
Le Harness Engineering (ou ingénierie du harnais) marque la fin de l’ère du "simple prompt". C’est la discipline qui consiste à concevoir l’écosystème, contraintes, outils, boucles de feedback et systèmes de vérification, nécessaire pour transformer des agents IA puissants mais imprévisibles en ouvriers logiciels fiables.
Popularisé par Mitchell Hashimoto fin 2025 et théorisé par Birgitta Böckeler (Thoughtworks) sur martinfowler.com en avril 2026, ce concept repose sur un constat simple : un agent seul dérive. Sans un cadre structurel, il accumule de l'entropie et échoue sur le long terme. Le Harness Engineering déplace le cœur du métier de développeur : on ne rédige plus le code, on architecture l'environnement où l'IA peut le produire en toute sécurité.
Ce changement de paradigme repose sur trois piliers :
- De l'écriture au contrôle : l'humain définit l'intention et les limites ; l'agent exécute.
- La maîtrise de l'entropie : le "harnais" empêche l'accumulation de code inutile lors des tâches longues.
- L'autonomie surveillée : permettre le passage à l'échelle sans sacrifier la maintenabilité du logiciel.
01 - Un agent n'est jamais seul
Agent = Modèle + Harness
Le harness désigne tout ce qui entoure le modèle : ce qui guide son comportement en amont, ce qui contrôle et corrige ses sorties en aval. Sans cela, un agent reste ce qu'il est fondamentalement : un générateur probabiliste de texte.
Trois limites structurelles des LLM rendent ce cadre nécessaire. Le non-déterminisme d'abord : une même requête peut produire des résultats différents d'une exécution à l'autre. L'absence de contexte métier implicite ensuite : l'agent ne sait pas que chez vous, on ne met pas de logique dans les controllers, que le bounded context "paiement" ne doit pas dépendre du bounded context "catalogue", ou que ce service-là a une contrainte de latence particulière. Enfin, leur mode de fonctionnement profond : ils prédisent le token suivant, ils ne "comprennent" pas le code au sens où un développeur senior le comprendrait.
Deux stratégies s'opposent alors. L'une consiste à attendre des modèles parfaits — plus puissants, mieux alignés, capables de tout inférer. L'autre consiste à construire dès maintenant le système de contrôle qui compense ces limites, quel que soit le modèle utilisé. Le harness engineering choisit la seconde voie. Et c'est un choix d'ingénierie, pas un choix de foi.
02 - Guides et capteurs : une mécanique de régulation
Un harness efficace repose sur deux types de mécanismes complémentaires.
Les guides (feedforward controls) orientent le comportement avant l'action : conventions documentées dans un fichier AGENTS.md, ADRs accessibles à l'agent, règles métier explicites, patterns d'architecture validés, how-to guides pour les opérations récurrentes. Leur objectif est de réduire l'espace des erreurs possibles — pas d'éliminer toute liberté, mais de contraindre intelligemment. Un agent qui sait que "toute nouvelle entité doit implémenter l'interface Auditable" n'a pas besoin qu'un humain lui rappelle à chaque PR.
Les capteurs (feedback controls) interviennent après coup. Tests automatisés, linters, analyse statique, vérification de types, ou même un LLM-as-a-judge pour les jugements sémantiques. Leur rôle : détecter les écarts et permettre une auto-correction avant que l'humain n'ait à intervenir.
Mais leur efficacité repose sur un point souvent négligé : leurs messages d'erreur doivent être exploitables par l'agent lui-même. Un bon capteur ne dit pas "violation de règle architecturale" — il dit "le module UserService importe PaymentRepository en violation de la règle ArchUnit domain-isolation. Déplacez cette dépendance vers un port d'interface." C'est la différence entre un signal et une instruction de correction. Böckeler appelle ça une "injection de prompt positive" : le capteur est lui-même un guide déguisé.
Séparément, ces deux mécanismes sont insuffisants. Un agent avec seulement des capteurs répète les mêmes erreurs jusqu'à ce qu'elles soient détectées — après coup. Un agent avec seulement des guides encode des règles sans jamais savoir si elles sont respectées. La combinaison est ce qui crée la boucle de régulation.
03 - Deux types de contrôle, deux philosophies
Chaque guide ou capteur peut opérer selon deux logiques fondamentalement différentes.
Les contrôles computationnels sont déterministes, rapides, fiables. Ils tournent sur CPU en millisecondes à secondes. Tests unitaires, typage, règles ArchUnit, linting, analyse de couverture, détection de duplication structurelle. Leur force : ils donnent le même résultat à chaque exécution, ils sont gratuits à l'échelle, et leurs messages sont précis. Leur limite : ils ne voient pas la sémantique.
Les contrôles inférentiels sont probabilistes, plus riches sémantiquement, plus coûteux. Ils tournent via un LLM — potentiellement le même modèle que l'agent, ou un modèle de review dédié. Review de code automatisée, analyse de cohérence métier, critique de design, détection de sur-ingénierie. Leur force : ils peuvent juger ce qu'aucune règle statique ne peut exprimer — "cette solution est techniquement correcte mais elle résout le mauvais problème". Leur limite : ils ne sont pas déterministes, ils coûtent des tokens, et ils ne peuvent pas tourner à chaque commit.
L'enjeu n'est pas de choisir, mais de combiner avec discernement. Le computationnel assure la sécurité quotidienne, à chaque changement, sans coût supplémentaire. L'inférentiel apporte le jugement là où les règles échouent, aux moments où ça vaut le coût. Un linter qui vérifie les imports à chaque commit, un agent de review qui analyse l'architecture globale une fois par semaine — c'est une stratégie, pas un remplacement.
04 - Exemple concret : un harness minimal viable
Prenons un service backend classique — disons un service Java/Spring qui expose une API REST, consomme des événements Kafka, et persiste dans PostgreSQL. Comment construire un harness minimal mais sérieux ?
Les guides commencent par un AGENTS.md à la racine du projet, où l'on documente les conventions non négociables : architecture en couches (controller → use case → domain → repository), nommage des packages, règles d'import entre bounded contexts, conventions de logging. On y ajoute les ADRs pertinents — pas tous, ceux qui ont des conséquences sur le code quotidien. Et des how-to guides pour les opérations récurrentes : "comment créer un nouvel endpoint", "comment ajouter un consumer Kafka", "comment écrire un test d'intégration avec Testcontainers".
Les capteurs computationnels incluent une suite de tests unitaires avec une couverture minimale enforced (disons 80%, mais avec mutation testing pour s'assurer que les tests ont une valeur réelle et pas juste une couverture cosmétique), des règles ArchUnit qui vérifient les frontières de modules ("aucune classe du package infrastructure ne peut importer depuis domain"), un linter configuré avec des règles personnalisées qui produisent des messages lisibles par un LLM, et un check de formatage. Tout ça tourne en pré-commit, en moins de 30 secondes.
Les capteurs inférentiels : un agent de review en PR qui a accès aux guides (il reçoit le contenu de AGENTS.md dans son contexte) et qui cherche spécifiquement les violations sémantiques que les outils statiques ne voient pas — sur-ingénierie, misdiagnose du problème, convention respectée à la lettre mais violée dans l'esprit. Il tourne une fois par PR, pas à chaque commit.
Le résultat : un agent qui n'est pas seulement productif — mais contraint intelligemment, avec une boucle de correction qui fonctionne avant que l'humain n'ait à intervenir dans 80% des cas.
05 - Déplacer la qualité vers l'amont
Le principe est connu en DevOps : plus une erreur est détectée tôt, moins elle coûte à corriger. Avec les agents IA, cette logique devient critique — et prend une nouvelle dimension, parce que l'agent lui-même peut participer à la correction si le signal lui est donné assez tôt.
Une distribution typique des contrôles sur le cycle de vie ressemble à ceci.
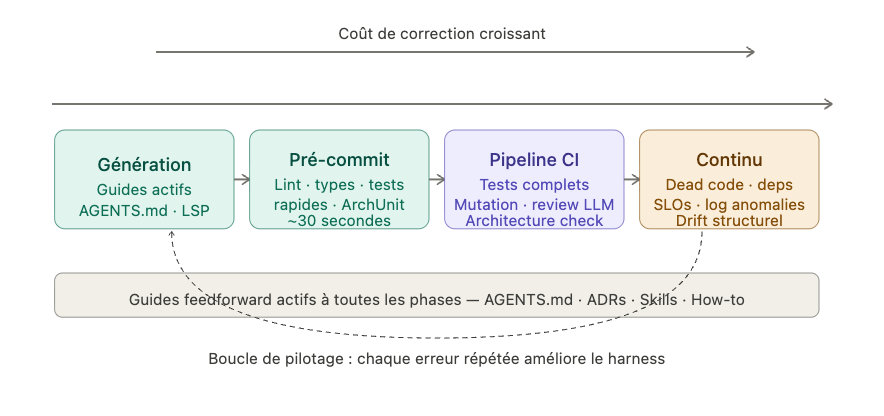
Le vrai danger à surveiller est la dérive invisible. Un agent peut produire du code valide, bien typé, avec des tests qui passent — et pourtant incorrect sur le plan architectural ou métier. Il a optimisé localement en violant une règle globale. Les tests passent parce que les tests ne testaient pas ça. Le linter passe parce que la règle n'était pas codifiée. C'est précisément ce que le harness doit capter, et c'est là que les capteurs inférentiels justifient leur coût.
06 - Trois niveaux à maîtriser
Un bon harness agit sur trois dimensions distinctes, avec des niveaux de maturité très différents aujourd'hui.
La maintenabilité est la dimension la plus maîtrisée. Les outils classiques fonctionnent bien ici : duplication de code, complexité cyclomatique, couverture de tests, violations de style. Les capteurs computationnels attrapent le structurel de façon fiable et déterministe. Les capteurs inférentiels ajoutent une couche sémantique : code fonctionnellement dupliqué (même algorithme, noms différents), tests redondants, solutions techniquement correctes mais sur-ingénierées. Mais ni les uns ni les autres ne rattrapent de façon fiable les erreurs de diagnostic — l'agent qui résout le bon bug dans le mauvais endroit, ou qui implémente une feature que personne n'a vraiment demandée. Pour ça, la spécification humaine reste indispensable.
L'architecture fitness regroupe les guides et capteurs qui maintiennent les propriétés architecturales de l'application. Böckeler s'appuie ici sur le concept de Fitness Functions de Neal Ford : des tests automatisés qui vérifient non pas le comportement fonctionnel, mais les propriétés architecturales. Est-ce que les dépendances entre modules respectent les règles définies ? Est-ce que les temps de réponse restent dans les enveloppes spécifiées ? Est-ce que les conventions de logging permettent un débogage efficace ? Ces propriétés peuvent être à la fois des guides (le skill qui explique comment écrire des logs structurés) et des capteurs (l'agent qui vérifie après coup que les logs générés permettraient réellement de debugger un incident).
Le comportement fonctionnel est l'angle mort. C'est la question fondamentale : comment s'assurer que l'application fait ce qu'elle est supposée faire ? La réponse actuelle de la plupart des équipes avancées combine une spécification fonctionnelle en feedforward et une suite de tests générée par l'agent en feedback. Le problème est structurel : un agent qui génère ses propres tests reste juge et partie. Il va naturellement écrire des tests qui valident son implémentation, pas des tests qui challengent ses hypothèses. Les tests passent parce que l'agent a implémenté ce qu'il a compris de la spec — qui n'est peut-être pas ce que vous vouliez. Le pattern "approved fixtures" (où des fixtures de référence validées par des humains servent de ground truth pour les tests) montre des résultats prometteurs dans certains contextes, mais il n'existe pas encore de réponse universelle à ce problème.
07 - La harnessabilité : une nouvelle dimension d'architecture
Toutes les codebases ne se laissent pas harnacher avec la même facilité. C'est une réalité qui doit influencer vos décisions techniques — pas uniquement en rétrospective, mais dès le début d'un projet.
Prenons deux codebases comparables en taille et complexité métier.
La première est un service Java/Spring avec du typage fort, des frontières de modules clairement définies par packages, des conventions explicitement documentées, et une architecture en couches respectée. Les guides s'écrivent naturellement (les règles sont déjà formalisées). Les capteurs computationnels sont puissants (ArchUnit peut vérifier n'importe quelle contrainte de dépendance). Le compilateur lui-même est un capteur. Harnessabilité haute.
La seconde est un monolithe Python legacy, dynamiquement typé, avec des dépendances circulaires, des conventions tacites jamais écrites, et une logique métier dispersée entre des scripts, des celery tasks et des vues Django. Les guides sont difficiles à écrire (les règles n'existent qu'implicitement dans la tête des anciens). Les capteurs computationnels sont faibles (pas de types à vérifier, pas de frontières à enforcer). L'agent va produire du code "dans le style local" uniquement s'il en a vu suffisamment en contexte. Harnessabilité basse.
Ned Letcher (Thoughtworks) utilise le terme "ambient affordances" pour désigner ces propriétés structurelles d'un environnement qui le rendent plus lisible, navigable et traçable par les agents. C'est une nouvelle dimension d'évaluation à ajouter à vos décisions d'architecture — au même titre que la testabilité ou la scalabilité.
Le corollaire inconfortable : le harness est le plus nécessaire là où il est le plus difficile à construire. Les équipes avec une dette technique importante ont le plus besoin de contrôle sur leurs agents, et le moins de propriétés sur lesquelles s'appuyer pour le construire. Il n'y a pas de solution magique ici — mais identifier ce problème est déjà un premier pas.
08 - Standardiser : vers des harness templates
Les organisations qui opèrent à l'échelle convergent naturellement vers des topologies de services récurrentes : API CRUD qui exposent des données, processeurs d'événements, pipelines data, dashboards analytiques. Dans les organisations matures, ces topologies sont souvent déjà codifiées dans des service templates — un point de départ standardisé qui garantit une structure et un stack cohérents.
L'étape suivante naturelle : associer à chaque topologie un harness template. Un bundle guides + capteurs prêt à l'emploi, adapté à la structure, aux conventions et au stack de cette topologie. Une équipe qui démarre un nouveau service CRUD en Java récupère avec son template non seulement la structure de projet et les dépendances, mais aussi l'AGENTS.md pré-rempli, les règles ArchUnit adaptées, le skill de review configuré, et les how-to guides pour les opérations courantes de ce type de service.
La loi d'Ashby (Law of Requisite Variety) donne un argument cybernétique solide pour cette approche : un régulateur doit avoir au moins autant de variété que le système qu'il gouverne. Un agent LLM peut techniquement produire n'importe quoi — s'engager sur une topologie réduit cet espace de possibles et rend un harness complet atteignable.
Il faut être honnête sur les défis que ça implique. Les harness templates feront face aux mêmes problèmes que les service templates : dérive par rapport à l'upstream au moment de l'instanciation, questions de contribution et de gouvernance, versioning. Avec des guides et capteurs partiellement non-déterministes (les capteurs inférentiels, notamment), ces défis pourraient même être plus complexes à gérer — comment tester qu'un guide produit les bons comportements si ce guide est lui-même probabiliste ?
09 - Le rôle humain ne disparaît pas — il se déplace
En tant que développeurs humains, nous apportons à chaque codebase un harness implicite. Des conventions absorbées par osmose, une mémoire du système qui va au-delà de ce qui est documenté, une intuition du "bon goût" en matière de design, une accountability sociale (notre nom est sur le commit), et une conscience organisationnelle — savoir quelle dette technique est tolérée pour des raisons business, ce que l'équipe essaie d'accomplir cette sprint, ce qui est "chargé" politiquement et mérite d'être traité avec précaution.
Un agent de coding n'a rien de tout ça. Pas de dégoût esthétique face à une fonction de 300 lignes. Pas d'intuition "on ne fait pas ça ici". Pas de mémoire de la fois où on avait essayé cette approche et abandonné pour de bonnes raisons. Pas de conscience que la convention X est structurante pendant que la convention Y est juste une habitude historique.
Le harness est une tentative d'externaliser et rendre explicite ce savoir tacite. Mais il ne peut pas tout capturer — et c'est bien. Son rôle n'est pas d'éliminer l'intervention humaine, mais de la diriger là où elle est le plus précieuse.
Ce qui change concrètement dans le travail du développeur : moins écrire du code, plus concevoir le système qui produit le code. La nouvelle boucle ressemble à ceci. Un problème survient. L'agent le produit une fois. Si c'est isolé, on corrige le code. Si ça se répète, on améliore le harness — on ajoute un guide pour que l'agent ne prenne plus cette décision sans contexte, ou un capteur pour détecter l'écart automatiquement. Et on utilise l'agent pour améliorer le harness lui-même : rédiger des tests structurels, générer des règles de linting à partir de patterns observés, créer des how-to guides par archéologie de la codebase.
10 - Ce que font les équipes avancées
Le harness engineering n'est pas une théorie — des équipes de premier plan ont déjà documenté leurs approches, avec des conclusions convergentes.
OpenAI a publié une description de leur harness interne : architecture en couches renforcée par des linters custom et des tests structurels, et un processus de "garbage collection" récurrent qui scanne la dérive et laisse des agents suggérer des corrections. Leur conclusion est frappante : leurs défis les plus difficiles se concentrent maintenant sur la conception d'environnements, de boucles de feedback et de systèmes de contrôle — pas sur les modèles eux-mêmes.
Stripe décrit dans leur write-up sur les "minions" des hooks pré-push qui exécutent les linters pertinents selon une heuristique, et des "blueprints" qui intègrent des capteurs de feedback directement dans les workflows agents. Leur insistance sur le "shift feedback left" est centrale dans leur approche.
Du côté de Thoughtworks, des expériences de lutte contre la dérive architecturale combinent capteurs computationnels et inférentiels : amélioration de la qualité des APIs avec des agents et des linters custom, amélioration de la qualité de code avec ce qu'ils appellent des "janitor armies" — des agents qui tournent en continu sur la codebase pour détecter et corriger la dérive.
Deux tendances émergent également dans la communauté plus large : le mutation testing et les tests structurels — sous-utilisés pendant des années — connaissent une renaissance dans ce contexte. Et les LSPs (Language Server Protocols) commencent à être intégrés directement dans les agents comme guides feedforward computationnels, donnant à l'agent une compréhension plus riche de la structure du code.
11 - Le coût qu'on ne doit pas ignorer
Il serait malhonnête de présenter le harness engineering sans aborder son coût réel. Böckeler le formule clairement dans son article original : construire un système cohérent de guides, capteurs et boucles d'auto-correction est coûteux. Ce n'est pas une configuration one-shot — c'est une pratique d'ingénierie continue.
Il faut écrire et maintenir les guides (qui se démodent, qui divergent de la réalité). Il faut concevoir des capteurs qui produisent des messages exploitables par un LLM (pas juste des messages d'erreur pour des humains). Il faut maintenir la cohérence entre guides et capteurs au fur et à mesure que le harness grandit — éviter que guide A et capteur B se contredisent. Il faut tester le harness lui-même — savoir si les capteurs détectent vraiment ce qu'ils sont censés détecter, et si les guides produisent vraiment les comportements attendus.
L'objectif n'est donc pas de construire le harness parfait dès le départ. C'est de construire un harness minimal viable, de l'itérer à chaque erreur répétée, et de prioriser avec une question claire en tête : où l'intervention humaine est-elle la plus précieuse ? Là où la réponse est "partout", le harness n'est pas assez développé. Là où la réponse est "nulle part", on est en train de se raconter des histoires.
12 - Questions encore sans réponse
Le harness engineering est une discipline en construction. Plusieurs questions restent largement ouvertes.
Comment mesurer la qualité d'un harness ? Le code coverage donne une métrique imparfaite mais utile pour les tests. Il n'existe pas encore d'équivalent pour les harnesses — pas de "harness coverage" qui dirait si vos guides et capteurs couvrent les vrais modes de défaillance de votre agent.
Comment éviter les contradictions entre guides et capteurs quand le système grandit ? Guide A dit "préfère la composition à l'héritage", capteur B détecte les classes sans héritage et suggère d'en ajouter. Ces contradictions sont difficiles à détecter automatiquement.
Jusqu'où déléguer l'arbitrage aux agents ? Quand un capteur détecte un écart et qu'un guide pointe dans une direction différente, qui tranche ? L'agent ? Un humain ? Un méta-guide ?
Comment maintenir ces systèmes dans le temps, notamment les guides inférentiels dont les comportements sont plus difficiles à tester ? Comment versionner un harness template quand des équipes l'ont instancié et en ont divergé ?
Conclusion
Le harness engineering n'est pas une promesse technologique de plus mais une forme de retour à l'essentiel : appliquer des principes d'ingénierie éprouvés (feedback loops, séparation des préoccupations, testabilité by design, détection précoce...) à des systèmes devenus, soudainement, imprévisibles.
Le passage de "j'utilise un agent" à "j'opère un système d'agents en production" n'est pas un passage de degré mais un passage de nature. Et dans ce passage, la vraie compétence redevient peut-être celle-ci : construire des systèmes dans lesquels on peut, raisonnablement, avoir confiance !





{kind=link}