
The past, present, and future of Google Kubernetes Engine
La première conférence a été l'occasion de faire un voyage dans le temps, de l'histoire à l'avenir de Kubernetes. Au commencement, les monolithes régnaient, et Kubernetes lui-même était un monolithe.
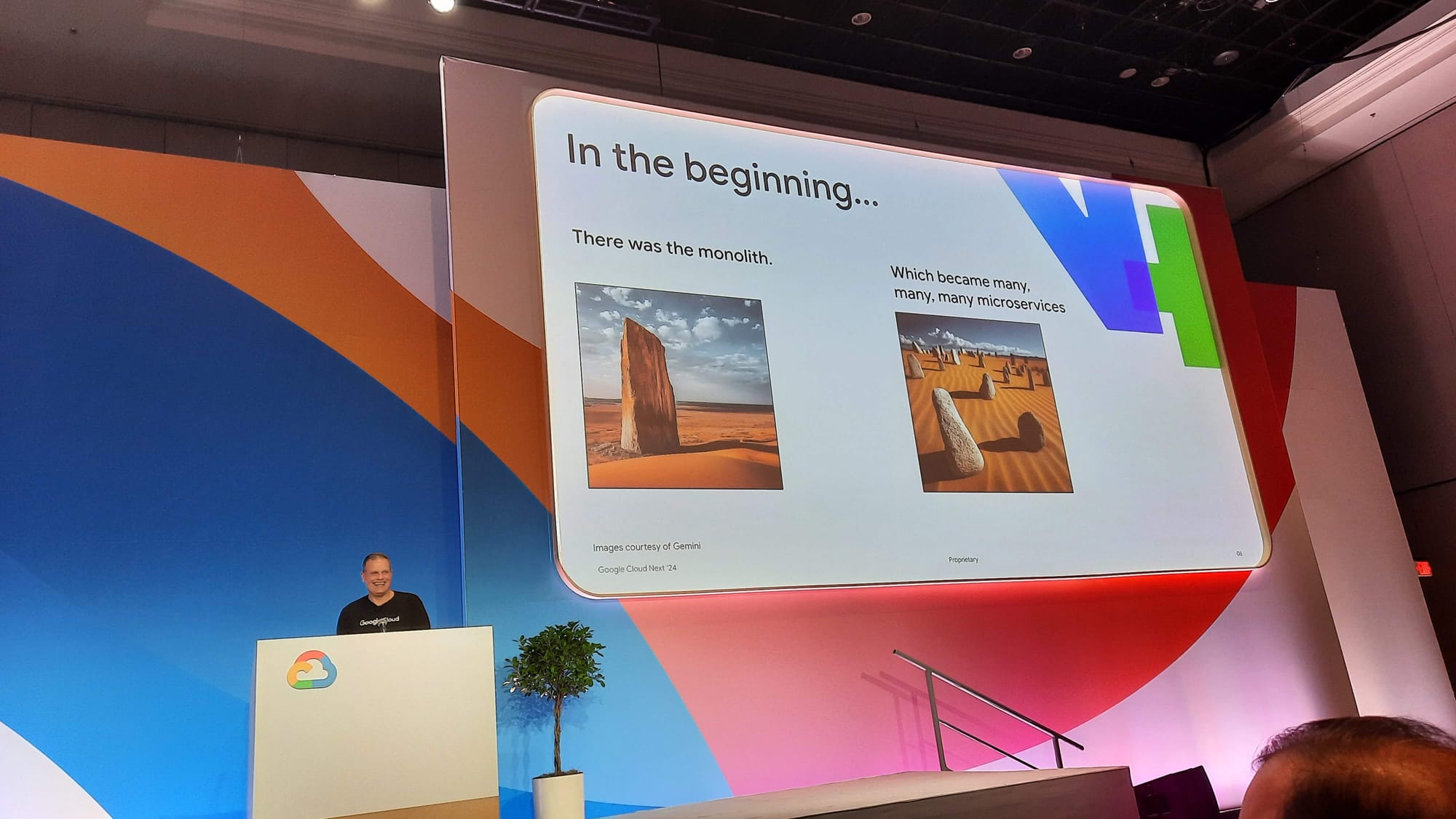
L'évolution de Kubernetes
En 2003, Google a lancé Borg en interne, une plateforme de gestion de clusters qui a jeté les bases de ce que Kubernetes allait devenir. Dix ans plus tard, en 2013, Docker est né, révolutionnant la manière dont les applications sont empaquetées et déployées. Enfin, en 2014, Kubernetes a vu le jour, marquant une nouvelle ère dans la gestion des conteneurs. Aujourd'hui, nous célébrons le dixième anniversaire de Kubernetes 🎂.
Google Kubernetes Engine Enterprise aujourd'hui
La majeure partie de la conférence a été consacrée aujourd'hui à l'explication de ce qu'est Google Kubernetes Engine (GKE) Enterprise. Faisant écho à la session d'hier, nous approfondissons les caractéristiques clés de GKE Enterprise, soulignant sa sécurité renforcée, sa scalabilité impressionnante et son aide au diagnostic avancée grâce à l'IA de Gemini :
- Sécurité accrue : GKE Enterprise offre des dashboards de sécurité avancés et la vérification de la signature binaire des images, garantissant ainsi la sécurité des applications déployées.
- Scalabilité : GKE Enterprise peut gérer jusqu'à 15000 nœuds, offrant une grande flexibilité pour les grandes entreprises.
- Aide au diagnostic : Grâce à Gemini, le puissant modèle d'IA de Google, GKE Enterprise peut aider à diagnostiquer et résoudre les problèmes plus rapidement et plus efficacement.
L'avenir de GKE
La partie de la conférence consacrée à l'avenir de GKE était relativement courte, mais elle a néanmoins introduit quelques fonctionnalités intéressantes. Parmi elles, les compute classes, le dynamic workload scheduling et le flexible start job scheduling. Ce dernier permet aux jobs de démarrer dès que les ressources disponibles le permettent, plutôt que de manière séquentielle. Ce mode de fonctionnement est particulièrement adapté à l'IA, par exemple pour charger des bases de données vectorielles. Ces nouvelles fonctionnalités promettent de faire de GKE Enterprise une plateforme optimisée pour l'IA.
En conclusion, la conférence a offert un aperçu intéressant de l'évolution de Kubernetes et de ce que l'avenir réserve à GKE. Même si la partie sur l'avenir de GKE était relativement courte, elle a laissé entrevoir de nouvelles fonctionnalités prometteuses pour optimiser l'utilisation de l'IA.
How to use managed database services in an air-gapped on-premises environment
Dans ce talk Jay et Bjoern de Google font un tour d’horizon des solutions de base de données disponibles sur Google Cloud. Leur présentation a souligné la complexité de la gestion des bases de données et l'intérêt des services managés, dont le retour sur investissement est prouvé.
La complexité de la gestion des bases de données et l'intérêt des services managés
Gérer une base de données peut s'avérer être une tâche complexe. Cela nécessite une expertise technique approfondie, une gestion constante et une maintenance régulière. Les services managés offrent une solution à ces défis en prenant en charge la gestion de la base de données, permettant aux entreprises de se concentrer sur leurs activités principales. Le retour sur investissement de ces services est prouvé, car ils réduisent les coûts opérationnels et améliorent l'efficacité.
Google Distributed Cloud : étendre Google Cloud à tout type d'infrastructure
L'un des points forts de la présentation a été l'introduction de Google Distributed Cloud (GDC). GDC permet d'étendre Google Cloud à tout type d'infrastructure, y compris celles qui sont déconnectées (airgap). Cela signifie que les entreprises peuvent bénéficier des services de Google Cloud, même dans des environnements on-premises ou déconnectés.
Focus sur AlloyDB Omni
Jay et Bjoern ont ensuite présenté AlloyDB Omni, une base de données compatible PostgreSQL qui offre de meilleures performances. AlloyDB Omni supporte trois modes :
- Standard : pour les opérations de base de données traditionnelles.
- Analytique : un mode orienté colonnes pour des analyses de données efficaces.
- Vectoriel : un mode adapté à l'IA.
Ils ont également rappelé l'utilisation de la vectorisation dans le contexte LLM/RAG.
Malgré l'aperçu intéressant des solutions de bases de données sur Google Cloud et le lien avec l’IA, le côté Airgap, qui était d'un grand intérêt pour moi, a été très peu évoqué, j’aurais bien aimé en savoir un peu plus.
Create a Generative Chat App using Vertex AI Conversation
Sous la houlette de Benoit (hé oui, un français), je termine la conférence comme je l'ai commencée, c'est à dire par une séance de travaux pratiques.
Pour ce lab, il s'agissait de construire un agent conversationnel en utilisant Dialogflow. En quelque clic, j'ai pu charger un dataset et chatter avec l'agent en prenant en compte les documents du dataset.
Par la suite, j'ai même pu discuter au téléphone avec mon agent, simplement en activant la fonctionnalité "CX Phone Gateway".
Mais pendant la session, je n'ai pas pu m'empêcher de reprendre brièvement mon rôle de trainer en donnant un petit coup de main à mon voisin 😄

Pour ma première session Google Next, je repars avec des étoiles pleins les yeux et des rêves pleins la tête. Je vous dis à très bientôt pour de nouveaux retours de confs !








{kind=link}