
Le problème : trop de tools, trop de tokens
Vous branchez un serveur MCP Grafana sur votre agent. Dans notre test, ~50 définitions de tools atterrissent d'un coup dans le contexte : search_dashboards, alerting_manage_rules, list_datasources... et des dizaines d'autres. Chaque requête au LLM embarque ces schemas JSON, qu'ils soient utiles ou non pour la tâche en cours.
L'impact est double en pratique :
En tokens ($) d'une part : les définitions de tools sont facturées en input à chaque appel.
En qualité ensuite : plus le contexte est chargé, plus le modèle doit trier le signal du bruit — ce qu'Anthropic appelle le context rot. Et quand il a besoin de 5 actions séquentielles, ça fait 5 round-trips LLM — avec les ~50 schemas renvoyés à chaque fois dans notre cas
Dans un setup avec tools, chaque appel d’outil déclenche généralement un nouveau round-trip — donc plus il y en a, plus on paie en latence et en tokens.
Anthropic a documenté un pattern qui change l'approche : au lieu d'exposer N tools au LLM, on lui donne 1 seul tool : execute_code. Les outils deviennent des fonctions importables dans un sandbox d'exécution. Le LLM écrit un script complet qui enchaîne les appels. On a donc plusieurs actions API en un seul round-trip, au lieu d'un aller-retour par action !
Sur le papier ça à l'air top... j'ai alors voulu vérifier par moi même. Même use case, 3 configurations et des vrais chiffres.
execute_python plus simple. Le pattern est identique — c'est l'implémentation du sandbox qui change, pas le principe.Le test : 3 façons de créer un dashboard Grafana
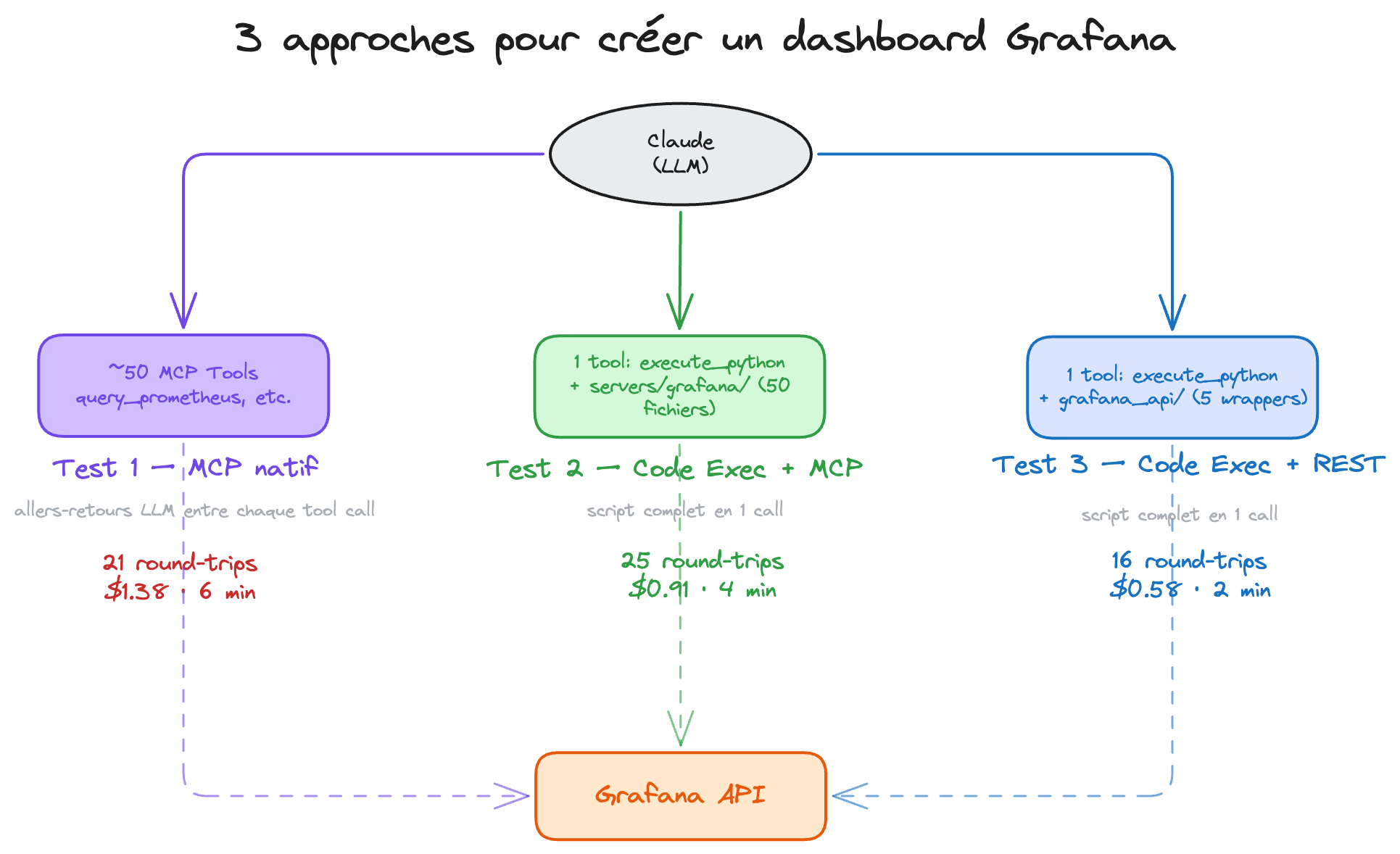
Pour comparer les approches, on va donner le même prompt à Claude Code dans 3 configurations différentes. L'objectif : créer un dashboard Grafana fonctionnel, de bout en bout, sans intervention humaine.
session.id par exécution. On lance les 3 tests en parallèle en Multi Agent (chaque agent = une session isolée) avec sa config MCP puis on compare les métriques dans Grafana. Pas de mesure à la main, tout passe par la télémétrie OTLP.Le twist : un test qui se mesure lui-même
Plutôt qu'un dashboard générique, on demande à chaque agent de créer un dashboard de comparaison de sessions Claude Code. Les métriques à visualiser ? Celles de la télémétrie Claude Code elle-même — tokens, coût, temps actif. Chaque test produit l'outil qui permet de mesurer... les 3 tests.
Le prompt commun
Crée un dashboard Grafana de benchmark comparatif des sessions Claude Code.
La datasource Prometheus est "thanos". Claude Code exporte sa télémétrie
via OpenTelemetry vers cette datasource (OTLP → Thanos Receive).
Le dashboard doit permettre de comparer visuellement :
- La consommation de tokens (par type si possible)
- Le coût
- Le temps actif
- Un tableau récapitulatif
Commence par explorer les métriques disponibles pour trouver celles
qui sont pertinentes. Les noms de métriques commencent par claude_code_.
Rends les légendes lisibles.
Même objectif pour les 3 tests — pas de PromQL fourni, le LLM doit explorer l'interface qu'on lui expose
Les 3 tests tournent sur Claude Opus 4.6 (effort auto) via Claude Code, en mode non-interactif.
Test 1 — MCP Grafana natif
Setup
Le serveur MCP Grafana charge ses ~50 tools directement dans le contexte de Claude Code.
.mcp.json (à la racine du projet) :
{
"mcpServers": {
"grafana": {
"command": "uvx",
"args": ["mcp-grafana"],
"env": {
"GRAFANA_URL": "https://grafana.example.com",
"GRAFANA_SERVICE_ACCOUNT_TOKEN": "<your-token>"
}
}
}
}
Configuration MCP Grafana natif — le serveur expose tous ses tools directement
Ce qui se passe
Claude Code voit ~50 définitions de tools dans son contexte :
search_dashboards,update_dashboard,patch_dashboardlist_datasources,query_prometheusalerting_manage_rules,list_oncall_schedules- ... et plusieurs dizaines d'autres qu'il n'utilisera jamais pour cette tâche
Chaque action = 1 tool call = 1 round-trip LLM :
→ list_datasources() # round-trip 1
← [{name: "thanos", type: "prometheus", ...}]
→ query_prometheus({expr: "up"}) # round-trip 2
← [...]
→ query_prometheus({expr: "{__name__=~'.+'}"}) # round-trip 3
← [...]
→ update_dashboard({dashboard: {...}}) # round-trip 4
← {uid: "abc123", url: "/d/abc123"}
→ get_dashboard_by_uid({uid: "abc123"}) # round-trip 5
← {...}
Flux MCP natif — chaque action est un aller-retour LLM séparé
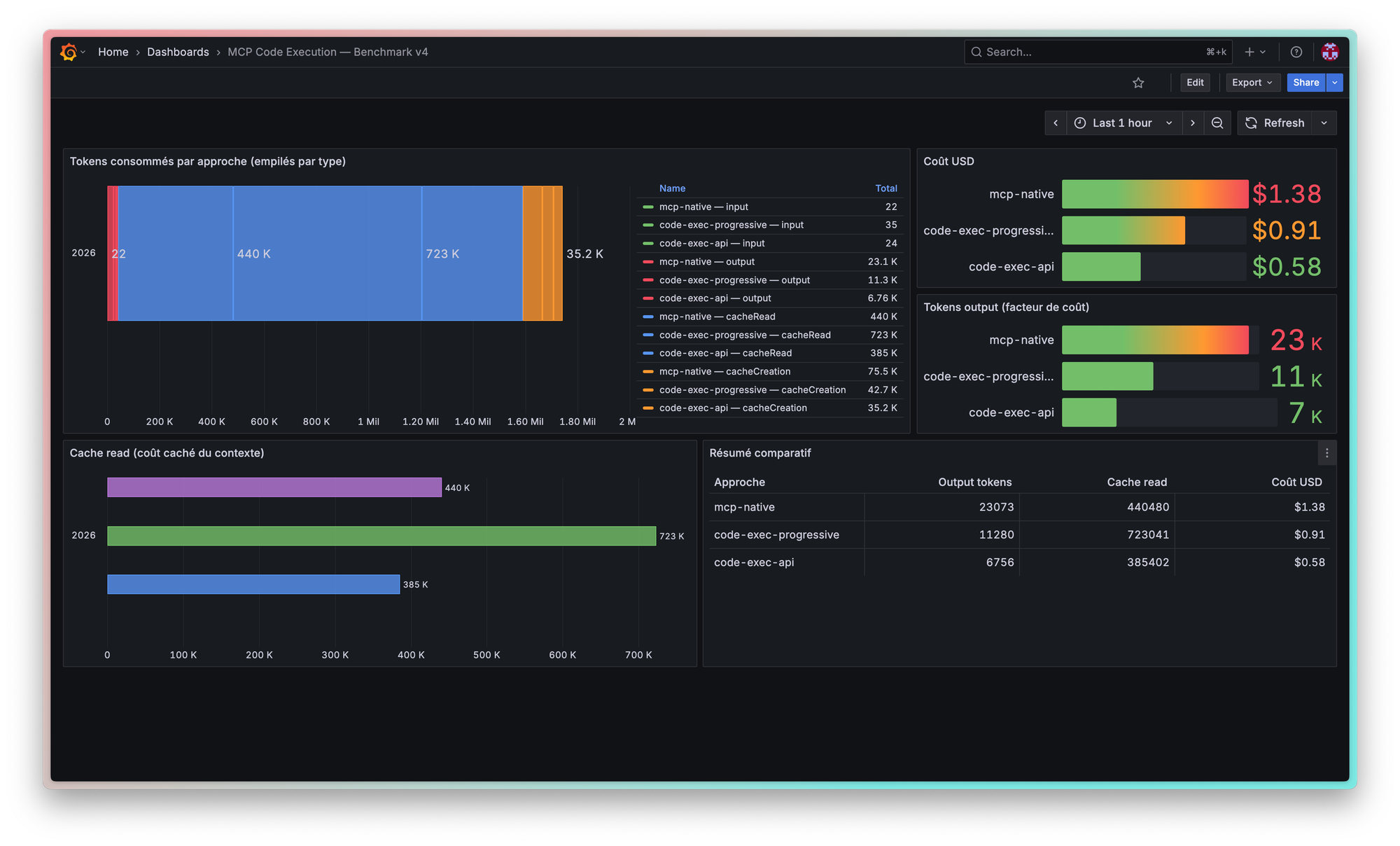
Résultats
| Métrique | Valeur |
|---|---|
| Tools dans le contexte | ~50 |
| Round-trips LLM | 21 |
| Tokens output | 23 073 |
| Tokens cache read | 440 480 |
| Coût | $1.38 |
| Durée | 6 min 9s |
| Dashboard créé | Oui (8 panels) |
21 round-trips pour explorer, construire et valider le dashboard. Chaque aller-retour transporte les ~50 schemas de tools... même ceux qu'il n'utilise jamais. SPOILER : Le coût ($1.38) est le plus élevé des 3 tests ! Les tokens output (23k) explosent : le LLM décrit chaque paramètre de chaque tool call en JSON.
Test 2 — Code Execution + MCP en progressive disclosure
Le concept
Au lieu d'exposer ~50 tools Grafana d'un coup, on donne à Claude 1 seul tool MCP : execute_python. Les définitions MCP Grafana sont générées sous forme de fichiers Python dans le sandbox, que le modèle découvre à la demande.
Autrement dit : côté agent, un seul tool. Côté sandbox, une arborescence de wrappers importables. Le LLM écrit ensuite un script Python qui enchaîne plusieurs appels API par round-trip, au lieu d'un round-trip par appel.
Préparation hors benchmark
Avant de lancer le benchmark, on interroge le serveur MCP Grafana avec tools/list, puis on génère un dossier servers/grafana/ :
servers/
└── grafana/
├── index.py
├── list_datasources.py
├── list_prometheus_metric_names.py
├── query_prometheus.py
├── update_dashboard.py
└── ... ~45 autres fichiers
Arborescence des tools au format .py dans le système de fichier
Chaque fichier correspond à un tool MCP. L'idée est la même que chez Anthropic : le modèle ne charge pas tout, il navigue dans une représentation locale des tools et ne lit que ce qui lui est utile.
# generate_servers.py (simplifié) — génère 1 fichier Python par tool MCP
from mcp_bridge import list_tools
tools = list_tools() # appel MCP tools/list via stdio JSON-RPC
for tool in tools:
name = tool["name"]
func_name = snake_case(name)
params = build_typed_signature(tool["inputSchema"])
# Chaque fichier = docstring + import + 1 fonction qui appelle call_tool()
code = generate_wrapper(name, func_name, params, tool["description"])
Path(f"servers/grafana/{func_name}.py").write_text(code)
script python de génération locale des définitions MCP sous forme de .py
Exemple de fichier généré :
# servers/grafana/list_datasources.py
"""List all configured datasources in Grafana. Use this to discover available datasources and their UIDs. Supports filtering by type and pagination.
Args:
limit: Maximum number of datasources to return (max 100)
offset: Number of datasources to skip for pagination
type: The type of datasources to search for. For example, 'prometheus', 'loki', 'tempo', etc...
"""
from mcp_bridge import call_tool
def list_datasources(limit: int = 50, offset: int = 0, type: str = None):
"""List all configured datasources in Grafana. Use this to discover available datasources and their UIDs. Supports filtering by type and pagination."""
args = {"limit": limit, "offset": offset, "type": type}
args = {k: v for k, v in args.items() if v is not None}
return call_tool("list_datasources", args)
Le tool list_datasources importé dans son fichier au format .py
search_tools optionnel pour aider le modèle à trouver rapidement les bonnes définitions. Dans notre implémentation, on garde la variante la plus simple : le LLM explore servers/grafana/ sur le filesystem. Le principe est le même : progressive disclosure des tools au lieu d'un chargement complet.Setup Claude Code
.mcp.json dans le dossier du test :
{
"mcpServers": {
"code-execution": {
"command": "python3",
"args": ["../execute_python_server.py"],
"env": {
"GRAFANA_URL": "https://grafana.example.com",
"GRAFANA_TOKEN": "<your-token>",
"MCP_SERVER_CMD": "uvx mcp-grafana",
"PYTHONPATH": ".."
}
}
}
}
Configuration MCP pour le pattern Code Execution — le serveur expose un seul tool
Claude Code ne voit plus qu'1 seul tool MCP ici execute_python. La découverte des tools Grafana se fait ensuite depuis le sandbox au fil des besoins, dans le dossier servers/ généré au préalable.
Ce qui se passe
Claude Code ne fait généralement pas tout d'un coup. Typiquement :
- round-trips de découverte, des outils nécessaires
import os
# 1. Explorer les tools disponibles
print(os.listdir("./servers/grafana"))
Script de découverte des tools disponibles avec leur noms
tools = [
"list_datasources",
"list_prometheus_metric_names",
"query_prometheus",
"update_dashboard"
]
for tool in tools:
with open(f"./servers/grafana/{tool}.py") as f:
print(f"=== {tool} ===")
print(f.read())
print()
Script du lecture de la définition de plusieurs tools
- round-trips d'exécution avec le vrai script.
from servers.grafana.list_datasources import list_datasources
from servers.grafana.list_prometheus_metric_names import list_prometheus_metric_names
from servers.grafana.query_prometheus import query_prometheus
from servers.grafana.update_dashboard import update_dashboard
# 1. Explorer la datasource et les métriques disponibles
datasources = list_datasources()
prom = next(ds for ds in datasources if ds["type"] == "prometheus")
metric_names = list_prometheus_metric_names(
datasourceUid=prom["uid"],
regex="claude_code_.*",
limit=20,
)
# 2. Construire le dashboard
dashboard = {
"title": "MCP Benchmark — Test 2",
"panels": [ ... ],
}
# 3. Publier et vérifier
result = update_dashboard(dashboard)
print(f"Dashboard créé : {result}")
Script du maillage des tools en une seule exécution
Le point important n'est pas seulement qu'il n'y a plus qu'un tool MCP côté agent. C'est surtout que les définitions arrivent progressivement dans le contexte : le modèle liste le dossier puis lit 1 ou 2 fichiers ciblés, puis exécute son script. Chaque round-trip fait donc plus de travail, avec moins de contexte inutile.
Résultats
| Métrique | Valeur |
|---|---|
| Tools dans le contexte | 1 |
| Round-trips LLM | 25 |
| Tokens output | 11 280 |
| Tokens cache read | 723 041 |
| Coût | $0.91 |
| Durée | 4 min 4s |
| Dashboard créé | Oui (8 panels) |
25 round-trips... davantage qu'on pourrait s'y attendre ! Le progressive disclosure ajoute des étapes : lister le dossier, lire les fichiers, comprendre les signatures.
Le cache read est le plus élevé des 3 tests (723k). Cela peut s'expliquer car chaque fichier lu par le LLM (fichier des tools notamment) reste dans le contexte pour les tours suivants. Avec ~50 fichiers explorables et 25 round-trips, le contexte accumule du contenu qui n'est plus utile mais qui est quand même renvoyé en cache à chaque appel. C'est le coût caché du progressive disclosure : on échange des schemas contre du contenu qui s'empile au fil des échanges.
Cependant, les tokens output sont divisés par 2 vs le MCP natif (11k vs 23k). En effet, le LLM écrit update_dashboard(dashboard) au lieu de décrire chaque paramètre d'un tool call JSON. Le coût final ($0.91) est 34% moins cher que le MCP natif.
Test 3 — Code Execution + wrappers REST
Le concept
Dans ce test on va explorer une autre approche, on part du concept du pattern code execution et on l'applique sur domaine plus large que MCP : les API. On va en profiter pour appliquer les bonnes pratiques finops de Claude Code dans ce test, en limitant le nombre de wrappers à moins de 10. Ce qui couvre largement les besoins du tests : concevoir des dashboards.
Préparation hors benchmark
Avant de lancer le benchmark, on génère aussi une petite couche Python importable. La différence avec le test 2, c'est que ces fichiers ne passent pas vers tools/call MCP : ils font directement des appels HTTP à l'API Grafana.
grafana_api/
├── list_datasources.py
├── query_prometheus.py
├── update_dashboard.py
├── get_dashboard_by_uid.py
└── search_dashboards.py
Arborescence des .py dans le système de fichier, importable depuis la sandbox
Exemple de wrap python d'un appel api à grafana :
# grafana_api/list_datasources.py
"""List all configured datasources in Grafana.
Returns a list of datasource objects with keys: id, uid, name, type, isDefault.
Use this to discover available datasources and their UIDs.
Example:
from grafana_api.list_datasources import list_datasources
datasources = list_datasources()
prom = next(ds for ds in datasources if ds["type"] == "prometheus")
"""
import os
import requests
GRAFANA_URL = os.environ["GRAFANA_URL"]
HEADERS = {
"Authorization": f"Bearer {os.environ['GRAFANA_TOKEN']}",
"Content-Type": "application/json",
}
def list_datasources():
"""List all datasources. Returns list[dict]."""
resp = requests.get(f"{GRAFANA_URL}/api/datasources", headers=HEADERS)
resp.raise_for_status()
return resp.json()
Script wrappant un appel api grafana pour lister les datasources
Le benchmark mesure ensuite uniquement l'usage de ces wrappers par le LLM, pas leur génération.
Setup Claude Code
Même serveur execute_python, mais cette fois le sandbox contient des wrappers Python orientés API REST :
.mcp.json dans le dossier du test :
{
"mcpServers": {
"code-execution": {
"command": "python3",
"args": ["../execute_python_server.py"],
"env": {
"GRAFANA_URL": "https://grafana.example.com",
"GRAFANA_TOKEN": "<your-token>",
"PYTHONPATH": ".."
}
}
}
}
Configuration MCP pour le pattern Code Execution — le serveur expose un seul tool
Ce qui se passe
Même pattern de découverte que le test 2 : le LLM explore le dossier grafana_api/ via le filesystem, lis les définitions et combine les fonctions en un script.
- round-trips de découverte, des outils nécessaires
import os
# 1. Explorer les tools disponibles
print(os.listdir("./grafana_api"))
Script de découverte des tools disponibles avec leurs noms
tools = [
"list_datasources",
"query_prometheus",
"update_dashboard"
]
for tool in tools:
with open(f"./grafana_api/{tool}.py") as f:
print(f"=== {tool} ===")
print(f.read())
print()
Script du lecture de la définition de plusieurs tools
- round-trips d'exécution avec le vrai script.
from grafana_api.list_datasources import list_datasources
from grafana_api.query_prometheus import query_prometheus
from grafana_api.update_dashboard import update_dashboard
# 1. Trouver la datasource et explorer les métriques
datasources = list_datasources()
prom = next(ds for ds in datasources if ds["type"] == "prometheus")
metrics = query_prometheus(prom["uid"], '{__name__=~"claude_code.*"}')
# 2. Construire et publier le dashboard
# (le LLM construit le dashboard, mais les wrappers gèrent l'HTTP)
dashboard = {
"title": "MCP Benchmark — Test 3",
"panels": [ ... ],
}
result = update_dashboard(dashboard)
print(f"Dashboard créé : {result}")
Script du maillage des tools en une seule exécution
Comme pour le test précédent, il y a progressive disclosure via le filesystem. Ce qui change par contre, c'est la couche d'abstraction sous-jacente et le nombre de fichiers disponibles.
Résultats
| Métrique | Valeur |
|---|---|
| Tools dans le contexte | 1 |
| Round-trips LLM | 16 |
| Tokens output | 6 756 |
| Tokens cache read | 385 402 |
| Coût | $0.58 |
| Durée | 2 min 9s |
| Dashboard créé | Oui (15 panels, le plus complet) |
Le grand gagnant : 16 round-trips, $0.58, 2 minutes. Le LLM a produit le dashboard le plus riche (15 panels, des rows organisées, des timeseries). Les tokens output (6.7k) sont 3.4× moins élevés que le MCP natif. Le cache read (385k) est aussi le plus bas, proche du MCP natif mais avec moitié moins de round-trips.
Les gains en token outputs sont confirmés par le passage de MCP natif à Code Execution. Le cache read est bas mais on a moins de round-trips, le pattern code execution a en effet tendance à augmenter ce cache read par rapport à MCP natif. Le fait d'avoir moins de définitions diminue la pollution de la context window. Cela a surement un impact positif sur le nombre d'échange.
Comparaison
| Test 1 : MCP natif | Test 2 : Code Exec + MCP progressif | Test 3 : Code Exec + REST | |
|---|---|---|---|
| Tools dans le contexte | ~50 | 1 | 1 |
| Round-trips LLM | 21 | 25 | 16 |
| Tokens output | 23 073 | 11 280 | 6 756 |
| Tokens cache read | 440 480 | 723 041 | 385 402 |
| Coût USD | $1.38 | $0.91 | $0.58 |
| Durée | 6 min 9s | 4 min 4s | 2 min 9s |
| Dashboard (panels) | 8 | 8 | 15 |
Nos chiffres vs l'industrie
Anthropic annonce 98.7% de réduction et Cloudflare 99.9% — mais ces chiffres mesurent la réduction du contexte initial (schemas de tools supprimés), pas le coût total d'une tâche. Nos mesures portent sur le coût de bout en bout, ce qui donne des chiffres plus modestes mais plus représentatifs.
Voici par ailleurs quelques benchmarks plus comparables aux nôtres :
| Source | Setup | Réduction mesurée | Type de mesure |
|---|---|---|---|
| AIMultiple (GPT-4.1, 63 tools) | Code exec vs MCP natif | 77% tokens totaux | Bout en bout |
| Speakeasy (Claude Sonnet 4.5, 40-400 tools) | Dynamic toolsets | 91-97% input tokens, mais 2-3× plus de tool calls | Input + tool calls |
| Stacklok (114 tools) | Optimizer sémantique | 60-85% par requête | Par requête |
| Nous (Claude Opus 4.6, ~50 tools) | Code exec + wrappers ciblés | 58% coût, 71% tokens output | Bout en bout |
Nos 34-58% de réduction de coût s'alignent avec les benchmarks qui mesurent le coût total. Le finding de Speakeasy confirme notre observation sur le test 2 : le progressive disclosure réduit les tokens mais augmente les round-trips (2-3× chez eux, 25 vs 21 chez nous).
Ce que les chiffres disent
Le MCP natif (test 1) est le plus cher. $1.38 pour 21 round-trips. Chaque action est un aller-retour, et chaque aller-retour transporte les ~50 schemas. Les tokens output explosent (23k) : le LLM doit formater chaque tool call en JSON structuré.
Le progressive disclosure MCP (test 2) réduit le coût mais pas les round-trips. $0.91, 25 turns — paradoxalement plus de round-trips que le MCP natif. L'exploration du filesystem ajoute des étapes. Le cache read est le plus élevé (723k) parce que chaque fichier lu reste dans le contexte pour les tours suivants. Mais les tokens output sont divisés par 2 : update_dashboard(dashboard) vs un tool call JSON complet.
Les wrappers REST (test 3) écrasent tout. $0.58, 16 turns, 2 minutes. Le dossier grafana_api/ ne contient qu'un dizaine de wrappers ciblés (vs ~50 fichiers dans servers/grafana/). Moins de bruit à explorer, moins de contexte à accumuler. Le dashboard est d'ailleurs le meilleur : 15 panels, avec des timeseries et des rows organisées.
Ce qu'on en retient
Code Execution fonctionne... mais pas forcément pour la raison qu'on croit
Le batching (plusieurs appels API par round-trip) et la réduction des tokens output (du code Python au lieu de JSON tool call) divisent le coût par 2 minimum vs le MCP natif. Ça, c'est confirmé par les 3 tests.
Mais le progressive disclosure — le cœur du pattern Anthropic — déçoit sur notre cas. Le test 2 met ~50 fichiers dans le filesystem et le LLM passe 25 turns à explorer, lire, revenir en arrière. Chaque fichier lu reste dans le contexte et gonfle le cache read. On remplace 50 schemas MCP par des fichiers à explorer — c'est mieux mais ce n'est pas suffisant pour optimiser les round-trips.
Le vrai impact observé ici : la curation
Le test 3 gagne ($0.58, 16 turns) parce qu'on a écrit des wrappers ciblés au lieu de générer 50 fichiers. Le LLM fait ls grafana_api/, lit 2-3 fichiers, et code. Pas de bruit, pas de tri dans des dizaines de fonctions inutiles.
Ce n'est pas le REST qui bat le MCP. C'est le ratio signal/bruit. Si on avait mis des wrappers MCP ciblés dans servers/grafana/ au lieu de 50, le test 2 aurait probablement eu des résultats similaires.
Le facteur dominant n'est pas le transport (MCP, REST, SDK) — c'est le nombre de choses qu'on expose au LLM. Que ce soit en schemas, en fichiers, ou en wrappers : plus il doit trier, plus ça coûte.
La limite du chaînage MCP : pourquoi le LLM essaye davantage
Le pattern Code Execution repose sur une promesse : le LLM écrit un script qui chaîne plusieurs appels. Sauf que MCP ne définit pas de schema d'output. Un tools/call retourne du TextContent — une string opaque, pas un objet typé.
Quand le LLM écrit datasources = list_datasources() puis uid = datasources[0]["uid"], il suppose que le retour est un dict Python exploitable. Mais rien dans le protocole MCP ne le garantit.
outputSchema optionnel, c'est un sujet en évolution !Par ailleurs, utiliser un SDK natif (comme grafana_client) qui définit des types de retour explicites : list[Datasource], QueryResult peut être une bonne alternative. Dans ce cas le LLM peut chaîner les appels en confiance, et le code généré est plus compact — pas besoin de gérer l'incertitude du format. C'est aussi une des raisons pour lesquelles les wrappers REST du test 3 produisent moins de tokens output, le LLM avait des infos sur le format de l'API Grafana...
En pratique
| Situation | Approche recommandée |
|---|---|
| Peu de tools (< 15) | MCP natif. Le surcoût en schemas est négligeable et vous gardez l'observabilité de chaque action. |
| Beaucoup de tools, API connue | Code Execution + 5-10 wrappers ciblés. Pas besoin de générer un fichier par tool — écrivez les fonctions utiles pour votre tâche. Plus rapide à développer, plus efficace à l'exécution. |
| Beaucoup de tools, API exotique | Progressive disclosure + mécanisme de recherche (search_tools, index filtré). Sans ça, le LLM se noie dans le filesystem — nos résultats le montrent. |
Au-delà de MCP
L'idée de cet article dépasse le cas Grafana et des MCP. Ce pattern de code execution peut s'appliquer à tout un outillage interne : scripts Python maison, wrappers utilitaires, helpers métier. Plutôt que d'exposer tout ça d'un bloc au modèle, on lui donne un outil d'exécution de code et des modules à découvrir. Le contexte reste propre, l'interface est stable, et on n'a pas besoin de transformer chaque script en tool MCP déclaré.
La vraie question n'est pas "faut-il un serveur MCP ?" mais "combien de choses mon agent doit-il voir pour faire son travail ?" Moins, c'est mieux — et Code Execution est un bon outil pour réduire cette surface. À condition de ne pas juste remplacer un catalogue de tools par un catalogue de fichiers...





{kind=link}