
Dans un monde où les utilisateurs exigent des recherches rapides et pertinentes, Elasticsearch se distingue comme une solution de choix pour la recherche full-text et l’analyse de données. Associé à Spring Boot, il permet de créer des applications performantes avec une intégration fluide.
Présentation d’Elasticsearch
Elasticsearch est un moteur de recherche et d’analyse open-source, basé sur Apache Lucene, conçu pour traiter de gros volumes de données avec une faible latence. Il excelle dans les recherches full-text, les agrégations, et les analyses complexes, grâce à une architecture distribuée qui facilite la scalabilité. Contrairement aux bases de données relationnelles classiques (MySQL, PostgreSQL), Elasticsearch stocke les données sous forme de documents JSON dans des index, avec une structure flexible et configurable via des mappings.
Avec Spring Boot, l’intégration se fait via Spring Data Elasticsearch, qui offre une abstraction similaire à Spring Data JPA. Les repositories et annotations simplifient la gestion des index, permettant aux développeurs de se concentrer sur la logique métier tout en exploitant la puissance d’Elasticsearch.

Configuration
Pour commencer, nous avons besoin d'ajouter la dépendance Spring Data Elasticsearch à notre projet.
Dépendances Maven
Voici la dépendance nécessaire dans le fichier pom.xml :
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>Configuration de la Connexion
Ensuite, nous devons configurer la connexion à notre instance Elasticsearch dans le fichier src/main/resources/application.properties :
spring.elasticsearch.uris=http://localhost:9200
spring.elasticsearch.username=elastic
spring.elasticsearch.password=changeme
spring.elasticsearch.ssl.verification-mode=noneActivation des Repositories
Enfin, nous activons les repositories Elasticsearch dans notre classe principale avec l'annotation @EnableElasticsearchRepositories.
@SpringBootApplication
@EnableElasticsearchRepositories
public class ElasticSearchApplication {
public static void main(String[] args) {
SpringApplication.run(ElasticSearchApplication.class, args);
}
}Modèle de Données (Document)
Nous allons créer un modèle Book qui représente un document dans notre index Elasticsearch.
L'annotation @Document(indexName = "books") indique que cette classe est mappée à un index nommé books. L'annotation @Mapping permet de spécifier un fichier de mapping pour définir la structure de l'index.
@Document(indexName = "books")
@Mapping(mappingPath = "/elasticsearch/mappings/books.json")
public class Book {
@Id
private String id;
@NotNull
@Field(type = FieldType.Text, analyzer = "standard")
private String title;
@Field(type = FieldType.Text, analyzer = "standard")
private String content;
@NotNull
@Field(type = FieldType.Keyword)
private String author;
// Getters et Setters...
}Le fichier de mapping src/main/resources/elasticsearch/mappings/books.json définit les types des champs dans l'index :
{
"properties": {
"id": { "type": "keyword" },
"title": { "type": "text", "analyzer": "standard" },
"content": { "type": "text", "analyzer": "standard" },
"author": { "type": "keyword" }
}
}Repository
Spring Data Elasticsearch simplifie grandement l'accès aux données. Il suffit de créer une interface qui étend ElasticsearchRepository. Spring Data se charge de l'implémentation.
Nous pouvons y définir des méthodes de recherche personnalisées. Spring Data déduit la requête à partir du nom de la méthode.
public interface BookRepository extends ElasticsearchRepository<Book, String> {
List<Book> findByTitleContainingOrContentContaining(String title, String content);
List<Book> findByAuthor(String author);
}Service Métier
Le service contient la logique métier de notre application. Il utilise le BookRepository pour interagir avec Elasticsearch.
@Service
public class BookService {
private final BookRepository bookRepository;
public BookService(BookRepository bookRepository) {
this.bookRepository = bookRepository;
}
public Book saveBook(Book book) {
return bookRepository.save(book);
}
public List<Book> searchBooks(String query) {
return bookRepository.findByTitleContainingOrContentContaining(query, query);
}
public void deleteBook(String id) {
bookRepository.deleteById(id);
}
}Contrôleur REST
Pour finir, nous exposons notre fonctionnalité via une API REST. Le BookController gère les requêtes HTTP et utilise le BookService pour effectuer les opérations.
@RestController
@RequestMapping("/api/books")
public class BookController {
private final BookService bookService;
public BookController(BookService bookService) {
this.bookService = bookService;
}
@PostMapping
public Book createBook(@RequestBody Book book) {
return bookService.saveBook(book);
}
@GetMapping("/search")
public List<Book> searchBooks(@RequestParam String query) {
return bookService.searchBooks(query);
}
@DeleteMapping("/{id}")
public void deleteBooks(@PathVariable String id) {
bookService.deleteBook(id);
}
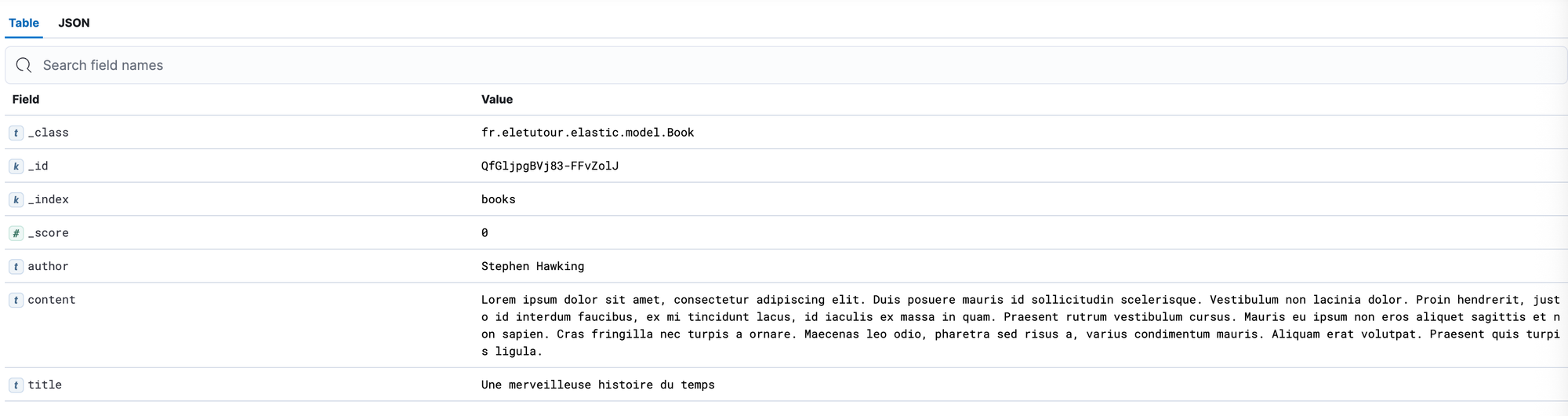
}Via une requête sur notre endpoint de création nous pouvons créer un premier document :
{
"title":"Une merveilleuse histoire du temps",
"content":"Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis posuere mauris id sollicitudin scelerisque. Vestibulum non lacinia dolor. Proin hendrerit, justo id interdum faucibus, ex mi tincidunt lacus, id iaculis ex massa in quam. Praesent rutrum vestibulum cursus. Mauris eu ipsum non eros aliquet sagittis et non sapien. Cras fringilla nec turpis a ornare. Maecenas leo odio, pharetra sed risus a, varius condimentum mauris. Aliquam erat volutpat. Praesent quis turpis ligula.",
"author":"Stephen Hawking"
}Ensuite via un outils de visualisation de document tel que Kibana, nous pouvons nous connecter à notre instance d'Elasticsearch et voir le document ainsi sauvegardé.
Ici, nous avons posé les bases avec un exemple volontairement épuré. Mais la véritable puissance d’Elasticsearch se révèle lorsqu’il s’intègre dans la stack ELK complète.
Dans la suite, nous passerons à la vitesse supérieure : ingestion de données à grande échelle avec Logstash, indexation millimétrée dans Elasticsearch, et visualisation en temps réel grâce à Kibana.
Un voyage au cœur de l’analyse de données vous attend.
Quel est le gain par rapport à un repository classique comme JPA ?
Si Spring Data JPA et Spring Data Elasticsearch partagent une philosophie commune — un accès simplifié aux données via des repositories — ils servent des objectifs bien différents.
- Type de recherche :
- JPA excelle dans les requêtes relationnelles, les jointures et la manipulation de données strictement structurées.
- Elasticsearch brille dans la recherche full-text, la tolérance aux fautes de frappe, la pondération des résultats (scoring) et les agrégations complexes.
- Performance en recherche :
Les bases relationnelles peuvent effectuer des recherches textuelles, mais dès que le volume ou la complexité des requêtes augmente (recherche floue, synonymes, tri par pertinence…), elles deviennent moins efficaces. Elasticsearch, pensé dès l’origine pour indexer et rechercher rapidement de grands volumes de texte, garde une latence faible même à grande échelle. - Flexibilité du schéma :
Les entités JPA nécessitent un schéma de base de données fixe. Elasticsearch, lui, adopte un stockage JSON flexible (mapping dynamique ou défini), facilitant l’évolution des données sans migration complexe.
Conclusion
Associer Spring Boot et Elasticsearch, c’est unir la stabilité d’un framework Java mature à la puissance et à la souplesse d’un moteur de recherche distribué.
Là où JPA assure la cohérence et la gestion relationnelle des données, Elasticsearch apporte vitesse, pertinence et flexibilité dans la recherche, même sur de très gros volumes.
Cette combinaison illustre un principe fondateur de l’informatique : s’appuyer sur des outils éprouvés, chacun dans son domaine d’excellence, pour créer des systèmes performants et évolutifs. En somme, on ne réinvente pas la roue : on la propulse avec un moteur taillé pour la vitesse et la précision.
Tout le code présent dans cet article est trouvable ici si jamais vous souhaitez approfondir le sujet





){kind=link}