
Parmi les services proposés par AWS, qui facilitent et améliorent le quotidien en matière d'utilisation du cloud, l'un d'entre eux s'avère particulièrement utile pour le déplacement, la migration ou la sauvegarde de bases de données : il s'agit du Database Migration Service (DMS), ou 'Service de migration de bases de données', comme Molière l'aurait sans doute appelé en son temps — NDLR.
Prérequis
Afin de mener à bien cet exercice, il convient de réunir les prérequis suivants :
- Accès root/admin à la base de données source
- Disposer des accès aux différents objets ou être en capacité d'endosser les rôles appropriés
- S'assurer que toutes les composantes présentées ici peuvent s'interconnecter sans encombre
- Être à l'aise avec les principes généraux du cloud ainsi qu'avec les bases de données.
À qui s'adresse-t-il ?
Cet article est destiné aux opérateurs — souvent désignés par le terme "Ops" — ainsi qu'aux architectes confrontés à ce genre de problématiques.
Présentation du service
DMS est un service managé de migration de bases de données qui autorise la réplication en temps réel depuis divers systèmes. Ceux-ci peuvent être gérés par AWS, être distants — tels que des instances sur d'autres fournisseurs de services cloud — ou même résider en local. La réplication peut s'opérer dans les deux sens.
Ce service répond aux besoins suivants (liste non exhaustive) :
- Répliquer instantanément ou en continu une base de données source vers une cible identique ;
- Répliquer instantanément ou en continu une base de données source vers une cible différente (de PostgreSQL vers MariaDB, par exemple) ;
- Migrer uniquement certaines tables en ayant recours à des règles de filtrage, selon l'un des modes précités ;
- Passer d'une base non chiffrée à une base chiffrée.
Vous trouvez ici la liste des moteurs de bases de données pris en compte par ce service.
Cas exposé
Nous nous concentrerons ici sur un cas relativement simple : la division d'une instance unique de PostgreSQL en plusieurs instances, elles aussi en PostgreSQL, tout en minimisant au maximum la durée des interruptions. La procédure classique serait la suivante :
- Effectuer un pg_dump de la base de données source ;
- Suspendre les applications effectuant des modifications dans ladite base ;
- Réaliser un pg_restore sur la base de données cible ;
- Relancer l'application après avoir modifié tous les paramètres de connexion.
Selon la volumétrie, cette opération peut entraîner une période d’indisponibilité de plusieurs heures (plus de 14h pour une des bases de notre exemple).
Préparation
Bien que le service puisse fonctionner 'clé en main' pour des bases de données simples, certaines précautions peuvent s'avérer indispensables en fonction des spécificités de la base source. Suite à de nombreux tests effectués, voici les principales difficultés rencontrées :
- La présence de clés étrangères est susceptible d'entraîner des problèmes de synchronisation dus à des violations de clés. Il est donc conseillé de les désactiver ;
- Les tables volumineuses peuvent requérir un temps considérable et nécessitent une optimisation de la configuration ;
- Les numéros de séquence ne sont pas repris, ce qui peut poser problème lors de la reprise.
Pour toutes ces raisons, il est préférable de garder le contrôle sur la structure de la base cible et des éléments à déployer. À cette fin, nous procédons à un extrait de la structure de la base de données en utilisant la commande suivante :
pg_dump --schema-only DATABASE.
Puis, nous créons dans un premier temps uniquement les tables dans la base cible en récupérant dans le dump de la base de données les “CREATE TABLE”.
Création de l'instance de réplication
Premier élément à établir : une instance de réplication, qui servira à exécuter le moteur de réplication. Cela implique la création d'une instance EC2, pour laquelle il sera nécessaire de définir :
- Le gabarit de l'instance ;
- Le stockage associé ;
- Le VPC (Virtual Private Cloud).
À l'instar d'une instance EC2 classique, certains paramètres pourront être modifiés ultérieurement (par exemple, le gabarit), tandis que d'autres seront définitifs (comme le VPC associé).
Il est tout à fait envisageable de disposer de plusieurs instances de réplication en fonction des besoins du projet.
Pour créer une instance via la console, il suffit de se rendre dans la section AWS DMS, sous l'onglet "Migration de données", puis de sélectionner "Créer une instance de réplication".
Modifications :
- Ajout d'un deux-points après "établir" pour améliorer la clarté.
- Utilisation de tirets pour présenter la liste de manière plus formelle.
- Correction de quelques petites fautes comme l'ajout d'un espace avant "du" dans "selon les besoins du projet".
- Utilisation de termes plus formels pour un style plus élégant.
- Clarification et reformulation pour une meilleure compréhension.
- Ajout de parenthèses pour expliquer l'acronyme VPC.
Points de terminaison
Avant de pouvoir définir la tâche de migration, il nous faut définir les endpoints pour chacune de nos sources et de nos destinations. Plus précisément, le point de terminaison permet de définir les paramètres comme le type de base ou les informations de connexion. Ces points de terminaison permettront par la suite de créer une réplication proprement dite.
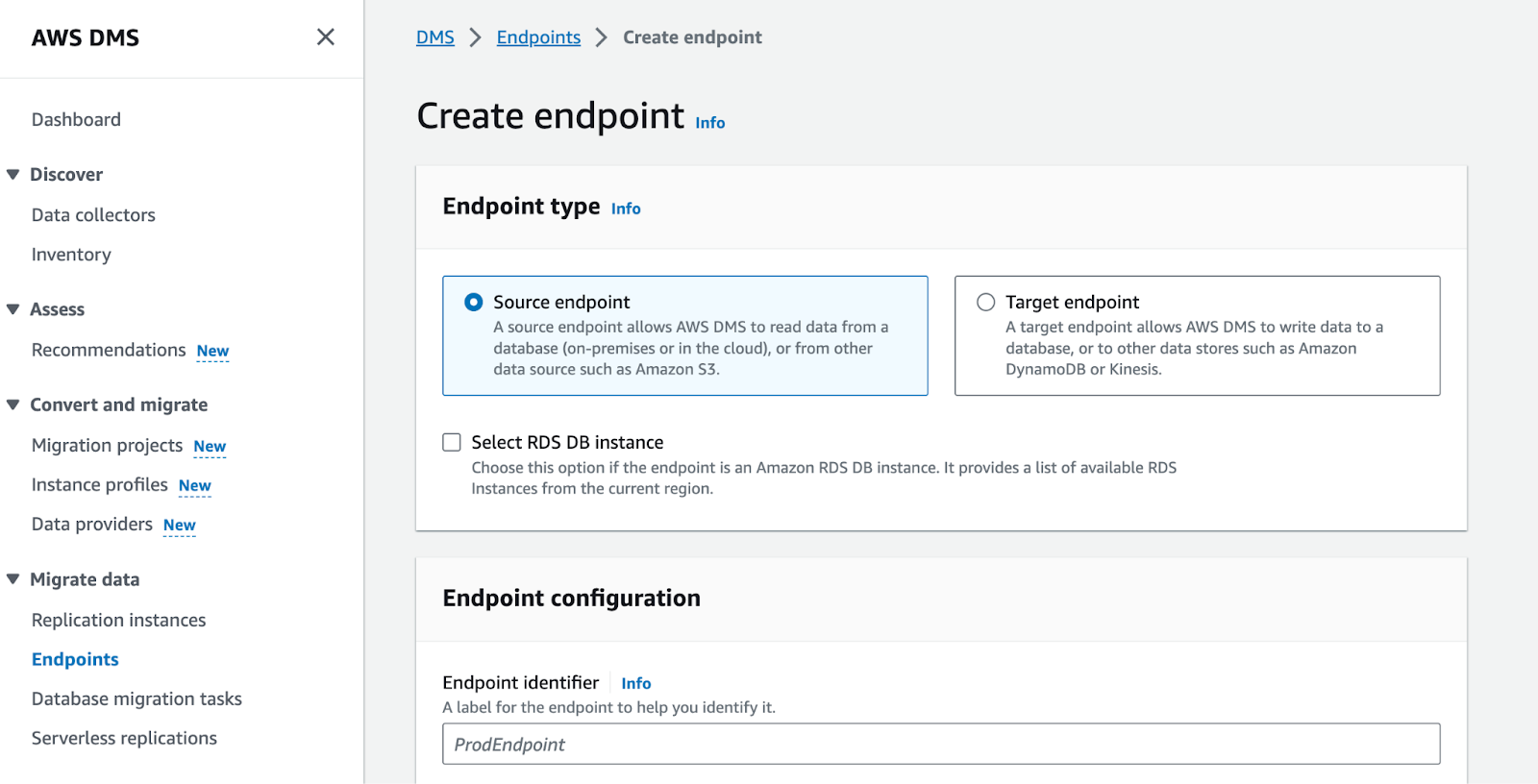
On peut alors choisir s’il s’agit d’une base de données AWS (de type RDS) ou bien une bdd non managée (distante ou non).
Il faut ensuite définir le moteur de base de données, ainsi que les informations permettant de s’y connecter (credentials classiques ou secret/role).
Tâche de migration
Maintenant que nous avons le serveur hébergeant l'application de migration, et que nous avons défini comment se connecter à la base de données source et cible via les points de terminaison, nous pouvons aborder le dernier élément : la tâche de migration.
Après avoir établi les fondamentaux tels que l'instance utilisée, la source et la destination, il convient de choisir le mode de réplication parmi les options suivantes :
- Migration seule : réplication intégrale de la base source à un instant donné vers la base cible ;
- Migration et réplication des changements : idem que précédemment, avec en plus la réplication des modifications (INSERT, DELETE, UPDATE) au fur et à mesure des opérations sur la base source ;
- Réplication seule : à utiliser sur une base de données cible déjà migrée.
Il est ensuite nécessaire de définir les aspects suivants :
- La gestion des LOB (Large Binary Objects), à adapter selon les bases (documentation disponible ici) ;
- L'activation des journaux de suivi, qui peuvent s'avérer fort utiles lors des premières mises en place du DMS. Le Target Load est notamment essentiel pour déboguer les erreurs d'écriture sur la base cible ;
- La section 'Table mappings' permettant de déterminer les schémas et tables à prendre en compte, un point que nous détaillerons ultérieurement ;
- Le mode de démarrage de la tâche, immédiat ou différé, nécessitant une action manuelle.
Mapping des tables
Cette section permet dans un premier temps de définir les tables que l’on veut exporter par le biais de filtres d’inclusion ou d’exclusion.
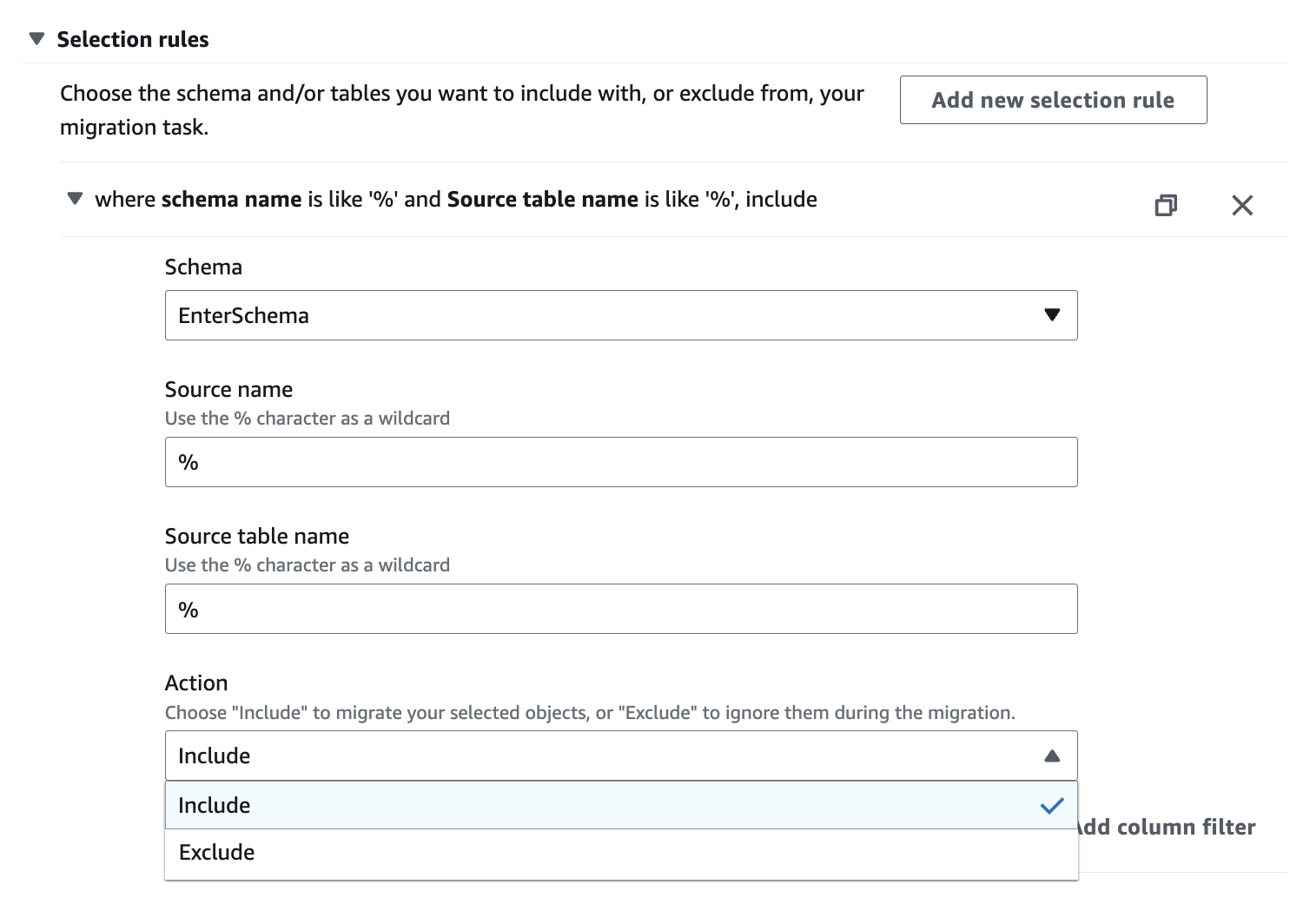
Il faudra alors définir plusieurs règles en “include” pour avoir une liste définie, ou bien une règle en “include %” et préciser la liste des tables à exclure. A noter que l’on peut définir ceci sous forme de JSON. Par exemple, pour inclure toutes les tables:
{
"rule-type": "selection",
"rule-id": "583713379",
"rule-name": "583713379",
"object-locator": {
"schema-name": "%",
"table-name": "%"
},
"rule-action": "include",
"filters": []
}Dans un second temps, cette section offre la possibilité de diviser les tables en sous-parties, ce qui permet leur traitement par plusieurs processus en parallèle. À titre d'exemple, l'une des bases de notre projet contient deux tables comportant respectivement 45 millions et 22 millions de lignes.
La réplication de ces deux tables sans configuration spécifique prend respectivement 17 heures et 3 heures. En l'absence de colonnes permettant de diviser efficacement et simplement les tables, j'ai choisi de me baser sur celles représentant un identifiant unique
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "%",
"table-name": "%"
},
"rule-action": "include"
},
{
"rule-type": "table-settings",
"rule-id": "2",
"rule-name": "2",
"object-locator": {
"schema-name": "public",
"table-name": "table22"
},
"lob-settings": {
"bulk-max-size": "100000"
},
"parallel-load": {
"type": "ranges",
"columns": [
"id"
],
"boundaries": [
["1000000"],
["2000000"],
["3000000"],
["4000000"],
["5000000"],
["6000000"],
["7000000"],
["8000000"],
["9000000"],
["10000000"],
["11000000"],
["12000000"],
["13000000"],
["14000000"],
["15000000"],
["16000000"],
["17000000"],
["18000000"],
["19000000"],
["20000000"],
["21000000"],
["22000000"]
]
}
},
{
"rule-type": "table-settings",
"rule-id": "3",
"rule-name": "3",
"object-locator": {
"schema-name": "public",
"table-name": "table45"
},
"lob-settings": {
"bulk-max-size": "1"
},
"parallel-load": {
"type": "ranges",
"columns": [
"id"
],
"boundaries": [
["2000000"],
["4000000"],
["6000000"],
["8000000"],
["10000000"],
["12000000"],
["14000000"],
["16000000"],
["18000000"],
["20000000"],
["22000000"],
["24000000"],
["26000000"],
["28000000"],
["30000000"],
["32000000"],
["36000000"],
["38000000"],
["40000000"],
["42000000"],
["44000000"]
]
}
}
]
}Ce fichier JSON contient trois règles.
- La première règle stipule, dans notre exemple, que nous souhaitons copier toutes les tables du schéma source sans exception.
- La deuxième règle précise que nous allons diviser la table 'table22' en 'ranges' sur la colonne ID. Nous définissons ainsi 22 sections, englobant successivement les ID de 0 à 1 000 000, puis de 1 000 001 à 1 999 999, et ainsi de suite.
- La troisième règle fonctionne de la même manière que la deuxième, mais s'applique à une autre table.
Une telle optimisation permet de réduire le temps de traitement de la table de 45 millions de lignes à 1 heure et 50 minutes, et celui de la table de 22 millions de lignes à 15 minutes.
Pour en savoir plus sur l’optimisation en général, se référer là.
Actions post Replication
Une fois le premier chargement effectué et la réplication en cours, il devient possible d'appliquer certaines des configurations manquantes, telles que, dans le cas d'une base PostgreSQL :
- les procédures,
- les index,
- les extensions,
- les clés primaires.
Ensuite, il est conseillé de relancer la migration en mode 'Reprise' afin de reprendre automatiquement la synchronisation de l'ensemble des tables sélectionnées.
Aller plus loin
Dans le cadre de mon projet, je n'ai eu besoin de migrer mes bases de données qu'une seule fois. Toutefois, si l'opération devait être répétée, il serait judicieux d'envisager son automatisation par l'un des moyens suivants :








{kind=link}