Qu’est-ce que Delta Lake ?
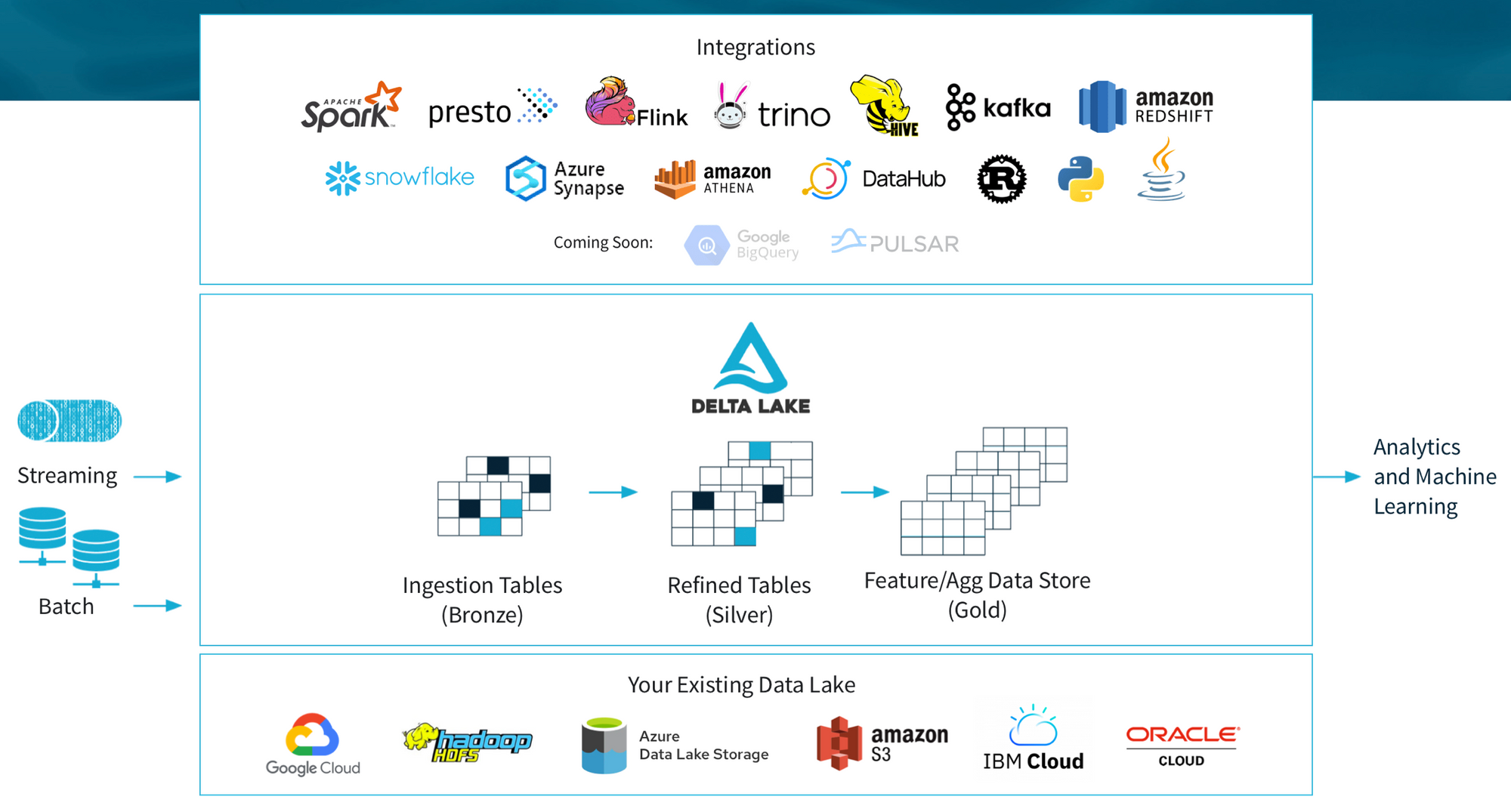
Delta Lake est un moteur de stockage de données open source qui apporte une fiabilité et une performance aux Data Lakes. Il a été développé par Databricks pour améliorer les performances et la fiabilité des grands ensembles de données stockés dans des systèmes de fichiers distribués.
Qu'est ce qui distingue les table Delta des autres tables de données ?

Les Delta Tables se distinguent des autres tables de données par plusieurs caractéristiques :
- Transactions ACID : Les Delta Tables protègent vos données avec la sérialisabilité, le plus haut niveau d’isolation, garantissant l’intégrité des données même en cas de modifications concurrentes.
- Métadonnées évolutives : Les Delta Tables peuvent gérer des tables de l’ordre du pétaoctet avec des milliards de partitions et de fichiers sans effort.
- Voyage dans le temps : Les Delta Tables permettent d’accéder à des versions antérieures des données pour des audits, des retours en arrière ou pour reproduire des expériences.
- Open Source : Les Delta Tables sont soutenues par une communauté, basées sur des normes ouvertes, un protocole ouvert et des discussions ouvertes.
- Unification du Batch/Streaming : Les Delta Tables offrent une sémantique d’ingestion “exactement une fois” pour le backfilling jusqu’aux requêtes interactives.
- Évolution / Application du schéma : Les Delta Tables empêchent les mauvaises données de causer une corruption des données.
- Historique d’audit : Les Delta Tables enregistrent tous les détails des modifications, fournissant un historique d’audit complet.
- Opérations DML : Les Delta Tables offrent des API SQL, Scala/Java et Python pour fusionner, mettre à jour et supprimer des ensembles de données.
Finalement, l’adoption de Delta Lake sur GCP vous donne accès aux avantages des services cloud de Google. Par exemple, Google Cloud Storage peut être utilisé pour stocker vos données, offrant ainsi une haute durabilité, disponibilité et évolutivité.
De plus, bien que BigQuery ne soit pas encore officiellement supporté par Delta Lake, il offre également des possibilités intéressantes pour l’analyse des données. Nous explorerons cette intégration dans un futur article.
Ces caractéristiques font des Delta Tables un choix puissant pour la gestion des données à grande échelle.
Comment fonctionne Delta Lake ?
Delta Lake stocke les données sous forme de fichiers Parquet, un format de fichier colonne optimisé pour le traitement des données Big Data.

Lorsque vous effectuez des opérations d’écriture sur une table Delta, les nouvelles données sont écrites dans de nouveaux fichiers Parquet.
Le format Parquet est un format de fichier colonne optimisé pour le traitement des données Big Data. Il est conçu pour être performant pour les types de requêtes analytiques couramment utilisées sur les Big Data, et il est compatible avec de nombreux systèmes de traitement de données, y compris Apache Spark.
En plus d’écrire les nouvelles données, Delta Lake met également à jour les métadonnées de la table pour refléter ces modifications. Les métadonnées sont des informations sur les données elles-mêmes, comme le schéma de la table, les statistiques sur les données, et l’emplacement des fichiers de données.
Une partie importante des métadonnées est le journal des transactions. Ce journal enregistre toutes les modifications apportées à la table, y compris l’ajout de nouveaux fichiers de données, la modification du schéma, et la suppression de fichiers de données. Le journal des transactions est essentiel pour assurer la cohérence et la fiabilité des données.
Grâce au journal des transactions, Delta Lake peut offrir des fonctionnalités avancées comme le versionnement des données et les opérations d’annulation et de rétablissement. Le versionnement des données vous permet d’accéder à des versions précédentes de la table, ce qui peut être utile pour l’audit ou le débogage.
Les opérations d’annulation et de rétablissement vous permettent d’annuler une modification si elle s’avère incorrecte, ou de la rétablir si vous changez d’avis.
En somme, l’utilisation d’une table Delta offre une grande flexibilité et un contrôle précis sur vos données.
Dans le prochain article, nous verrons comment créer une table Delta et comment lire et écrire des données dans cette table. Restez à l’écoute !
Lien utile : (Site officiel) https://delta.io








){kind=link}