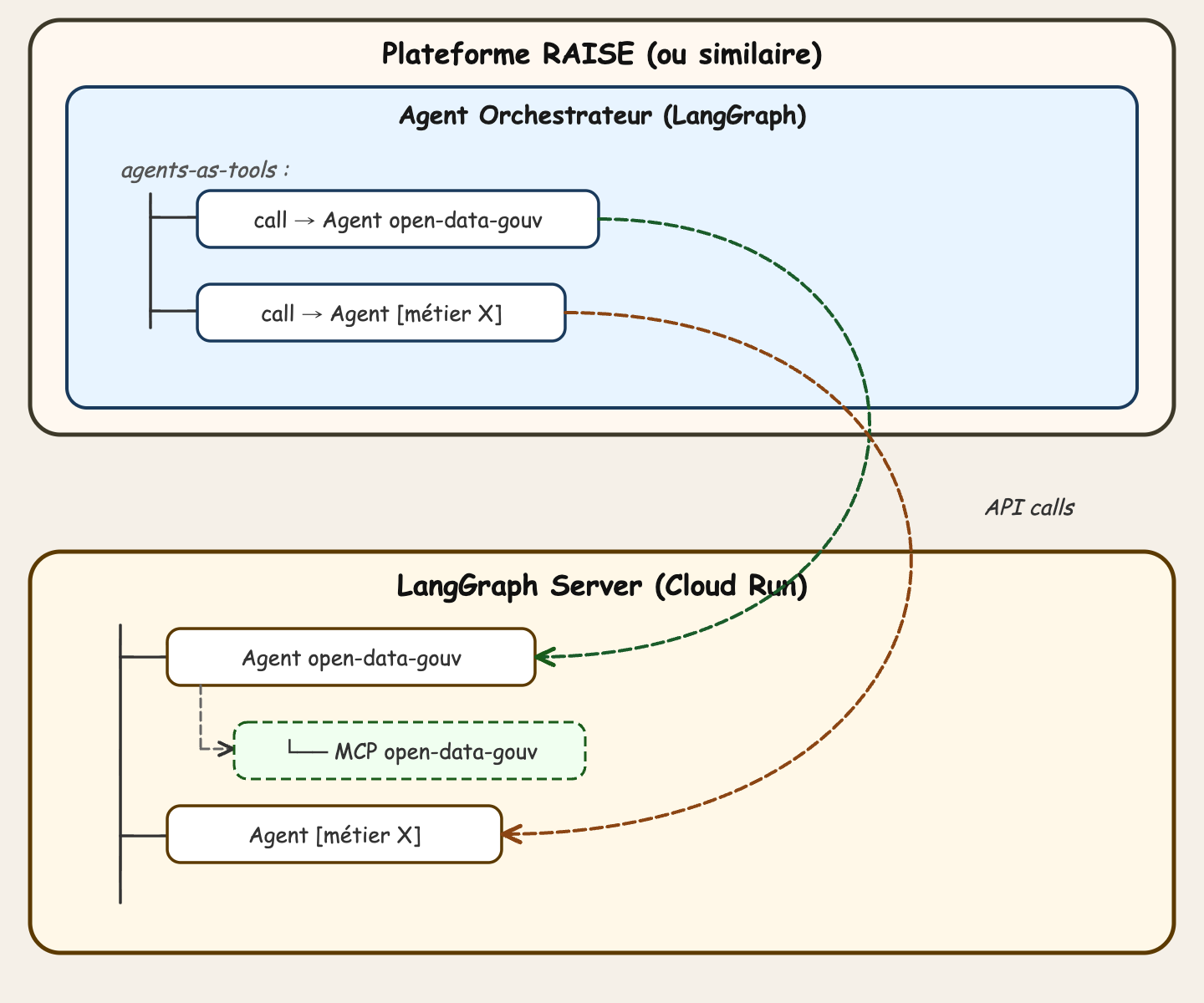
Ce pattern s'appelle agents-as-tools : l'orchestrateur ne code pas directement la logique des agents spécialisés. Il les appelle comme des outils. Ça permet une séparation des responsabilités claire — ajouter un nouvel agent revient simplement à enregistrer un nouvel outil auprès de l'orchestrateur.
Les agents spécialisés, eux, tournent tous dans un serveur LangGraph, déployé sur Cloud Run, qui expose l'ensemble des agents via une API consommée par l'orchestrateur.
Exemple concret : l'agent open-data-gouv. Il se connecte au serveur MCP open-data-gouv — un serveur Model Context Protocol rendu public récemment — qui lui permet d'interroger les données ouvertes du gouvernement français.
C'est propre. C'est modulaire. Et c'est exactement ce genre d'architecture qui devient un cauchemar à déboguer sans monitoring.
Pourquoi le monitoring classique ne suffit pas
Sur un service web classique, monitorer c'est relativement simple : latence, taux d'erreurs, throughput. Grafana + Prometheus et c'est plié.
Sur un système agentique, c'est une autre histoire.
Prenons le boucle ReAct (Reason → Act → Observe), qui est le cœur du fonctionnement de nos agents LangGraph :
Thought → Action (appel d'outil) → Observation → Thought → ...
Chaque itération de cette boucle est une décision prise par le modèle. Et ces décisions ne sont visibles nulle part dans vos logs applicatifs classiques. Ce que vous voyez en prod sans outillage spécifique :
- ✅ Latence totale de la requête
- ✅ Code HTTP de retour
- ❌ Pourquoi l'agent a choisi cet outil plutôt qu'un autre
- ❌ Combien d'itérations ReAct il a effectuées avant de répondre
- ❌ Est-ce que la réponse est pertinente par rapport à la question posée
- ❌ Combien de tokens ont été consommés, et à quel coût
- ❌ L'agent a-t-il halluciné sur un outil qui n'existait pas ?
En résumé : avec du monitoring classique, vous savez que votre agent a répondu. Vous ne savez pas s'il a bien raisonné.
Langfuse : le choix de la maîtrise des données
Quand on travaille avec LangChain et LangGraph, le premier réflexe naturel est de se tourner vers LangSmith. c'est la solution officielle de l'écosystème, bien intégrée, bien documentée. Mais cette option a un coût caché : elle nécessite une LangSmith License Key, obtenue uniquement via l'équipe commerciale de LangChain. Et surtout, même en self-hosting, LangSmith exige un egress vers https://beacon.langchain.com pour la vérification de licence et le reporting d'usage — sans quoi la plateforme ne fonctionne tout simplement pas.
Dans un contexte de plateforme IA maîtrisée — où tout flux de données sortant est soumis à validation — cette contrainte d'egress obligatoire est souvent un deal-breaker.
Langfuse est open-source, auto-hébergeable, et s'intègre nativement avec LangChain et LangGraph. On l'a déployé dans notre infrastructure GCP, aux côtés de notre stack Cloud Run. Toutes les traces restent dans notre périmètre. Zéro donnée qui sort.
L'intégration dans notre code LangGraph se fait via un callback handler :
from langfuse.callback import CallbackHandler
langfuse_handler = CallbackHandler(
public_key="...",
secret_key="...",
host="https://langfuse.notre-infra.com" # self-hosted
)
# Injection dans l'invocation de l'agent
result = agent.invoke(
{"messages": [HumanMessage(content=user_query)]},
config={"callbacks": [langfuse_handler]}
)
Et c'est tout. À partir de là, chaque appel est tracé automatiquement.
Ce qu'on observe concrètement
Les traces : voir le fil complet d'une requête
Une trace Langfuse correspond à l'exécution complète d'une requête — de la question de l'utilisateur jusqu'à la réponse finale. Elle contient tous les spans imbriqués : l'appel à l'orchestrateur, les tool calls, les appels aux agents spécialisés, et les réponses de chaque étape.
Exemple concret : un utilisateur pose la question "Recherche les informations sur la CCN 3248". Voici ce que Langfuse capture :
TRACE: open_data_gouv — 58.67s | $0.010174 | 19 538 tokens prompt → 396 completion
├── agent (iter 1)
│ └── tools → search_datasets(query: "CCN 3248")
│ └── "No datasets found for query: 'CCN 3248'"
│
├── agent (iter 2) ← l'agent reformule
│ └── tools → search_datasets(query: "convention collective")
│ └── Found 3 datasets :
│ - KALI : Conventions collectives nationales
│ - ...
│
├── agent (iter 3 → 7)
│ └── tools → list_dataset_resources / query_resource_data / ...
│
└── Réponse finale généréeEn 7 itérations, l'agent a compris que "CCN 3248" ne donnait rien directement, a reformulé sa requête vers "convention collective", trouvé les bons datasets, puis les a interrogés pour construire sa réponse. Tout ça est visible, rejouable, et auditable dans Langfuse.
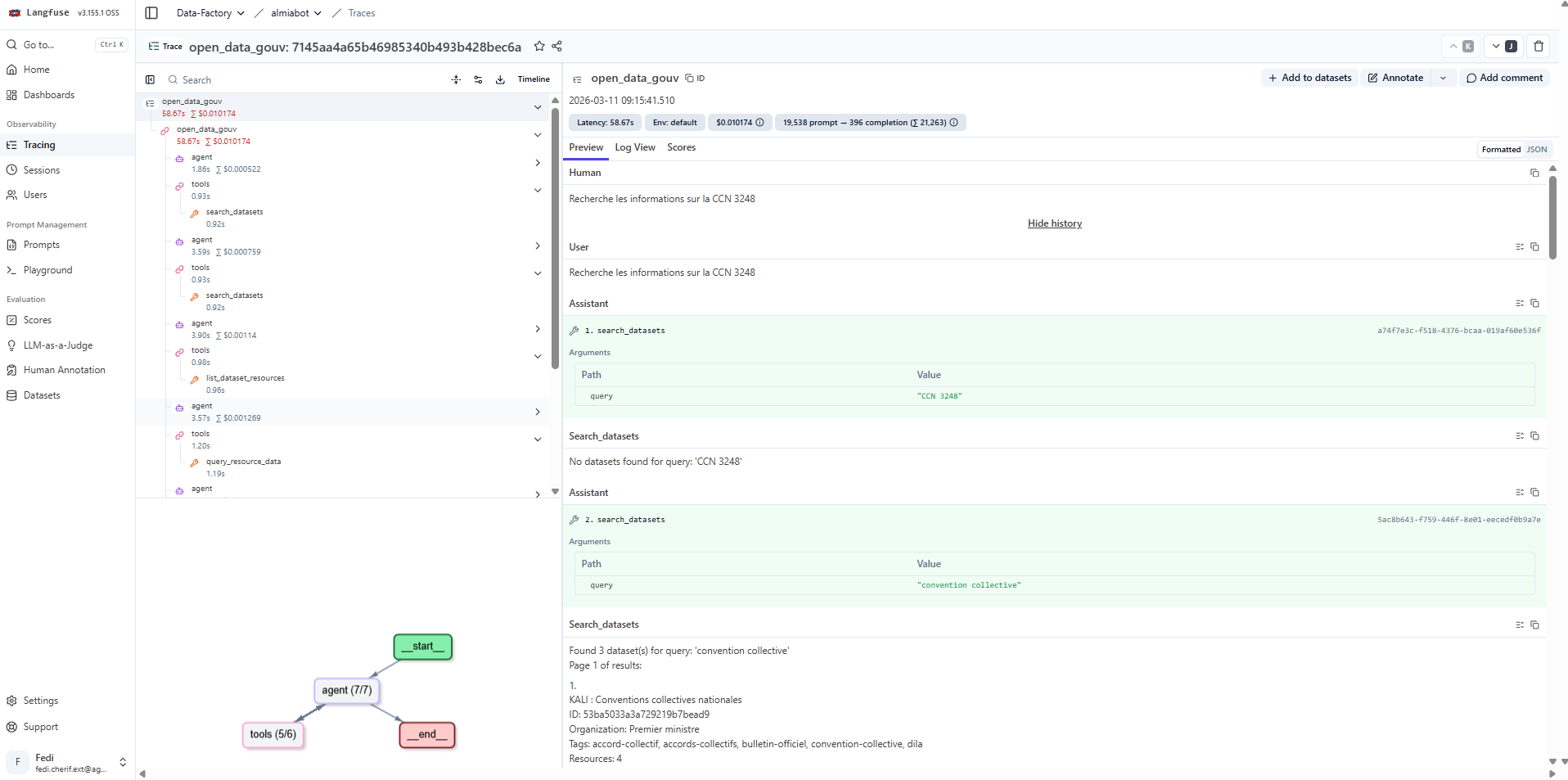
Ce niveau de granularité est impossible à obtenir avec des logs classiques. C'est la différence entre voir que votre agent a répondu, et comprendre comment il y est arrivé.
L'évaluation automatique : LLM-as-a-judge
Langfuse permet de brancher des évaluateurs automatiques sur vos traces. Concrètement, on configure un LLM (par exemple un modèle hébergé sur Vertex AI) qui va noter chaque réponse selon des critères définis.
Voici trois scorers particulièrement pertinents à mettre en place sur ce type de système :
- Relevance : la réponse répond-elle à la question ?
- Groundedness : la réponse est-elle ancrée dans les documents sources (pour les réponses RAG) ?
- Tool appropriateness : l'agent a-t-il choisi le bon outil pour la bonne question ?
Le suivi des coûts et de la latence par agent
Langfuse agrège automatiquement la consommation de tokens et les latences, par agent, par type de requête, par période. Le dashboard intégré permet de suivre en temps réel :
- Coût moyen par conversation, par agent
- Latence P95 de chaque étape du pipeline (le temps de réponse en dessous duquel se situent 95% des requêtes — plus révélateur que la moyenne)
- Taux d'erreurs par type d'outil appelé
- Volume de requêtes par tranche horaire (pour anticiper les pics)
La checklist avant de passer en prod
Voici les 6 questions auxquelles vous devez pouvoir répondre grâce à votre dispositif de monitoring, avant d'ouvrir un agent à large échelle :
1. Mon agent termine-t-il ses requêtes sans boucler ?
Vérifiez que le nombre moyen d'itérations ReAct est borné et raisonnable. Un agent qui boucle consomme des tokens et dégrade l'expérience.
2. Le bon outil est-il sélectionné pour le bon type de question ?
Analysez les traces par catégorie de question et vérifiez que le tool routing est cohérent.
3. Quelle est ma latence P95 sur l'ensemble du pipeline ?
La somme des latences de chaque agent worker peut surprendre. Mesurez-la de bout en bout, pas agent par agent.
4. Quel est mon coût moyen par conversation ?
Sur un volume important d'utilisateurs, même un coût de quelques centimes par échange peut représenter des milliers d'euros par mois. À modéliser avant de scaler.
5. Mes réponses sont-elles ancrées dans les données sources ?
Surtout pour un système RAG : une réponse fluide et fausse est pire qu'une réponse honnêtement incomplète.
6. Est-ce que je peux reproduire un bug signalé par un utilisateur ?
Si un collaborateur remonte une mauvaise réponse, vous devez pouvoir retrouver la trace exacte de cette requête, avec tout le contexte de raisonnement.
Si vous pouvez répondre à ces 6 questions, vous êtes prêt.
Conclusion : monitorer, c'est comprendre
Mettre un agent en production sans monitoring, c'est ouvrir une boîte noire à vos utilisateurs. Vous savez qu'il répond. Vous ne savez pas s'il raisonne bien.
Langfuse transforme votre capacité à comprendre, évaluer et améliorer des agents — le tout en restant dans le périmètre de souveraineté de votre organisation. C'est un outil que je recommande sans hésitation à tout projet GenAI sérieux, qu'il soit en phase de prototypage ou en production à large échelle.
Monitorer un agent, ce n'est pas le surveiller. C'est le comprendre. Et un agent qu'on comprend, c'est un agent dont on peut garantir la qualité.






{kind=link}