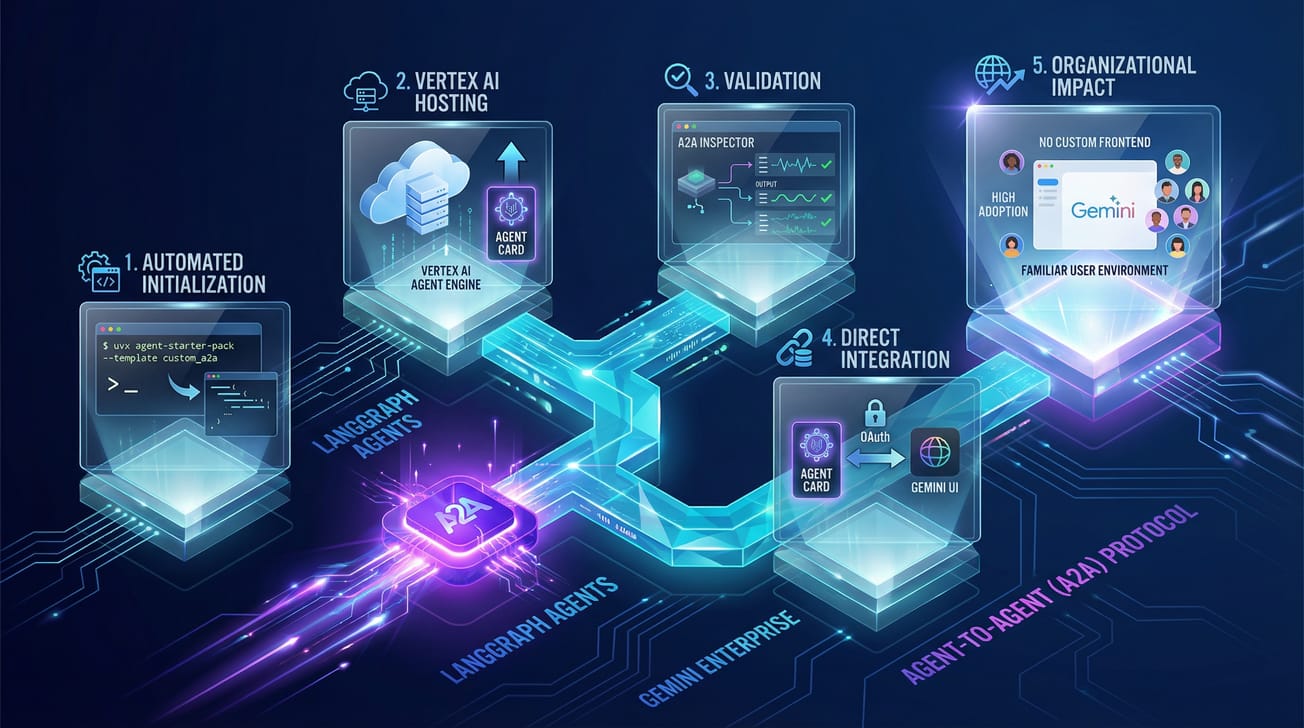
L'un des défis majeurs de l'IA générative en entreprise n'est plus seulement de créer des modèles performants, mais de les intégrer là où les collaborateurs travaillent. Comment connecter un agent complexe (backend) à une interface utilisateur fluide (frontend) sans développer une application web entière ?
J'ai récemment testé l'Agent Starter Pack pour déployer un agent LangGraph et l'intégrer via le protocole A2A dans Gemini Enterprise.
L'objectif : Passer du code Python à une conversation dans Gemini Enterprise en un temps record.
Voici le retour d'expérience, étape par étape.
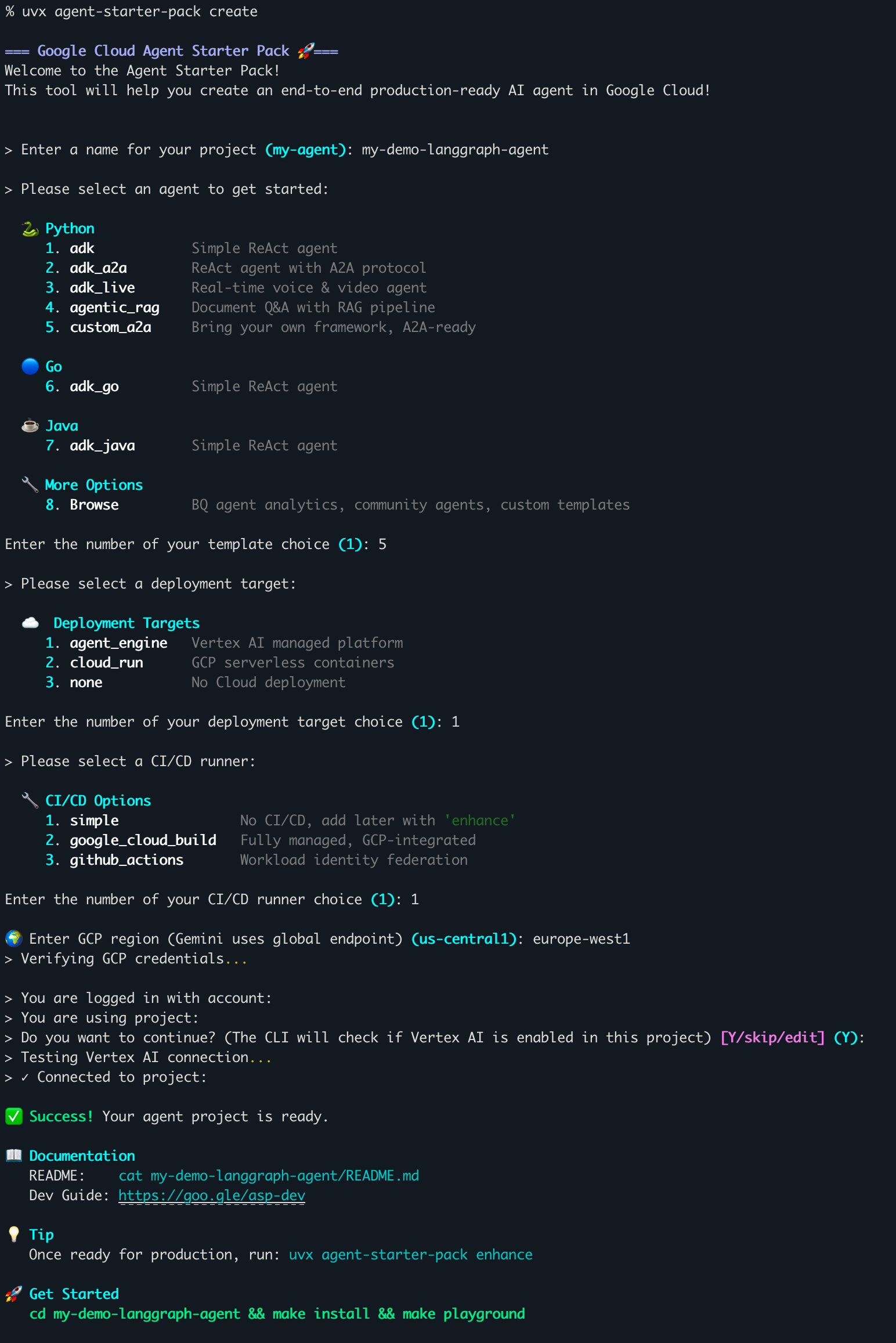
1. L'initialisation du projet : démarrage express
Tout commence dans le terminal. L'outil agent-starter-pack est conçu pour abstraire la complexité du boilerplate.
La commande magique : uvx agent-starter-pack create
L'assistant interactif m'a guidé vers une configuration robuste pour la production :
- Langage : Python.
- Template :
custom_a2a(Option 5) — C'est le choix crucial pour la démo avec LangGraph. - Cible : Vertex AI Agent Engine (Platform-managed).
- Région :
europe-west1.
Résultat : En quelques secondes, le dossier my-demo-langgraph-agent est généré avec l'architecture prête à l'emploi.
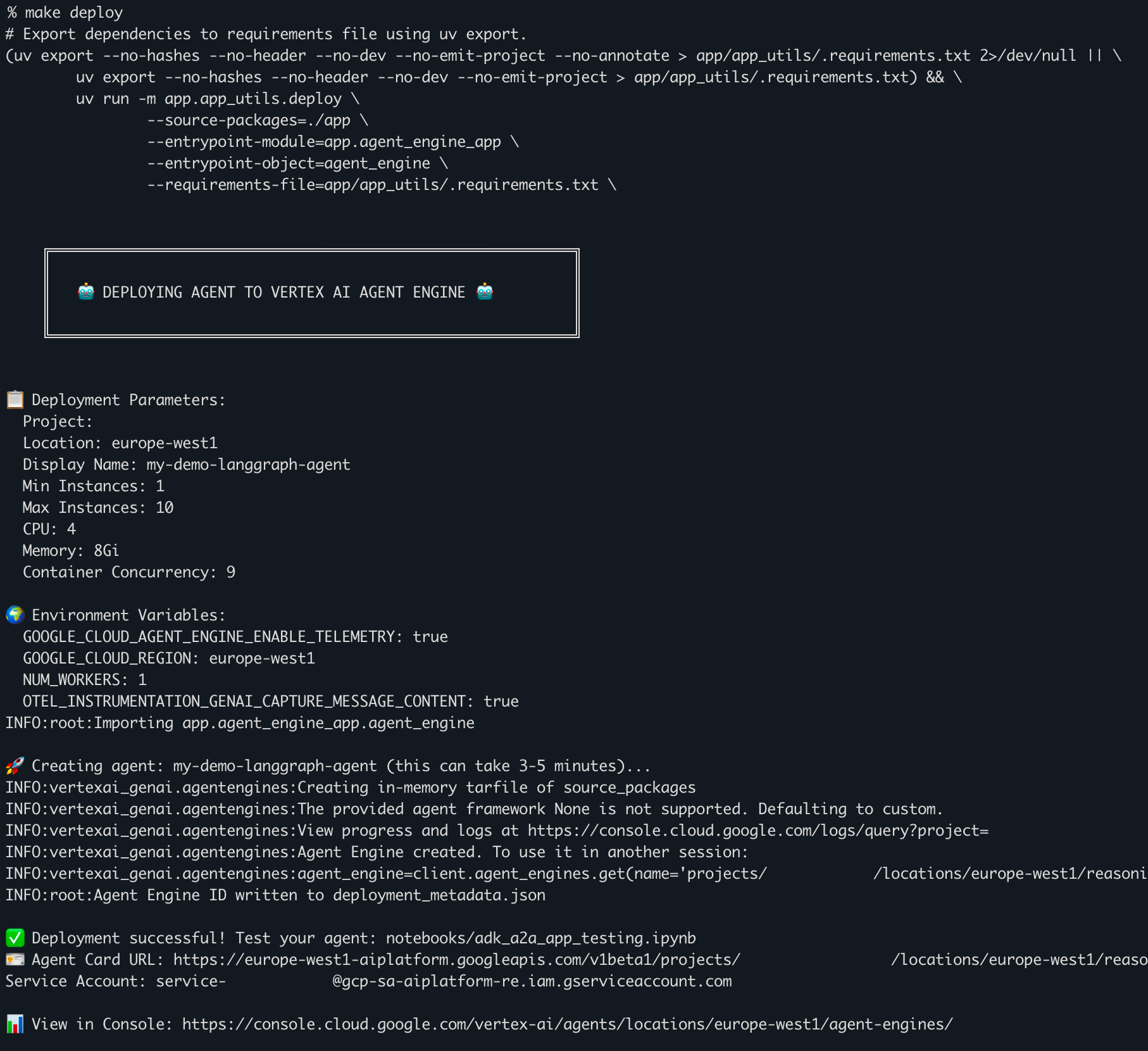
2. Le déploiement sur Vertex AI
Le Makefile inclus gère le cycle de vie complet (export des dépendances, packaging, déploiement).
make deploy
Les logs défilent : création de l'agent, allocation des ressources (4 vCPU, 8Gi RAM pour cet environnement de démo).
👀 Le point critique : à la fin du déploiement, le script retourne une Agent Card URL. Sauvegardez-la précieusement ! C'est la carte d'identité JSON que nous fournirons à Gemini Enterprise.
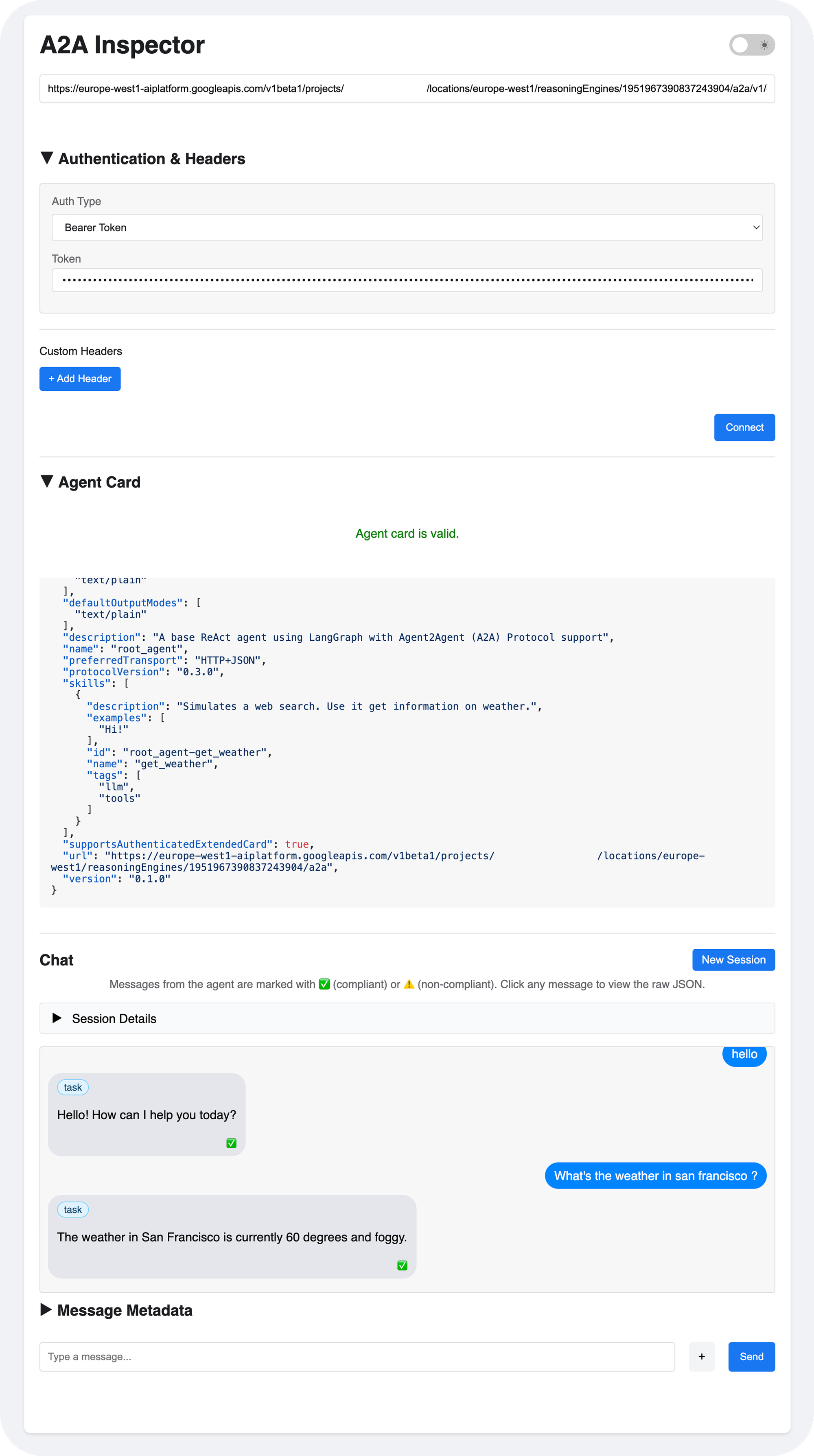
3. Validation avec l'A2A Inspector
Avant de brancher l'agent à l'interface utilisateur, il faut tester le "moteur". L'outil A2A Inspector permet de visualiser la "Skill" de l'agent.
On y retrouve les métadonnées définies dans le code :
- Nom :
root_agent - Skills :
get_weather(une fonction simulant une API météo)
J'ai testé avec le prompt : "What's the weather in San Francisco ?". Réponse immédiate de l'agent : "60 degrees and foggy". Le backend est fonctionnel.
4. Intégration dans Gemini Enterprise
C'est ici que l'expérience utilisateur prend tout son sens. Nous allons rendre cet agent accessible aux utilisateurs finaux directement dans leur interface Gemini Enterprise.
La procédure :
- Aller dans les paramètres d'agents de Gemini Enterprise.
- Sélectionner "Custom agent via A2A".
- Importer le JSON de l'Agent Card (récupéré à l'étape 2).
- Sécurité : configurer l'OAuth (Client ID / Client Secret) pour garantir que seuls les utilisateurs autorisés accèdent à l'agent.
L'aperçu valide instantanément la détection du root_agent.
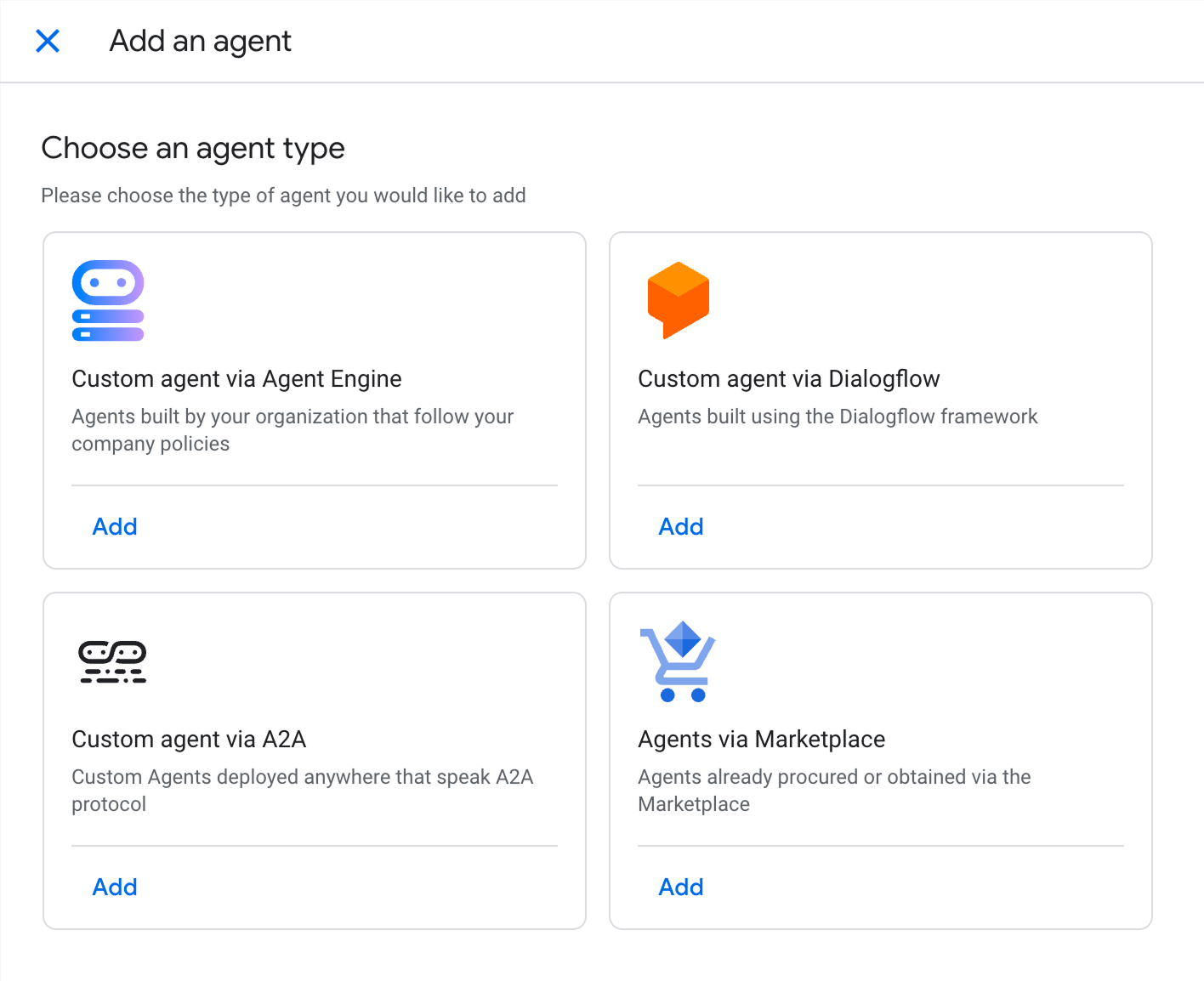
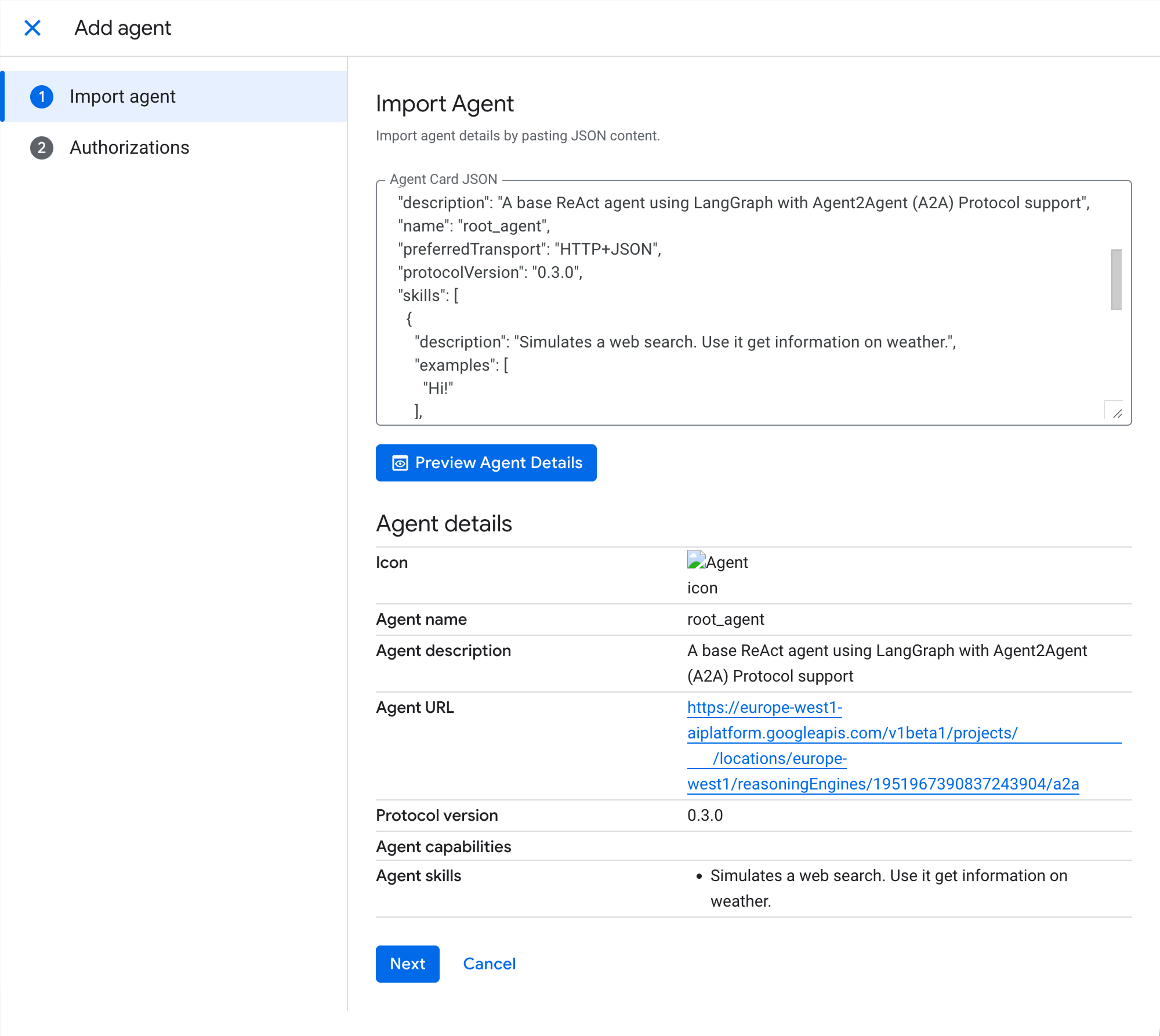
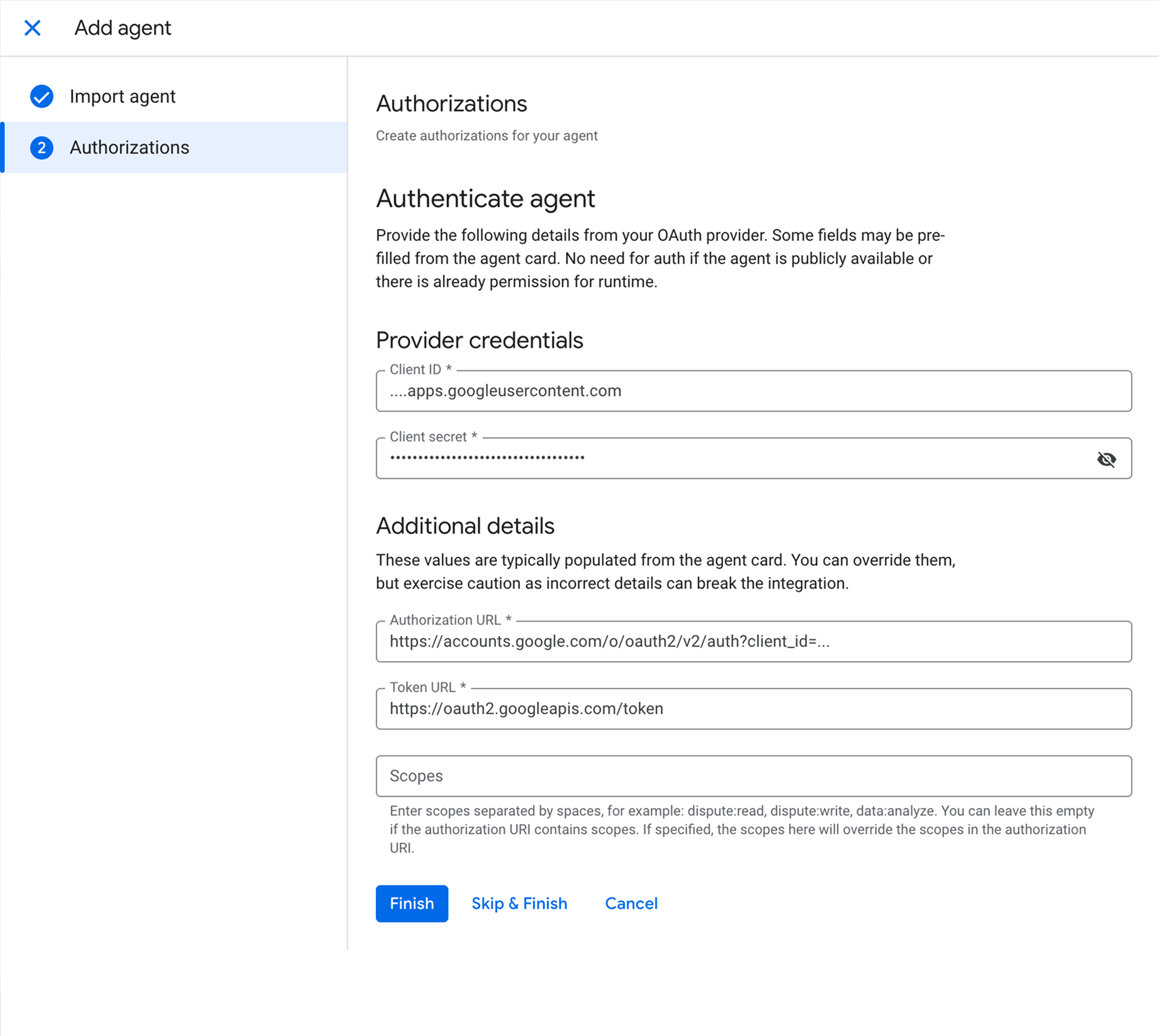
Enregistrement de l'agent dans Gemini Enterprise via A2A
5. Résultat final : une conversation fluide
Une fois activé, l'agent apparaît dans la liste des extensions disponibles (@root_agent) dans Gemini Enterprise.
Lors de la première sollicitation, Gemini demande une autorisation OAuth. Une fois validée, la barrière entre le modèle généraliste de Google et mon code Python disparaît.
User : "Quel temps fait-il à San Francisco ?" Gemini (via root_agent) : "Il fait actuellement 15°C avec du brouillard."
Gemini Enterprise a orchestré l'appel, l'agent LangGraph a exécuté la logique, et le résultat est revenu dans le chat.
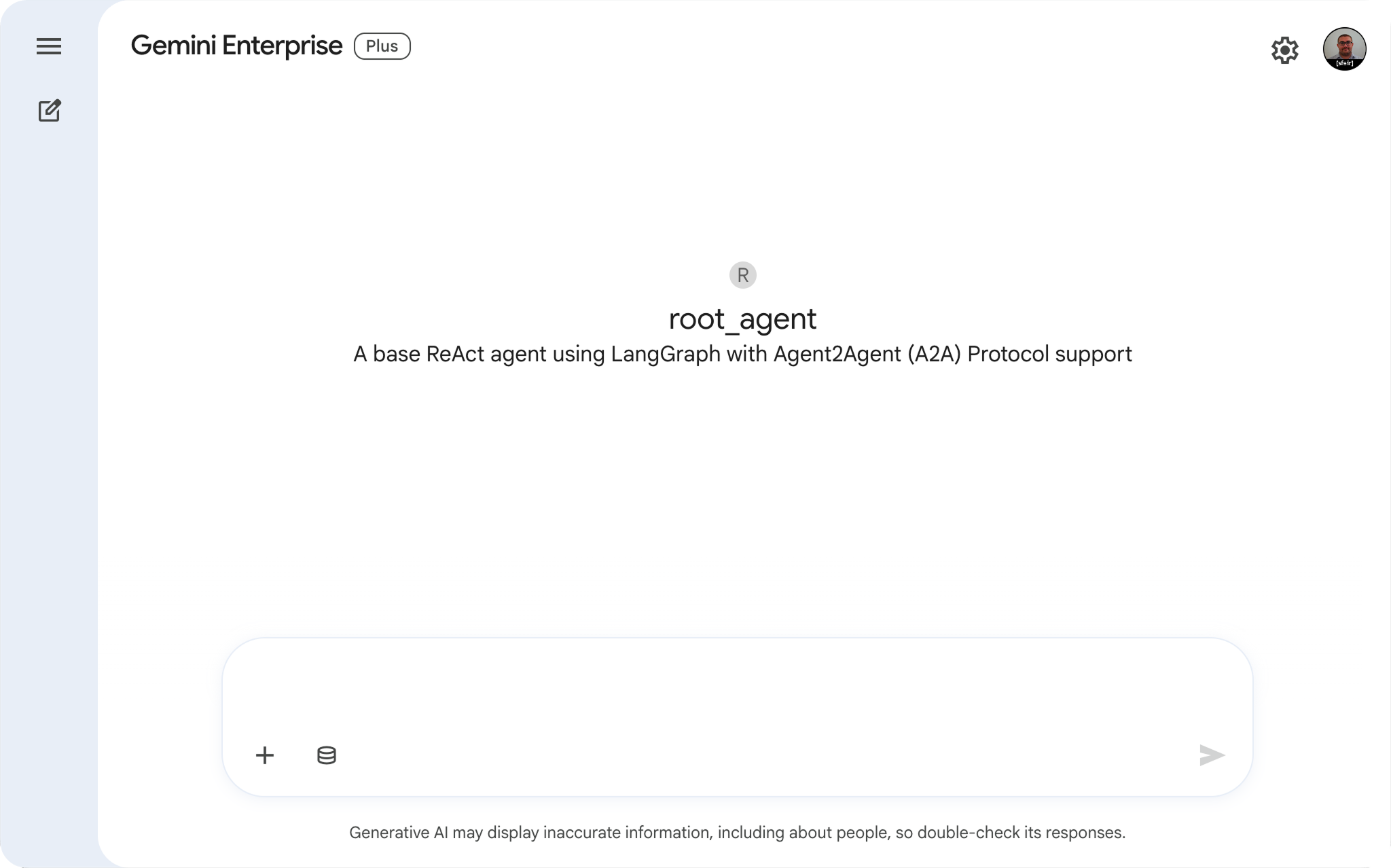
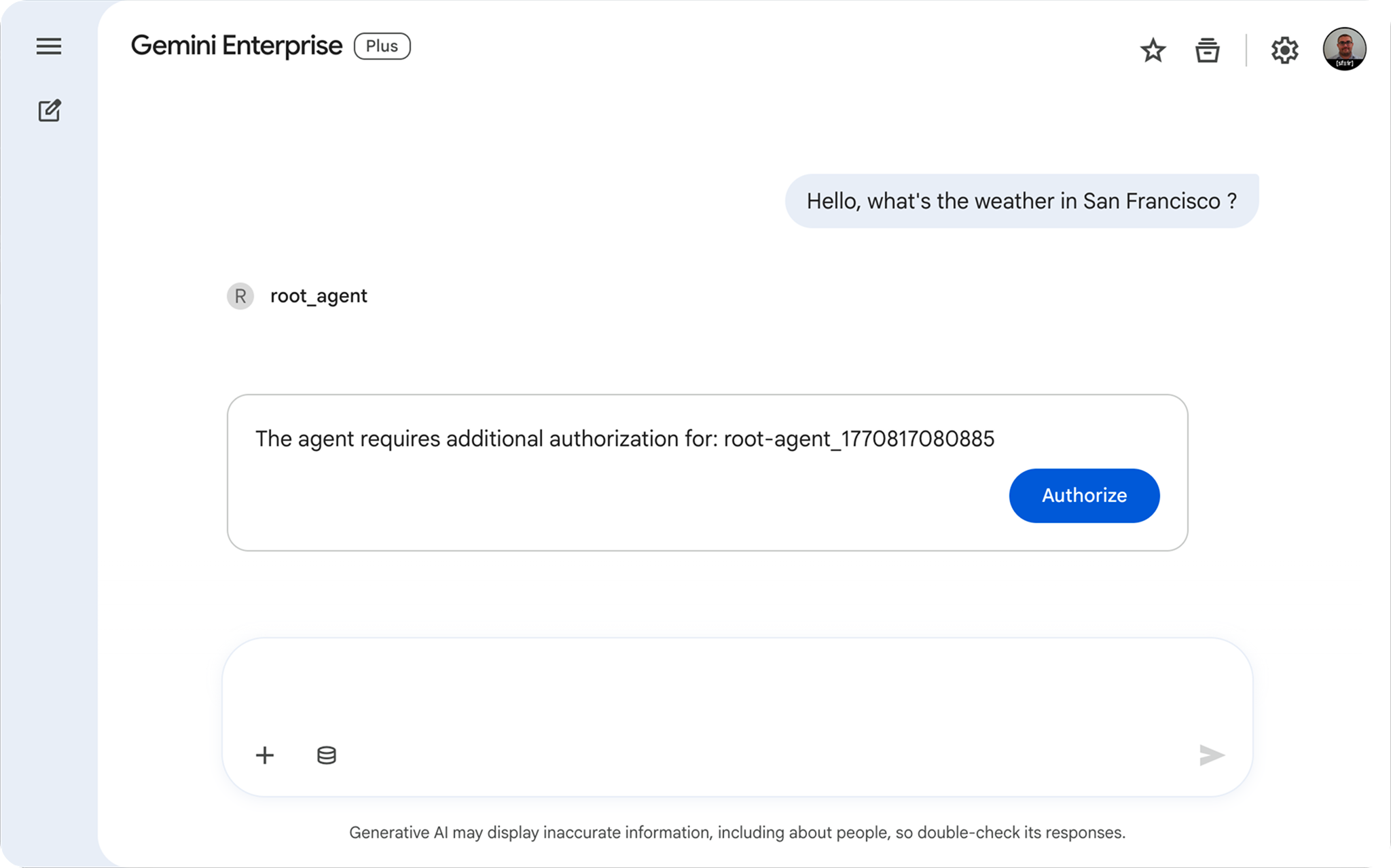
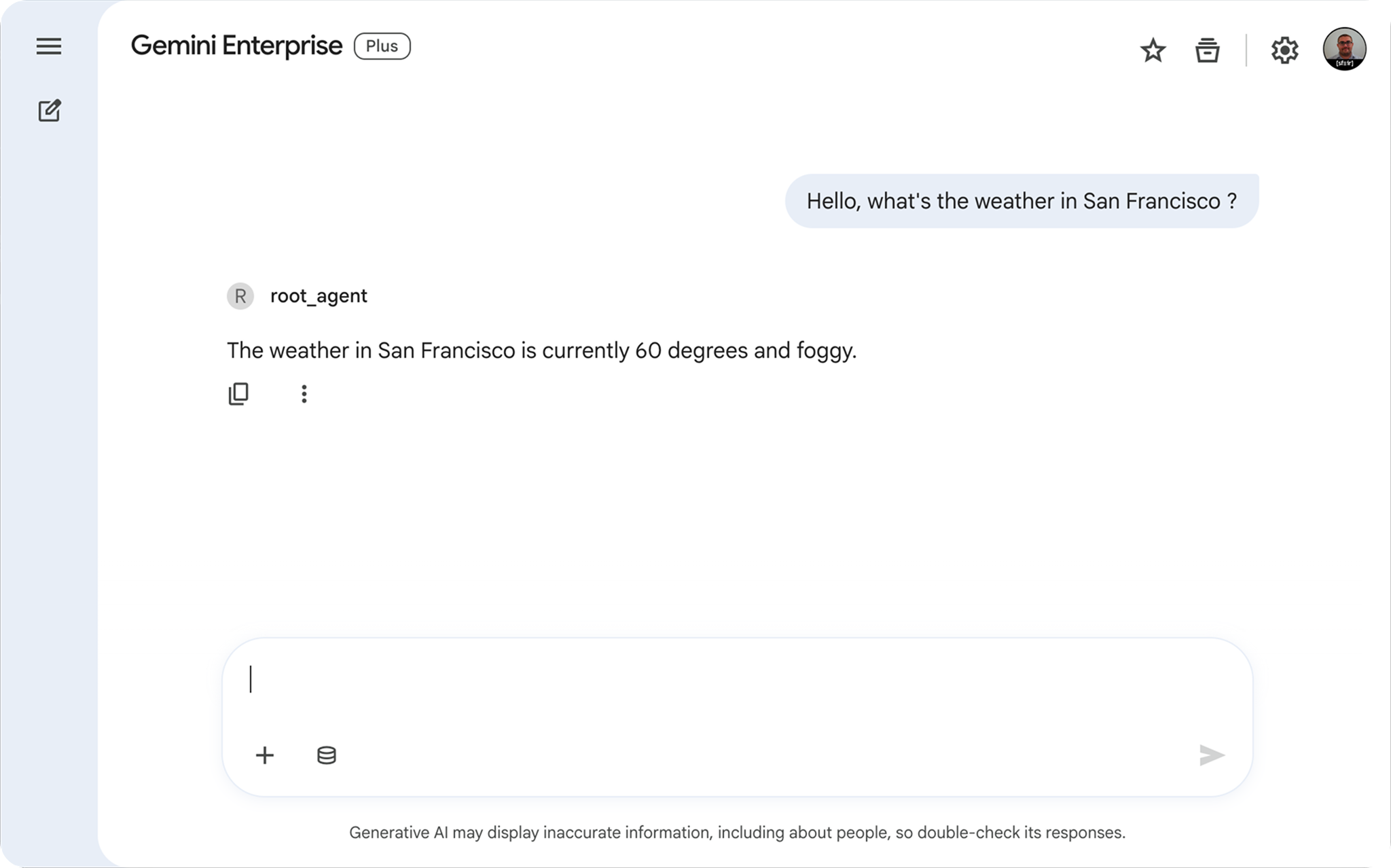
Tests de l'agent depuis l'interface utilisateur de Gemini Enterprise
Conclusion
Le combo LangGraph + Protocole A2A + Gemini Enterprise change la donne. Il supprime la nécessité de créer une interface frontend personnalisée pour vos outils internes.
En résumé :
- ✅ Rapidité : ~10 minutes du terminal au chat.
- ✅ Standardisation : utilisation de LangGraph pour la logique complexe.
- ✅ Adoption : l'utilisateur reste dans son environnement familier (Gemini Enterprise).






{kind=link}