
J'assiste en ce moment au Google Cloud Next 2026. Une tendance revient partout : l'agent SRE, la sentinelle qui veille sur vos nuits.
Sur le stand Anthropic, une foule compacte autour d'une démo Claude qui ingère des alertes et mène l'enquête tout seul. Dans une conférence Google/PayPal, on découvre comment 3000+ microservices ont été connectés à un agent SRE autonome déployé sur Vertex. Chez Datadog, un agent SRE est désormais embarqué nativement dans le produit — zéro ligne de code à écrire pour le brancher. Et chez Komodor, toute une plateforme est construite autour de Klaudia, un agent IA spécialisé Kubernetes qui passe du mode copilote au mode pilote automatique selon la confiance que vous lui accordez.

Un agent SRE, dans sa forme la plus simple, reçoit une alerte — latence en hausse, taux de paiement en chute, spike de 500 — et la transforme en action. L'idée n'est pas neuve ; ce qui change, c'est qu'elle est désormais industrialisable.
Plutôt qu'une énième taxonomie de ce qu'un agent "peut faire", je vous propose une grille de lecture que j'ai vue revenir chez les trois intervenants : 5 niveaux de maturité, de l'interprétation brute d'une alerte jusqu'à la prévention de l'incident suivant. On monte un barreau à la fois, on valide le contexte et les barrières à chaque étape.
Dans l'ordre :
- Interpréter l'alerte
- Enquêter pour trouver la root cause
- Remédier — et c'est là que ça se tend
- Reporter et collaborer avec l'humain
- Prévenir l'incident suivant (la cerise sur le gâteau)
Un agent SRE, c'est quoi ?
Dans sa forme la plus brute : un agent qui reçoit une alerte, consulte votre système, et produit soit une réponse ("voilà ce qui se passe"), soit une action ("voilà ce que j'ai fait"). Google et Anthropic ont présenté la même recette, avec trois ingrédients.

- Models — le moteur de raisonnement. Pour un agent SRE, pas de compromis : modèle premium sur la remédiation, modèles plus légers pour le triage ou la rédaction du post-mortem.
- Context — ce que l'agent sait de votre système : schéma C4, description des services, runbooks, historique des incidents. Sans contexte, l'agent devine ; avec, il comprend.
- Tooling — les outils qu'il peut appeler : requêtes métriques, lecture de logs, diff git, exécution de scripts. MCP s'impose ici comme la plomberie par défaut.
Les trois sont indissociables. Un bon modèle sans tooling reste un chatbot. Du tooling sans contexte produit un agent qui tire dans tous les sens. Du contexte sans modèle assez puissant ne passe pas les cas limites.
C'est cette trinité qui conditionne la montée en maturité. Voyons maintenant les 5 niveaux, un par un.
Niveau 1 — Interpréter l'alerte
Premier barreau : une alerte tombe, et l'agent doit la traduire. "Latence p99 > 800 ms sur checkout-api" ne dit rien tout seul. Est-ce que ce service est critique ? Quelles dépendances ont une alerte active ? Est-ce un symptôme connu, déjà vu la semaine dernière ?
L'agent a besoin de contexte structuré. En pratique, vous le nourrissez avec :
- Un schéma C4 ou équivalent — qui parle à qui, quelles briques sont critiques
- La description des services — ownership, SLO, dépendances
- Les runbooks existants — les vôtres, tels quels, pas une version "pour IA"
- L'historique des incidents — pour reconnaître un pattern récurrent
Anthropic a résumé cette étape dans un schéma simple : une boucle agentique ("core agentic loop") qui alterne raisonnement et appels outils, adossée à deux briques clés — la runbook adherence (l'agent suit réellement vos procédures) et le post-mortem (il capitalise sur l'incident d'après).
⚠️ Le vrai défi à ce niveau : fournir une vue suffisamment complète sans noyer le contexte. Balancer tout votre schéma d'infrastructure dans le prompt, c'est le meilleur moyen de diluer l'attention du modèle et de dégrader sa précision. L'approche qui fonctionne : donner à l'agent un point d'entrée — un catalogue de services racine, un C4 de premier niveau, un index de runbooks — et le laisser explorer ensuite via ses outils. Il tire le fil qu'il a besoin de tirer, à la profondeur utile, plutôt que d'avaler toute l'infra d'un coup. C'est le même principe qu'un humain qui ouvre d'abord le service catalog avant d'aller regarder le détail d'un microservice.
À ce niveau, l'agent ne touche encore à rien. Il lit, il croise, il classe : "alerte réelle, service critique, pattern connu" vs "faux positif, on ignore". Et c'est déjà 80% du bruit éliminé sur une astreinte classique.
Niveau 2 — Enquêter (le tooling)
Interpréter une alerte, c'est bien. Trouver la root cause, c'est l'étape qui change vraiment la donne — et celle qui impose un tooling béton. L'agent doit pouvoir :
- Se connecter à votre cluster Kubernetes pour récupérer les logs et l'état des pods
- Interroger la base de données (slow queries, locks, volumétrie)
- Collecter des métriques (CPU, mémoire, latence réseau)
- Corréler avec d'autres alertes actives
- Vérifier les derniers changements — commits Git, déploiements, feature flags, tickets ServiceNow
C'est ici que MCP (Model Context Protocol) prend tout son sens. Un agent SRE efficace, c'est un noyau + N serveurs MCP derrière. Chaque outil existant de votre stack devient une capacité de l'agent.
PayPal a illustré l'approche de manière spectaculaire : 3000+ microservices, données éparpillées entre Datadog, Splunk, leur log maison (CAL), ServiceNow et BigQuery. Plutôt que de tout migrer, leurs équipes ont exposé chaque source via MCP. Résultat : zero data migration, l'agent accède à tout via une couche d'API unifiée.
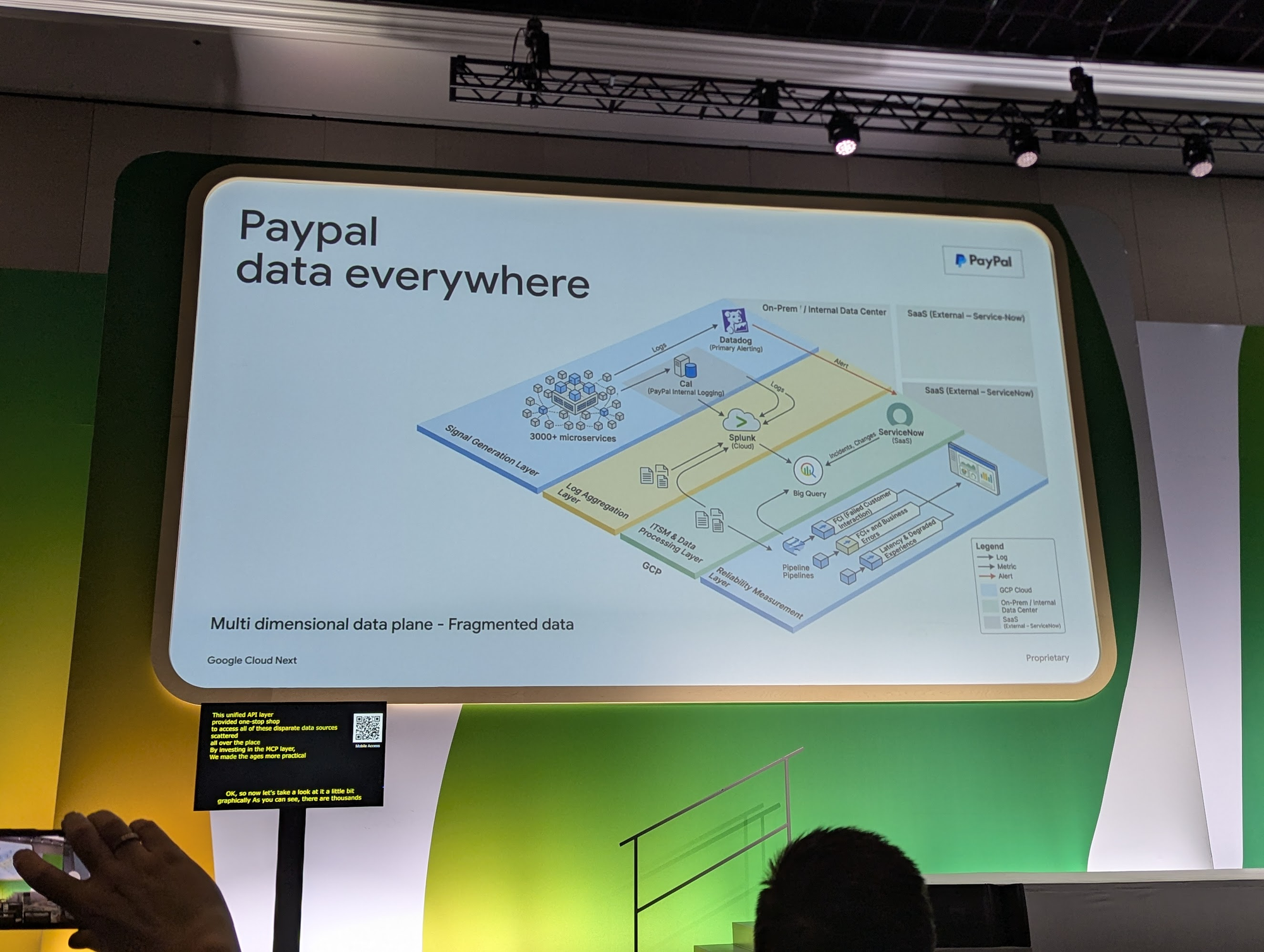
Côté implémentation, Anthropic a montré qu'un agent SRE minimal tient en une quinzaine de lignes avec le Claude Agent SDK :
export CLAUDE_CODE_USE_VERTEX=1
export ANTHROPIC_VERTEX_PROJECT_ID=my-gcp-project
export CLOUD_ML_REGION=us-east5import asyncioConfiguration des vars d'env pour le client Claude
from claude_agent_sdk import ClaudeSDKClient, ClaudeAgentOptions
async def main():
async with ClaudeSDKClient(
options=ClaudeAgentOptions(allowed_tools=["Read", "Edit", "Bash"])
) as client:
await client.query("Logs are showing a spike in 404, investigate.")
async for msg in client.receive_response():
print(msg)
asyncio.run(main())Initialisation d'un client ClaudeSDKClient
Autre approche observée chez Komodor : plutôt qu'un agent généraliste, une constellation d'agents hyper-spécialisés (Kubernetes, coût, placement de pods, drift management). Leur Klaudia Agentic AI annonce plus de 30 agents spécialisés on-call 24/7, et revendique 95% de précision sur le Root Cause Analysis automatisé. L'angle est intéressant : pour du cloud-native, la verticalité d'un agent expert bat souvent la polyvalence d'un agent généraliste.
💡 Bonus — les plateformes SRE les plus avancées élargissent le mandat de l'agent au-delà de la fiabilité : right-sizing des pods, placement intelligent, migration zéro downtime. L'agent ne se contente plus de réagir aux incidents, il optimise en continu la consommation du cluster. La frontière entre SRE et FinOps devient très fine.
Niveau 3 — Remédier (le palier critique)
Jusqu'ici, l'agent observait et analysait. On passe maintenant à la zone où il agit : redémarrer un service, vider un cache, rollback un déploiement, patcher une configuration. C'est le palier où tout le monde se tend — et pour de bonnes raisons. Un agent qui se trompe en lecture, ça produit un faux diagnostic. Un agent qui se trompe en action, ça produit un incident.
⚠️ La remédiation autonome n'est pas optionnellement encadrée — elle est sous contrainte par défaut.
Plusieurs garde-fous sortent du lot, systématiquement repris par les intervenants :
- Un contexte cadré au cordeau. On ne bascule pas l'agent en mode action avec le même prompt qu'en mode investigation. La liste des actions possibles, leur périmètre, les conditions qui les déclenchent : tout doit être explicite. Moins d'ambiguïté, moins de dérive.
- Un modèle premium. Pas de Haiku ni d'Opus "économique" à ce niveau. Le coût par décision est marginal comparé au coût d'une mauvaise action en production.
- Une relecture par un second modèle. Le plan de remédiation est généré par l'agent principal, puis relu par un autre modèle (parfois d'un autre fournisseur) qui joue l'avocat du diable : "ce plan est-il sûr ? y a-t-il un effet de bord ?". Simple, efficace, et ça rattrape beaucoup d'erreurs.
- Une approbation humaine conservée. Sur les actions à fort impact (restart d'un service critique, drop d'une connexion DB, rollback d'un déploiement récent), l'agent propose, l'humain valide. Le mode copilote reste la bonne approche par défaut — on n'enclenche le pilote automatique que sur des actions éprouvées, avec un périmètre défini.
Google a proposé une brique dédiée : une Gateway IA qui s'intercale entre l'agent et les systèmes cibles. Toute action passe par la gateway, qui valide (l'action est-elle dans la liste autorisée ?), audite (trace complète, horodatée, liée à l'alerte d'origine), et applique les politiques d'entreprise (RBAC, segmentation, rate limiting). En pratique, c'est le pattern API Gateway appliqué aux agents IA — sans cette couche, auditer ou retirer les privilèges d'un agent devient un cauchemar opérationnel.
💡 Un raccourci utile pour poser les bons réflexes : traitez votre agent SRE comme un stagiaire très doué. Il a toutes les compétences pour réagir, mais vous ne lui donnez pas le badge root direct. Vous commencez par du copilote, vous observez sa précision, vous élargissez le périmètre action par action. La Gateway IA, c'est ce qui vous permet de faire cette montée en confiance sans réécrire votre IAM à chaque itération.

Niveau 4 — Reporter et collaborer
Une remédiation réussie sans trace, c'est une demi-victoire. Un incident, ça ne s'arrête pas au service revenu en vert : il faut tracer, notifier, capitaliser. Et c'est aussi à ce niveau que l'humain et l'agent doivent cohabiter proprement.
Deux gestes concrets au programme.
Un ticket ServiceNow ouvert automatiquement — avec l'alerte d'origine, le diagnostic de l'agent, les actions tentées, les métriques avant/après. Pas de post-mortem rédigé trois jours plus tard par une main humaine épuisée : l'agent a tout le contexte en mémoire, il produit un premier jet exploitable dans la foulée. L'humain relit, corrige, publie.
Un thread Slack par incident. C'est le pattern qui revient le plus souvent, et c'est probablement la meilleure idée de tout ce qu'on a vu. Le principe : 1 incident = 1 thread. L'agent poste les updates dedans, les humains répondent dedans, les autres agents (triage, mitigation, RCA) écrivent dedans. Tout le monde travaille dans le même espace conversationnel, avec le même contexte sous les yeux.
Concrètement, ça change deux choses :
- L'humain reprend la main sans friction — il lit le thread, il voit ce que l'agent a fait, il peut intervenir à n'importe quel moment. Pas de console à ouvrir, pas de dashboard à corréler.
- L'agent garde la main sans cannibaliser — ses actions sont visibles, commentables, reprochables. Il reste un collaborateur dans la conversation, pas un service opaque qui pousse des commits dans votre dos.
C'est précisément l'architecture que PayPal a déployée : un superviseur qui orchestre, et des agents spécialisés pour chaque étape — Detection, Triage, Mitigation, RCA, Reporting, Communication. Chacun publie dans le thread, chacun est identifiable, chacun a un rôle clair.
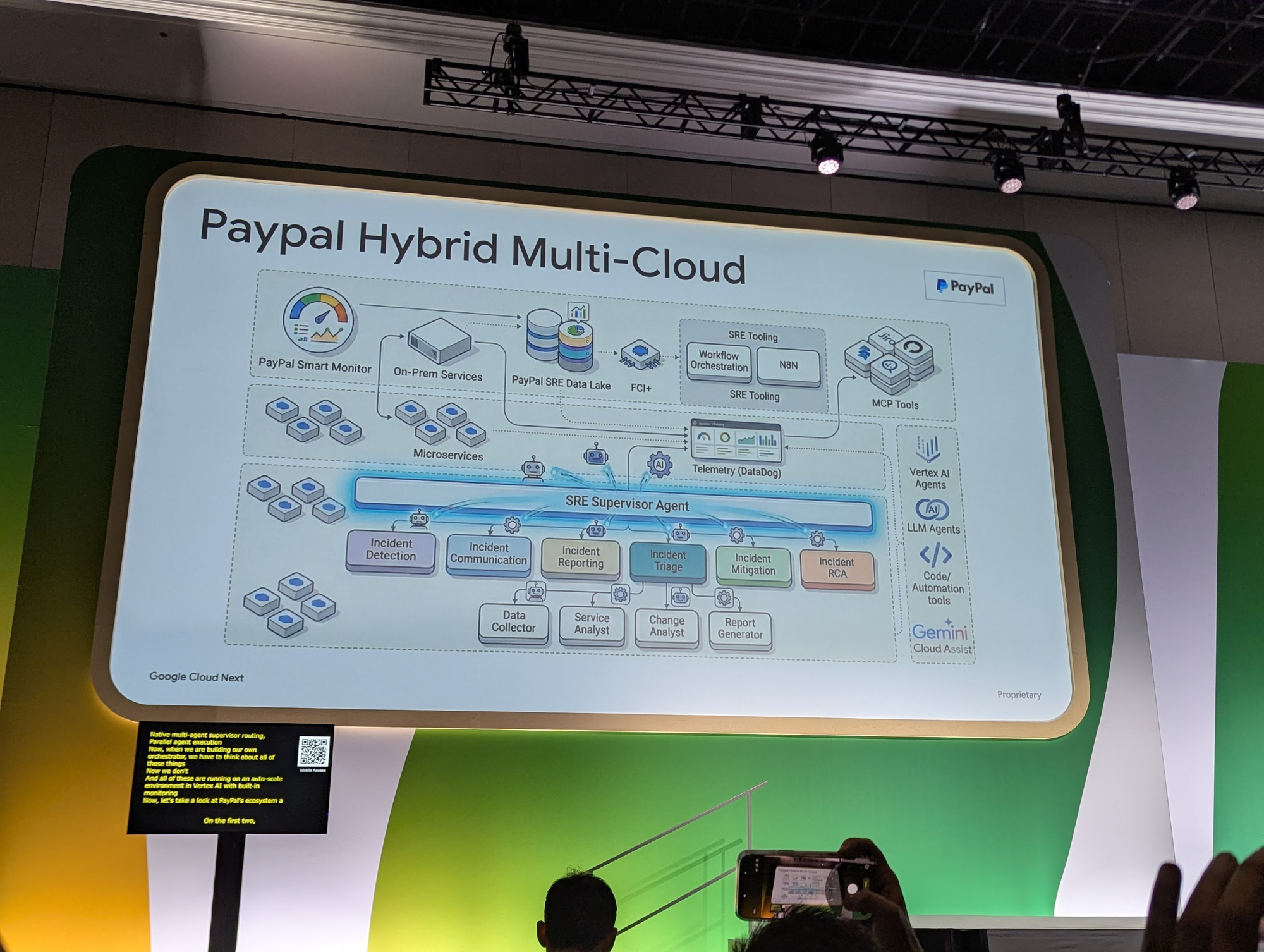
Le pattern multi-agent supervisé n'est pas un luxe architectural : c'est ce qui permet d'avoir un agent par spécialité, chacun avec son propre prompt, ses propres outils, son propre niveau d'autonomie. Et c'est ce qui rend l'industrialisation possible — ajouter un nouvel agent (Cost, Security, Capacity) devient un geste incrémental, pas une refonte.
Une variante tactique du même pattern mérite d'être isolée : un agent principal qui délègue la collecte à des sous-agents, chacun parti fouiller une source (logs, métriques, DB, historique des changes). Chaque sous-agent ramène un résumé — pas la donnée brute — et le passe au "tech lead" agentique, qui intègre ces synthèses dans son propre contexte pour prendre la décision. Deux effets : la collecte va plus vite (les sous-agents tournent en parallèle) et le contexte du décideur reste propre (il ne voit jamais les 10 000 lignes de logs, uniquement les éléments saillants). C'est le pattern que Komodor utilise nativement, et c'est une réponse directe au défi du Niveau 1 — fournir une vue complète sans noyer le contexte.
Niveau 5 — Prévenir (la cerise sur le gâteau)
⚠️ À clarifier d'entrée : ce niveau est ma projection personnelle. Il n'existe pas encore. Je ne l'ai vu ni en démo, ni en talk, ni sur un stand du Next. Aucun produit cité dans cet article ne propose ce scénario aujourd'hui. C'est la suite logique que je vois aux quatre niveaux précédents — pas un état de l'art à reproduire.
L'idée tient en une phrase : une fois l'incident clos, vous disposez d'un dossier complet — alerte initiale, diagnostic, root cause, actions de remédiation, métriques avant/après, timeline. Ce dossier serait un carburant parfait pour un agent de développement.
Dans ce scénario hypothétique, l'agent de dev recevrait tout le contexte et proposerait une évolution applicative pour empêcher la récurrence :
- Un circuit breaker sur l'appel fragile qui a cassé
- Un retry avec backoff exponentiel sur l'API tierce intermittente
- Un bulkhead pour isoler le thread pool qui a saturé
- Un SLO revu pour aligner l'alerting avec la réalité du service
- Un test de charge qui reproduit l'incident, intégré à la CI
Le changement serait proposé sous forme de pull request, avec l'incident en pièce jointe — le reviewer humain aurait toute l'histoire sous les yeux avant de merger.
Ce qui me pousse à l'évoquer, c'est que les briques existent séparément. Les agents de dev (Claude Code, Codex) savent lire un contexte, modifier du code, ouvrir une PR. Les agents SRE des niveaux 1 à 4 produisent déjà le dossier d'incident. Il manque le tuyau qui les relie — et surtout des retours d'expérience pour savoir où ça marche et où ça casse.
À suivre lors du prochain Next, peut-être. En attendant, considérez ce niveau comme une invitation à expérimenter, pas comme un chemin balisé.
À retenir
Quatre idées à remporter du Next :
- L'agent SRE n'est pas un projet monolithique. On gravit les niveaux un par un, on valide le contexte et les barrières à chaque étage. Viser d'emblée le niveau 3 sans avoir consolidé le 1 et le 2, c'est le chemin le plus court vers un incident causé par votre agent lui-même.
- Models / Context / Tooling sont indissociables. Un modèle premium sans tooling reste un chatbot. Du tooling sans contexte produit un agent qui tire partout. Du contexte sans modèle assez puissant flanche dans les cas limites.
- MCP est devenu l'autoroute. C'est la brique commune aux trois approches vues à Vegas : Anthropic expose ses outils, PayPal unifie ses 5+ sources de données sans migration, Komodor branche ses 30+ agents spécialisés. Si vous commencez aujourd'hui, vous commencez par un serveur MCP — pas par un LLM.
- La vraie promesse n'est pas "remplacer l'astreinte" mais absorber le bruit. Les niveaux 1 et 2 couvrent déjà 80% des alertes qui réveillent aujourd'hui un humain pour rien. Le métier de SRE ne disparaît pas — les incidents qui remontent enfin à vous sont ceux qui le méritent vraiment.

"Everyone can sleep well at night", promet la slide de clôture. La prime d'astreinte de niveau 1 et 2 a probablement du plomb dans l'aile — et honnêtement, personne ne la regrettera... ou pas. Le reste du métier de SRE, lui, reste entier : comprendre l'architecture, designer pour la panne, arbitrer les trade-offs, former les nouveaux, écrire les runbooks que lira demain un agent.
Ce qu'on pilote change. Ce qu'on cherche à protéger, non.






{kind=link}