
La salle est pleine depuis midi. Les aventuriers ont bu, mangé, commandé des tournées entières de Dragon Stout et d'Elven IPA. Derrière le comptoir, le tavernier a encaissé les coups, servi ce qu'il pouvait, noté les ruptures de stock sur un bout de parchemin.
Puis la dernière bougie s'éteint. Les clients partent. La porte se referme.
C'est là que commence l'autre partie du travail, celle qui n'a pas de public, pas d'urgence, mais qui conditionne tout ce qui se passera le lendemain. Le brasseur descend à la cave. Il consulte le parchemin. Il brasse exactement ce qui a manqué.
Dans cet article, on va suivre cette nuit de bout en bout, et traduire chaque geste du brasseur en code Quarkus Batch.
Pourquoi un traitement batch ?
La question mérite d'être posée. La taverne a déjà une API REST qui fonctionne. Elle sert les commandes en temps réel, retourne des rapports, expose ses stocks. Pourquoi ne pas brasser en continu, dès qu'une bière est consommée ?
Parce que brasser une bière, ça prend du temps. Et surtout, ça mobilise des ressources. Si le brasseur descend à la cave à chaque pinte servie, il n'est plus jamais en salle. La taverne s'effondre.
Le traitement batch résout ce problème en séparant deux rythmes : le rythme de la demande (continu, imprévisible, rapide) et le rythme de la production (planifié, massif, décalé).
C'est un patron classique dans les systèmes qui gèrent des flux importants : rapprochements bancaires la nuit, génération de rapports en fin de journée, synchronisation de catalogues produits.
Dans Quarkus, ce patron est supporté nativement via Jakarta Batch et son implémentation de référence JBeret.
L'anatomie d'un job batch
Avant d'écrire du code, il faut comprendre comment Jakarta Batch structure le travail.
Un job est l'unité de haut niveau. C'est la nuit de brassage entière. Il est décrit dans un fichier XML : le plan de travail que le brasseur consulte avant de descendre à la cave.
À l'intérieur d'un job, on trouve des steps. Un step est une étape atomique. Dans un traitement simple, il n'y en a qu'un. Dans un traitement plus complexe (nettoyer les cuves, brasser, étiqueter les tonneaux), il peut y en avoir plusieurs, exécutés en séquence.
Chaque step peut prendre deux formes :
- Un Batchlet : une tâche indivisible, tout ou rien. Le brasseur descend à la cave, brasse tout, remonte. Pas de découpage possible.
- Un Chunk : un traitement par lots, avec lecture, transformation et écriture de N éléments à la fois. Utile quand le volume est trop grand pour tenir en mémoire.
Pour notre taverne, le brassage nocturne est une tâche simple et atomique : on calcule ce qui a été consommé, on remet les stocks à niveau. Un Batchlet suffit.
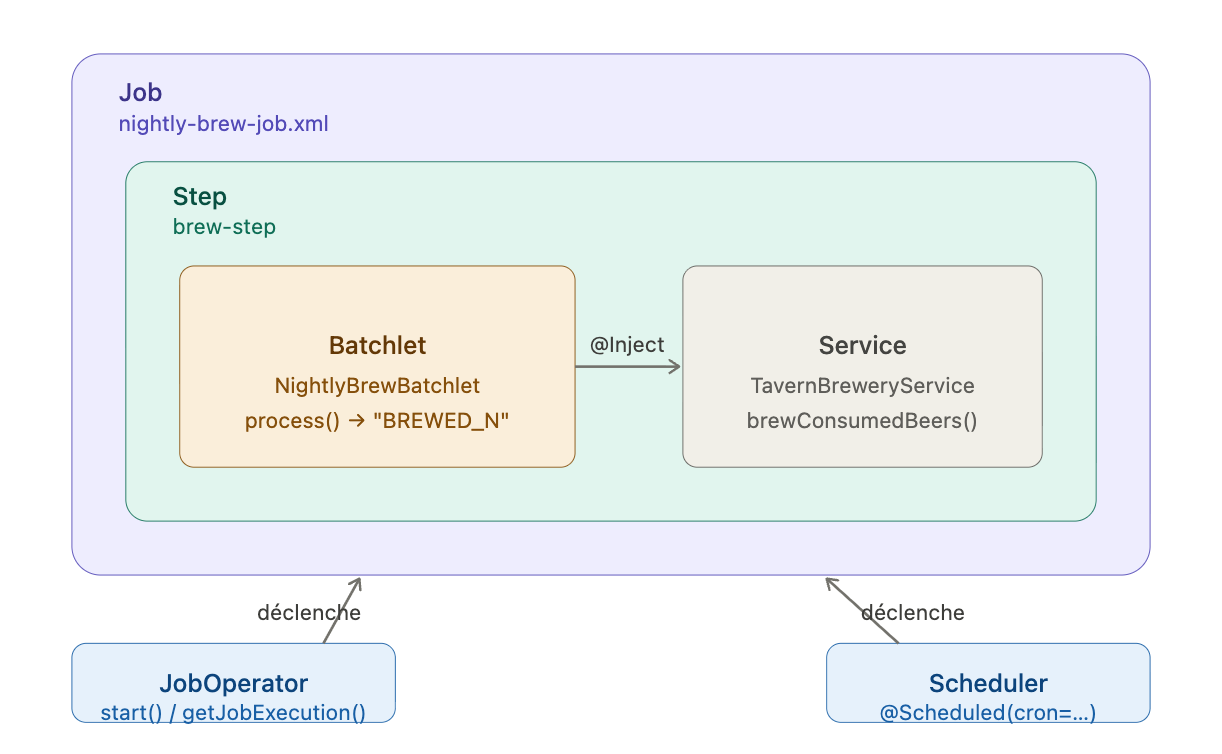
Le parchemin de recettes : le fichier XML du job
Jakarta Batch exige un fichier de définition de job au format XML, placé dans src/main/resources/META-INF/batch-jobs/.
<!-- src/main/resources/META-INF/batch-jobs/nightly-brew-job.xml -->
<job id="nightly-brew-job" xmlns="https://jakarta.ee/xml/ns/jakartaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/jakartaee
https://jakarta.ee/xml/ns/jakartaee/jobXML_2_0.xsd"
version="2.0">
<step id="brew-step">
<batchlet ref="nightlyBrewBatchlet"/>
</step>
</job>
Définition de notre job
Le nom du fichier XML — nightly-brew-job : est l'identifiant du job.
C'est ce nom qu'on passe au JobOperator pour démarrer l'exécution. L'attribut ref du batchlet pointe vers le nom CDI du composant qui fera le travail.
Ce fichier est la carte de la nuit. Il dit : "pour ce job, il y a une étape, et cette étape est confiée à nightlyBrewBatchlet."
Le brasseur : le Batchlet
Le Batchlet est la pièce centrale. C'est lui qui fait le travail. Il implémente AbstractBatchlet et surcharge une seule méthode : process().
@Named("nightlyBrewBatchlet")
public class NightlyBrewBatchlet extends AbstractBatchlet {
private static final Logger LOG = Logger.getLogger(NightlyBrewBatchlet.class);
@Inject
TavernBreweryService tavernBreweryService;
@Override
public String process() {
LOG.info("Nightly brew batchlet started");
int brewed = tavernBreweryService.brewConsumedBeers();
LOG.infov("Nightly brew batchlet finished with brewed={0}", brewed);
return "BREWED_" + brewed;
}
}
Le batchlet
Quelques points à noter :
L'annotation @Named("nightlyBrewBatchlet") est celle que le fichier XML référence dans ref. Le nom doit correspondre exactement : c'est le contrat entre le plan de travail et l'exécutant.
L'injection CDI fonctionne normalement : @Inject TavernBreweryService est disponible, comme dans n'importe quel bean Quarkus.
C'est l'un des avantages de l'intégration Quarkus/JBeret : le cycle de vie CDI est pleinement respecté dans les composants batch.
La valeur de retour de process() est une chaîne libre. Elle représente le statut de sortie du step, et peut être utilisée pour brancher l'exécution vers un step suivant (dans un job multi-étapes).
Ici, elle sert uniquement à tracer le volume brassé dans les logs du runtime batch.
Le travail de la nuit : TavernBreweryService
Le Batchlet délègue la logique métier au service. C'est une bonne séparation : le Batchlet orchestre, le service connaît les règles.
public synchronized int brewConsumedBeers() {
EnumMap<BeerStyle, Integer> brewedByStyle = new EnumMap<>(BeerStyle.class);
int totalBrewed = 0;
for (BeerStyle style : BeerStyle.values()) {
int consumedToday = consumedTodayByStyle.get(style);
int brewedTonight = consumedToday;
stockByStyle.put(style, stockByStyle.get(style) + brewedTonight);
consumedTodayByStyle.put(style, 0);
brewedByStyle.put(style, brewedTonight);
totalBrewed += brewedTonight;
}
lastBrewedByStyle = brewedByStyle;
return totalBrewed;
}
La règle est simple : on brasse exactement ce qui a été consommé dans la journée. Le stock est remis à niveau, le compteur de consommation journalière est remis à zéro. La taverne repart à niveau pour le lendemain.
Le mot-clé synchronized mérite attention. Le service est un bean @ApplicationScoped — une instance unique partagée entre tous les threads. Le batch tourne dans son propre thread, mais le endpoint REST /stocks peut être appelé en même temps. Sans synchronisation, une lecture partielle de l'état serait possible. Ici, chaque méthode qui accède aux maps est synchronisée : le brasseur ferme la cave à clé le temps qu'il travaille.
Deux façons de réveiller le brasseur
La nuit de brassage peut être déclenchée de deux manières dans l'application.
À la demande : l'endpoint REST
Pour les tests, les démonstrations, ou les cas où on veut rejouer un scénario, un endpoint REST permet de lancer le job manuellement.
@POST
@Path("/nightly-batches")
public Response runNightlyBatch() {
long executionId = jobOperator.start(NIGHTLY_JOB_NAME, new Properties());
JobExecution execution = waitForCompletion(executionId);
NightlyBatchResult result = new NightlyBatchResult(
executionId,
NIGHTLY_JOB_NAME,
execution.getBatchStatus().name(),
tavernBreweryService.getLastBrewedByStyle().values().stream()
.mapToInt(Integer::intValue).sum(),
tavernBreweryService.getLastBrewedByStyle()
);
return Response.status(Response.Status.CREATED).entity(result).build();
}
JobOperator est l'interface standard pour piloter les jobs. start() prend le nom du job (celui du fichier XML) et des propriétés optionnelles.
Il retourne un executionId : l'identifiant unique de cette exécution particulière.
Le job s'exécute de manière asynchrone. Pour rendre l'endpoint synchrone — attendre la fin du brassage avant de répondre, on boucle sur le statut de l'exécution :
private JobExecution waitForCompletion(long executionId) {
JobExecution execution = jobOperator.getJobExecution(executionId);
int maxWaitCycles = 120;
while (execution != null
&& isRunning(execution.getBatchStatus())
&& maxWaitCycles-- > 0) {
Thread.sleep(50);
execution = jobOperator.getJobExecution(executionId);
}
if (isRunning(execution.getBatchStatus())) {
throw new IllegalStateException(
"Nightly batch still running after timeout: " + executionId);
}
return execution;
}
private boolean isRunning(BatchStatus status) {
return status == BatchStatus.STARTED
|| status == BatchStatus.STARTING
|| status == BatchStatus.STOPPING;
}
C'est un polling actif avec timeout, 120 cycles de 50ms, soit 6 secondes au maximum. Simple et efficace pour une démo ou un contexte peu concurrent. Dans un système de production sous forte charge, on préférerait un callback ou un endpoint asynchrone.
Automatiquement : le scheduler
Pour que le brassage se déclenche vraiment chaque nuit, sans intervention humaine, on utilise @Scheduled de Quarkus :
@ApplicationScoped
public class NightlyBrewScheduler {
@Inject
JobOperator jobOperator;
@Scheduled(cron = "{tavern.brewery.nightly-cron}")
void brewAtNight() {
long executionId = jobOperator.start(JOB_NAME, new Properties());
LOG.infov("Nightly brew job launched with executionId={0}", executionId);
}
}
Le scheduler
L'expression cron est externalisée dans la configuration via {tavern.brewery.nightly-cron}. Dans application.properties :
tavern.brewery.nightly-cron=0 0 2 * * ?
Cela signifie : tous les jours à 2h du matin. Le brasseur se lève seul, fait son travail, et personne n'a besoin d'envoyer une requête HTTP pour ça. La taverne s'auto-régule.
L'avantage de séparer le scheduler du Batchlet est la testabilité :
- on peut tester le job batch indépendamment du déclencheur
- et le déclencheur indépendamment de la logique métier.
Lire le rapport du lendemain matin
Une fois la nuit passée, le tavernier consulte le résultat du brassage. L'endpoint /stocks retourne un StockSnapshot — une photo instantanée de l'état actuel.
@GET
@Path("/stocks")
public StockSnapshot stocks() {
return tavernBreweryService.currentStock();
}
Et si on veut voir ce que le batch a précisément brassé lors de sa dernière exécution :
public record NightlyBatchResult(
long executionId,
String jobName,
String batchStatus,
int totalBrewed,
Map<BeerStyle, Integer> brewedByBeer
) {}
batchStatus reflète l'état final rapporté par Jakarta Batch : COMPLETED, FAILED, STOPPED.
C'est la signature officielle de la nuit : le brasseur a-t-il terminé son travail correctement ?
Rejouer la nuit : reset de simulation
Pour les démonstrations ou les tests, l'endpoint de reset remet tout à zéro :
@PUT
@Path("/stocks/reset")
public StockSnapshot resetStocks() {
tavernBreweryService.resetSimulation();
return tavernBreweryService.currentStock();
}
Le service remet chaque style de bière à 120 unités, vide les compteurs de consommation journalière, et efface le souvenir du dernier brassage. La taverne est prête pour un nouveau scénario.
C'est un outil pédagogique important : il permet de rejouer le cycle complet — consommer, vérifier les stocks, lancer le batch, vérifier à nouveau — autant de fois que nécessaire, sans redémarrer l'application.
Le cycle complet, raconté
Voici la séquence d'une journée complète dans la taverne :
1. Ouverture — les stocks sont pleins. GET /tavern/brewery/stocks retourne 120 unités par bière, 0 consommées.
2. Service — les aventuriers boivent. POST /tavern/brewery/day-consumptions avec les commandes de la journée. Le service sert ce qui est disponible, note les ruptures, accumule les consommations.
3. Fermeture — on consulte le bilan. GET /tavern/brewery/stocks montre les stocks réduits et les consommations cumulées.
4. La nuit — le brasseur travaille. POST /tavern/brewery/nightly-batches ou déclenchement automatique à 2h. Le Batchlet appelle brewConsumedBeers(), les stocks remontent, les compteurs journaliers se remettent à zéro.
5. Le lendemain — la taverne est prête. GET /tavern/brewery/stocks affiche à nouveau les stocks reconstitués. Le cycle repart.
Conclusion
La taverne a appris à dormir.
Jusqu'ici, elle répondait aux demandes en temps réel — vite, sous pression, sans souffler. Mais une partie du travail ne pouvait pas se faire dans l'urgence du service : le brassage demande du calme, du temps, et une vue d'ensemble sur ce qui a manqué dans la journée.
Jakarta Batch, intégré dans Quarkus via JBeret, apporte exactement ce cadre. Le fichier XML décrit le plan de travail. Le Batchlet exécute la tâche. Le JobOperator pilote et observe. Le scheduler déclenche à l'heure dite. Chaque pièce a un rôle précis, et CDI garantit que l'injection fonctionne naturellement dans tous les composants batch.
Le résultat : une application qui sépare proprement les deux rythmes de la taverne. Le jour appartient aux aventuriers. La nuit appartient au brasseur.
Et le lendemain matin, les tonneaux sont pleins.
Tout le code relatif à cet article peut être consulté ici :









{kind=link}