Les équipes Data font face à un défi grandissant : livrer des pipelines de traitement toujours plus complexes, tout en garantissant leur fiabilité, leur traçabilité et leur rapidité de livraison. Sur Google Cloud Platform (GCP), Dataflow est un moteur puissant pour exécuter des traitements massifs de données en streaming ou batch. Mais sans un cadre d’industrialisation solide, les pipelines deviennent vite difficiles à maintenir, à tester et à déployer.
C’est ici qu’interviennent les pratiques CI/CD en utilisant Docker, Flex Templates, Terraform et Cloudbuild. Ensemble, ces outils permettent d’atteindre une maturité DataOps en ancrant les bonnes pratiques d’ingénierie logicielle dans la livraison des pipelines. Afin de transformer les pipelines artisanaux en véritables produits data : versionnés, reproductibles, testables et automatisés.
Du pipeline POC au pipeline industriel
Dans de nombreuses entreprises, les pipelines Dataflow naissent souvent comme des prototypes isolés : quelques fichiers Python ou Java, lancés manuellement via la console. Puis arrivent la réalité data : volumétrie croissante, schémas qui évoluent, données en retard (late data), replays/backfills, exigences de latence et SLA. Ces pipelines deviennent des actifs critiques. Sans versioning d’image, sans environnement de test, et sans automatisation du déploiement, les risques s’accumulent :
- Paramètres passés à la main et erreurs de configuration
- Évolutions de schéma non contrôlées
- Absence d’idempotence et de traitement exactly-once = doublons
- Gestion du retard (watermarks) absente ou incohérente = pertes de données
- DLQs inexistantes = impossible d’isoler les messages défectueux
- Throughput / latence non maîtrisés, autoscaling imprévisible
- Comportements différents entre environnements
- Difficulté de rollback et d’audit
- Temps de mise en production long
L’approche CI/CD change la donne : elle applique les bonnes pratiques du développement logiciel au monde de la data. Chaque modification de code déclenche automatiquement la construction, le test et le déploiement traçable avec paramètres maîtrisés (sources/sinks, fenêtres, watermarks).
Résultat : des pipelines reproductibles, observables et sûrs face aux réalités data (retard, replays, évolutions de schéma).
Une architecture moderne : Docker, Flex Templates, Terraform et CloudBuild
L’industrialisation repose sur quatre piliers complémentaires : Docker, Flex Templates, Terraform et CloudBuild.
Pour illustrer cette approche, un exemple inspiré d’un projet réel : un pipeline de détection des extractions massives de données sur BigQuery déployé sur Dataflow à l’aide de Docker, Flex Templates, Terraform et Cloud Build. L’objectif est de montrer comment ces briques s’articulent dans un flux cohérent et reproductible.
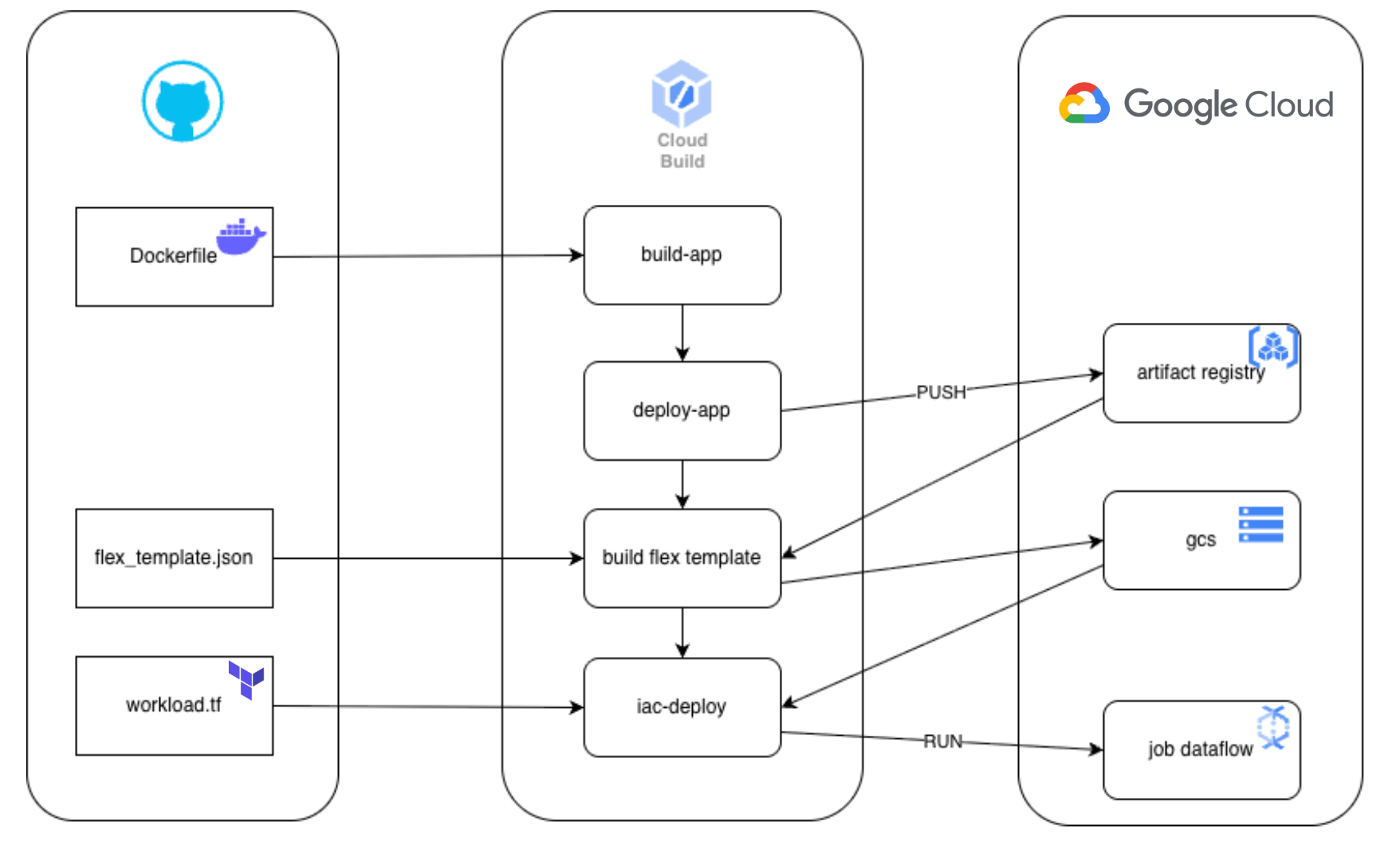
1. Docker
Pour encapsuler le runtime, les dépendances et le code du pipeline. Chaque pipeline devient une image versionnée et isolée, supprimant les problèmes de compatibilité.
Exemple : le Dockerfile ci-dessous définit un environnement Python 3.11 basé sur l’image officielle de Google pour Dataflow
FROM gcr.io/dataflow-templates-base/python311-template-launcher-base
COPY ./src /dataflow/src
COPY setup.py /dataflow/
COPY requirements.txt /dataflow/
WORKDIR /dataflow
RUN pip install --upgrade pip setuptools \
&& pip install -r requirements.txt
ENV FLEX_TEMPLATE_PYTHON_SETUP_FILE="/dataflow/setup.py"
ENV FLEX_TEMPLATE_PYTHON_PY_FILE="/dataflow/src/main.py"
ENTRYPOINT ["/opt/google/dataflow/python_template_launcher"]Dockerfile
2. Flex Templates
Un Flex Template est un fichier de configuration qui décrit comment exécuter un pipeline Dataflow à partir d’une image Docker.
Il permet de transformer un pipeline Dataflow en composant déployable et paramétrable : au lieu de modifier le code, on peut simplement ajuster ses paramètres d’exécution (sources, destinations, fenêtre de traitement, options de parallélisme…).
Cette approche est particulièrement utile dans les contextes data streaming : par exemple, relancer un job en changeant le topic Pub/Sub d’entrée, le sink BigQuery ou Pub/Sub de sortie, ou adapter la fenêtre temporelle sans toucher au code.
Les Flex Templates garantissent la réutilisabilité, la traçabilité des versions et la séparation claire entre code et configuration, un point clé dans la gouvernance des pipelines Dataflow.
Exemple : Un Flex Template décrivant la source (une souscription Pub/Sub "input_subscription") et le sink (un topic Pub/Sub "output_topic") du pipeline.
{
"sdk_language": "PYTHON",
"name": "mass-extraction-flex",
"description": "Job Dataflow Flex Template for mass extraction",
"parameters": [
{
"name": "input_subscription",
"label": "Input Pub/Sub subscription",
"helpText": "Input pub/sub subscription ingest source data",
"paramType": "TEXT",
"isOptional": false
},
{
"name": "output_topic",
"label": "Output Pub/Sub topic",
"helpText": "Output topic where data will be ingested",
"paramType": "TEXT",
"isOptional": false
}
]
}
flex_template.json
3. Terraform
Pour gérer toute l’infrastructure GCP et Dataflow : comptes de service, droits IAM, buckets, templates, déclenchement de jobs Dataflow. Les déploiements sont reproductibles, audités et versionnés.
Pour une introduction complète aux concepts et usages de Terraform, vous pouvez également consulter notre article dédié à Terraform.
Exemple : Terraform assure la création, la configuration et le lancement du job
# Création et lancement du Job Dataflow en utilisant un Flex Template
resource "google_dataflow_flex_template_job" "mass_extraction_job" {
provider = google-beta
project = local.project
# Nom du job : suffixé par l’environnement et un timestamp pour éviter les collisions entre exécutions.
name = "job-name-${local.env}-${formatdate("YYYYMMDD-HHmmss", timestamp())}"
region = local.region
# Référence vers le fichier JSON du Flex Template stocké sur GCS.
container_spec_gcs_path = "gs://${local.bucket_name}/templates/flex_template.json"
# Réseau et sous-réseau utilisés par les workers Dataflow.
network = local.dataflow_network
subnetwork = local.dataflow_subnetwork
# Force les workers à utiliser des IP privées (pas d’exposition publique = meilleure sécurité).
ip_configuration = "WORKER_IP_PRIVATE"
# Emplacement temporaire pour les fichiers intermédiaires (checkpoints, state, logs…)
temp_location = "gs://${local.bucket_name}/tmp/"
# Taille du cluster Dataflow : bornes min/max pour l’autoscaling.
num_workers = local.min_instance_count
max_workers = local.max_instance_count
# 2 = autoscaling horizontal automatique selon le débit.
autoscaling_algorithm = 2
# Type de machine des workers
machine_type = local.machine_type
# Service Account dédié pour isoler les permissions du job Dataflow.
service_account_email = google_service_account.dataflow_sa.email
# Active le Streaming Engine : déplace le buffering et le shuffling vers le backend GCP managé pour réduire la latence et améliorer la scalabilité
enable_streaming_engine = true
# Terraform ne bloque pas jusqu’à la fin du job
skip_wait_on_job_termination = true
# Paramètres dynamiques du Flex Template
parameters = {
input_subscription = data.google_pubsub_subscription.mass_extraction_subscription.id
output_topic = local.events_destination_id
}
# Dépendances explicites pour garantir que le SA est créé avant le job.
depends_on = [google_service_account.dataflow_sa]
}
workload.tf
4. Cloudbuild
Pour orchestrer le tout. Moteur de CI/CD natif à GCP, Cloud Build déclenche automatiquement la construction et le déploiement des pipelines à chaque commit.
Il build l’image Docker, la pousse dans Artifact Registry, met à jour le Flex Template, applique l’infrastructure Terraform, et déclenche des déploiements vers des environnements cibles (dev → staging → prod) avec validations.
Exemple : makefile contenant les principales étapes exécutées par Cloud Build.
- Étape build-app : Construction de l’image Docker contenant le code Python Beam, les dépendances et les fichiers de config.
- Étape deploy-app : Authentification et push de l’image dans Artifact Registry. Puis construction et upload du Flex Template dans GCS. DFW_TEMPLATE_PATH : Path du Flex template dans GCS.
- Étape iac-deploy : Application du plan Terraform pour créer/mettre à jour l’infrastructure : Réseau VPC, SA, topics, et le job Dataflow.
build-app:
@echo "Construction de l’image Docker et packaging des sources"
docker build --platform linux/amd64 \
--tag eu-docker.pkg.dev/$(PROJECT)/eu.gcr.io/$(MODULE):latest .
deploy-app:
@echo "Déploiement de l’image et construction du Flex Template"
gcloud auth configure-docker eu-docker.pkg.dev
docker push eu-docker.pkg.dev/$(PROJECT)/eu.gcr.io/$(MODULE):latest
gcloud dataflow flex-template build "$(DFW_TEMPLATE_PATH)" \
--image=eu-docker.pkg.dev/$(PROJECT)/eu.gcr.io/$(MODULE):latest \
--sdk-language=PYTHON \
--metadata-file=flex_template_metadata.json
iac-deploy:
@echo "Déploiement IaC avec Terraform"
cd $(TF_DIR); terraform apply -auto-approve -input=false $(shell basename $(TF_PLAN));
cloudbuild.mk
Ce que change réellement la CI/CD pour Dataflow
Vitesse de livraison
Des pipelines prêts à déployer en quelques minutes, grâce aux builds reproductibles et aux validations automatisées. Les correctifs et évolutions arrivent plus vite en production.
Qualité et fiabilité
Des tests systématiques, des images immuables, des templates uniformisés et des droits IAM contrôlés réduisent drastiquement les régressions et les comportements divergents entre environnements.
Gouvernance et traçabilité
Chaque exécution est rattachée à une version (image), à un commit et à un jeu de paramètres. Les revues de code portent sur l’infra (Terraform) et sur l’applicatif. Les audits gagnent en clarté.
Efficience opérationnelle
Moins d’opérations manuelles, moins d’incidents, des déploiements prévisibles. L’équipe se concentre sur la valeur data plutôt que sur la plomberie d’exécution.
Conclusion
Industrialiser Dataflow, c’est faire passer vos traitements de données de l’artisanat à l’ingénierie : des pipelines prévisibles, testés et rapides à livrer.
Le duo Docker + Flex Templates garantit un exécutable cohérent ; Terraform apporte la reproductibilité de l’environnement ; et Cloud Build orchestre l’ensemble avec des garde-fous de sécurité et de qualité.
Mais au-delà de la mécanique CI/CD, c’est la fiabilité de la donnée elle-même qui s’améliore : les schémas évoluent sans rupture, les messages sont traités exactement une fois, les dead-letter queues (DLQ) capturent les erreurs sans bloquer le flux, les replays et backfills sont maîtrisés.
Les jobs gagnent en prévisibilité, la latence devient mesurable, les SLA sont atteignables.
Cette démarche pose les bases d’un DataOps moderne : une plateforme data où la vitesse de changement ne sacrifie ni la stabilité, ni la gouvernance, ni la qualité des données.