
J'ai passé et obtenu la certification Architecte d'Anthropic (CCA-F), 813/1000, premier Sfeirien à la tenter. Le plus utile, ce n'est pas le badge : ce sont les règles de diagnostic qu'on en retire et qu'on réutilise ensuite sur de vrais projets. Mon REX : la préparation, les difficultés, le temps que ça a pris.
Pourquoi passer la certification Anthropic CCA-F ?
La certification CCA-F (Claude Certified Architect Foundations) d'Anthropic ne teste pas si vous connaissez la syntaxe d'une API, mais si vous savez diagnostiquer : quand corriger au niveau du prompt, quand ça relève de l'architecture des agents. Je l'ai passée et obtenue (813/1000, seuil à 720), pendant une semaine de congé. Le plus instructif n'a pas été l'examen, mais l'écart entre mes très bons scores en examen blanc et la réalité. C'est ce REX que je veux partager : mon vécu, mes difficultés, et le temps que ça a pris.
Pourquoi je m'y suis mis ? Côté francophone, on ne trouve quasiment aucun retour d'expérience sur cette certif. sfeir.dev publie de bons REX sur d'autres certifs, comme passer ses certifs cloud en tant que non-tech ou le REX Remote Foundation de GitLab. Mais la certification d'Anthropic est récente, personne n'a encore publié de REX dessus.
Comme je passe beaucoup de temps à outiller Claude Code, au travail comme sur mes projets perso (créer des skills, automatiser des tâches), je voulais savoir ce que valait vraiment le papier, et vérifier que je ne racontais pas n'importe quoi sur le sujet. Détail qui n'a pas aidé à me détendre : j'étais le premier Sfeirien à la tenter, aucun collègue pour me dire à quoi m'attendre.
Avant l'examen : ce que teste vraiment la certif CCA-F
Le format :
- 60 questions, QCM 4 options, 120 minutes.
- Seuil de réussite : 720/1000.
- Des scénarios applicatifs variés, du type agent de support, génération de code, système multi-agents ou CI/CD.
- Tous les domaines ne pèsent pas pareil dans la note.
Les grands domaines : l'architecture et l'orchestration agentique (le plus gros morceau), le design d'outils et l'intégration MCP, la configuration de Claude Code et les workflows, le prompt engineering et la sortie structurée, la gestion du contexte et des tokens et la fiabilité.
Ce qui m'a surpris dès la révision : presque aucune question ne demande de réciter quelque chose. On vous présente une situation ("voilà un agent qui se comporte mal, voilà la contrainte du client") et on vous demande le bon geste. La moitié des options proposées sont techniquement valides. Le piège, c'est de choisir la "bonne pratique" générale au lieu de celle que la situation impose.
Concrètement, une question type ressemble à ça : un système qui dysfonctionne, une poignée de contraintes (budget, latence, conformité, taille d'équipe), et quatre corrections toutes plausibles. La bonne réponse n'est presque jamais la plus sophistiquée. C'est celle qui respecte la contrainte que l'énoncé a glissée presque incidemment. C'est le réflexe qui sert au quotidien sur de vrais projets, et souvent celui qui manque sous pression.
La préparation à la certification Claude : ~5 jours, en congé, pas en continu
Soyons honnête sur le temps, puisque c'est la première chose qu'on me demande : environ cinq jours, étalés sur une semaine de congé, sans m'acharner en continu. Des sessions le matin, des pauses, j'y revenais. C'est faisable sur une semaine libre sans s'épuiser, mais pas en survol entre deux réunions.
Ce qui a composé ma préparation :
- Le cours officiel sur la plateforme Skilljar d'Anthropic. Base solide, à faire en premier.
- Un dossier de notes perso où je reprenais le cours, la doc Claude Code et l'API avec mes mots. Réécrire, c'est là que ça rentre.
- Une app d'examens blancs que je me suis montée avec Claude Code, à partir d'un pool de questions de practice, pour m'entraîner en conditions.
Ce qui m'a fait gagner du temps : les examens blancs, pour identifier mes angles morts. Ce qui m'en a fait perdre : vouloir tout mémoriser au lieu de comprendre les règles de décision. La certification récompense le diagnostic, pas la récitation.
Le détail qui a fait bouger ma préparation : suivre mon score par catégorie dans mon app de practice, pas seulement le score global. Une faiblesse est sortie du lot tout de suite : une catégorie où je plafonnais autour de 67 %. Au lieu de refaire des examens blancs complets en boucle (flatteur pour l'ego, peu efficace), j'ai travaillé cette seule zone jusqu'à comprendre pourquoi je me trompais. Sur trois passages du practice pool, elle est passée de 67 % à 80 % puis à 100 %.
La leçon de méthode dépasse l'examen : un score global qui monte cache souvent une faiblesse précise. C'est cette faiblesse qu'il faut cibler, pas la moyenne qui rassure.
Mes difficultés : le diagnostic prompt vs architecture des agents
C'est ce qu'on lit rarement ailleurs. En révisant, j'ai identifié quelques patterns d'erreur qui revenaient sans cesse. Je les formule comme des leçons générales : elles viennent de mes révisions, pas de l'examen réel.
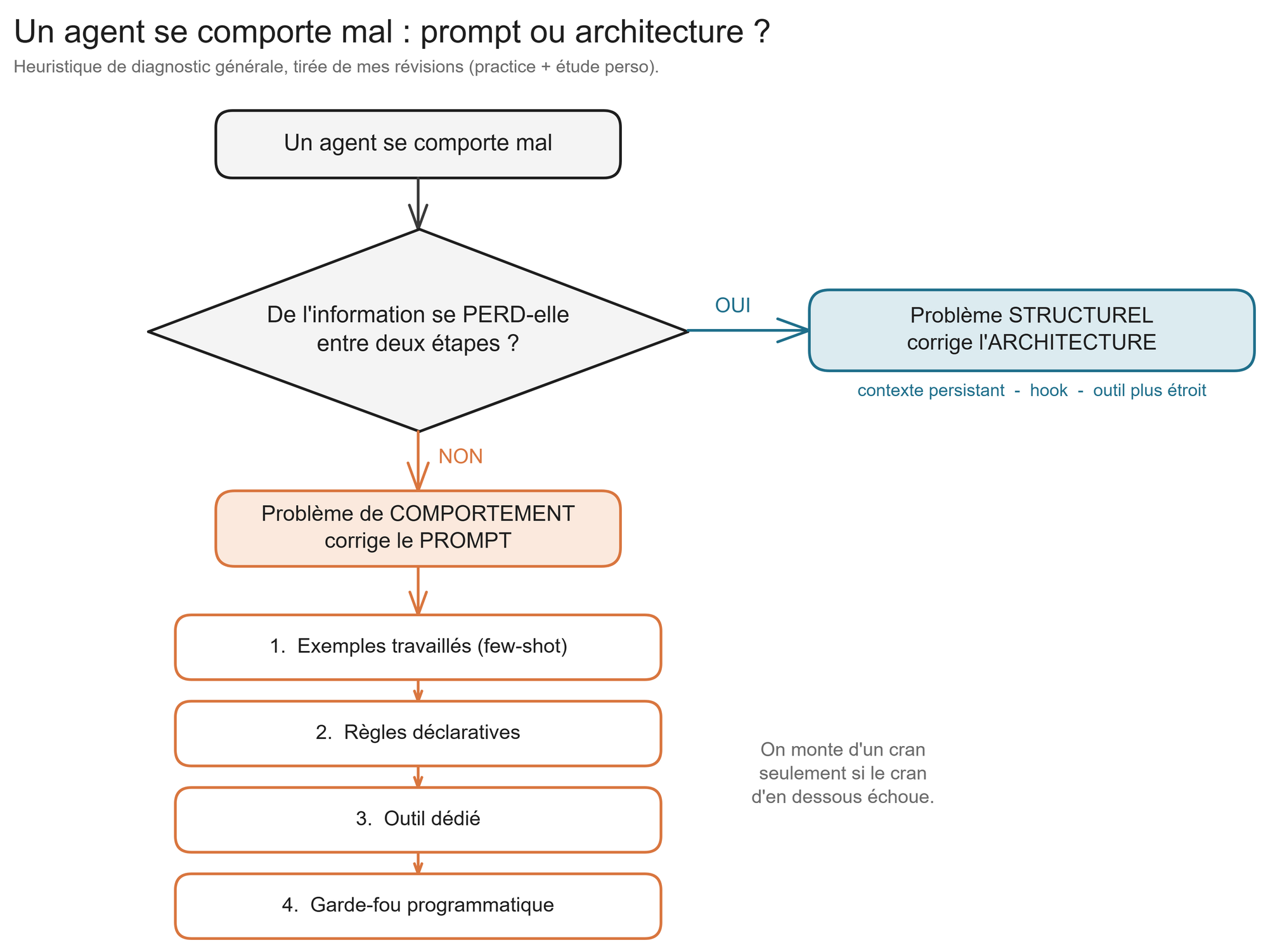
1. Vouloir ré-architecturer avant d'avoir tenté un fix au prompt. Mon réflexe était de sur-architecturer (découper en sous-agents, ajouter un orchestrateur) là où ajouter quelques exemples concrets dans le prompt suffisait. La hiérarchie que j'ai fini par intérioriser : d'abord des exemples travaillés, puis des règles déclaratives, puis un outil dédié, et seulement en dernier un garde-fou programmatique. On monte d'un cran seulement quand le cran d'en dessous échoue.
2. Confondre "façonner un comportement" et "corriger une structure". Si un agent classe mal ou divague, c'est souvent un problème de prompt (few-shot). Mais si de l'information se perd entre deux étapes, aucun prompt n'y changera rien : c'est structurel (bloc de contexte persistant, hook, outil plus étroit). Un comportement se corrige au prompt, une perte d'information à l'architecture.
3. Ne pas lire la contrainte dure avant de scanner les options. Plusieurs fois je me suis fait avoir parce que l'énoncé contenait déjà la cause racine ou une contrainte explicite (une limite de ressources, une interdiction métier, un format imposé) qui éliminait des options pourtant correctes en théorie. Évident, mais vital : lire tout l'énoncé avant de regarder les réponses.
4. Few-shot vs critère. Pour un pattern à reconnaître, des exemples marchent. Pour une règle universelle, il faut définir un critère précis, pas empiler des exemples qui invitent au pattern-matching approximatif.
5. Confondre relecture par soi-même et relecture indépendante. Quand un agent doit vérifier son propre travail, mon réflexe était de lui ajouter une étape d'auto-critique dans le même fil. Sauf que le biais de confirmation persiste : un agent qui a déjà tranché va rationaliser sa décision, pas la casser. Pour mettre à l'épreuve une conclusion assumée, il faut une instance indépendante, contexte vierge. L'auto-critique sert à combler un oubli, pas à remettre en cause un choix déjà pris.
Le jour J : 120 minutes de diagnostic
Un détail qui change tout côté pression : en cas d'échec, il faut attendre six mois avant de retenter. Pas de "je le repasse la semaine prochaine". Ça transforme chaque question douteuse en petit enjeu, surtout quand on est le premier Sfeirien à la tenter sans repère.
120 minutes, ça paraît large. Ça ne l'est pas quand chaque question est un petit cas à instruire. J'ai senti la pression monter sur les scénarios où deux options se tenaient de très près. Le doute classique : est-ce que je surinterprète l'énoncé ?
Ma gestion : ne pas m'enliser. Marquer, avancer, revenir. Et surtout faire confiance à la lecture lente de l'énoncé plutôt qu'à l'intuition de la première option "qui a l'air sérieuse". Les questions où je me suis planté en blanc, c'était presque toujours par lecture trop rapide.
Le piège des examens blancs de la CCA-F
C'est là que mon REX bascule. Mes trois derniers examens blancs ont donné : 770, puis 934, puis 1000/1000. Score parfait. Je me sentais serein.
L'examen réel : 813. Soit −187 points par rapport à mon dernier blanc.
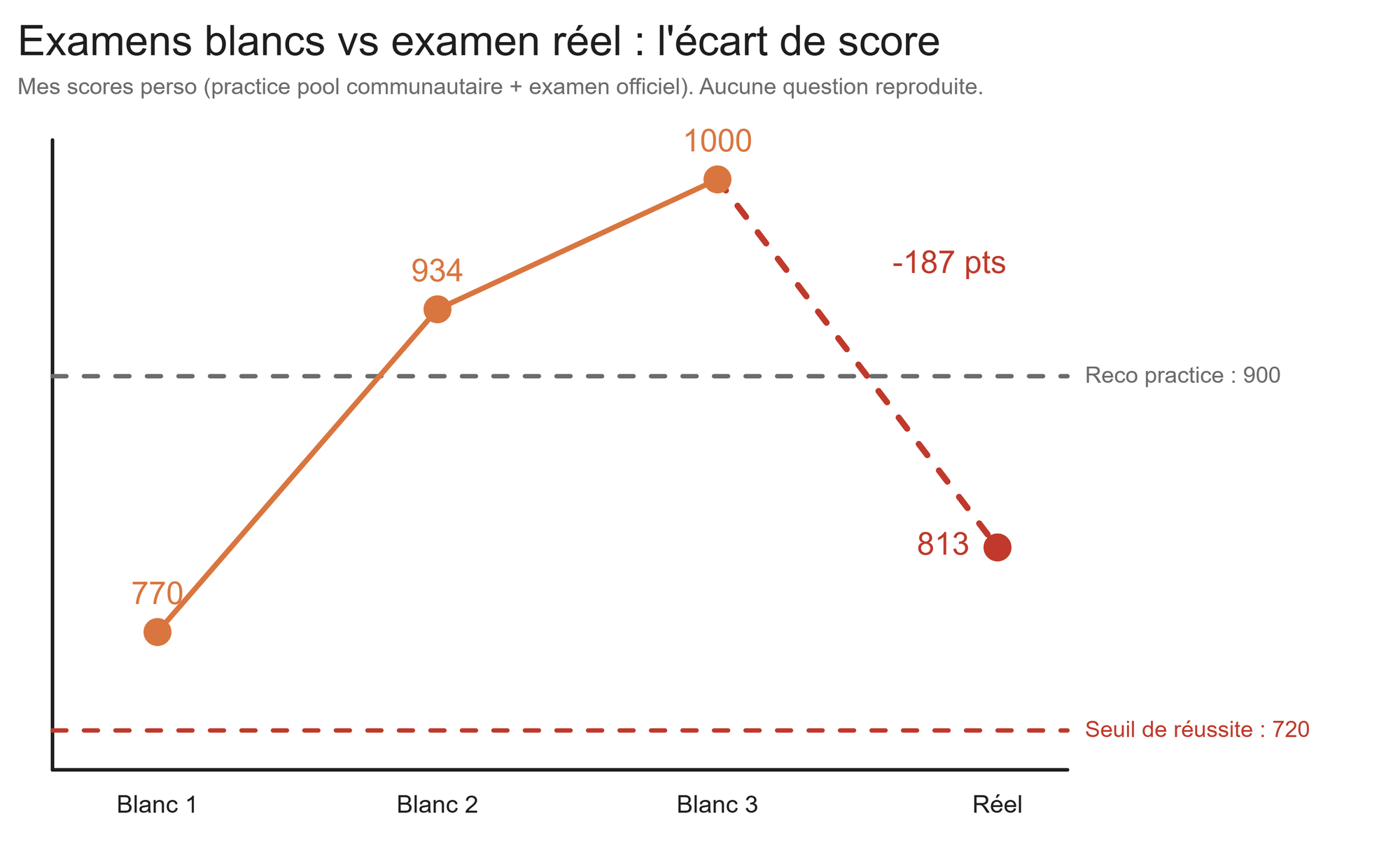
Pourquoi un tel écart ? Deux raisons que j'ai comprises après coup :
- Le pool de questions de practice finit par vous connaître : à force de tourner dessus, on mémorise des réponses sans toujours rejouer le raisonnement.
- Aucun examen blanc ne vaut la vraie pression du jour J. Les questions où je doutais en blanc, j'avais oublié de les repenser à froid. Pas un problème de matériel, un problème de préparation.
1000/1000 en practice m'a donné une fausse confiance : un bon score en examen blanc ne dit pas qu'on est prêt. Si je devais refaire, je m'entraînerais sur des pools plus variés et je me forcerais à re-justifier chaque réponse à voix haute, même celles que je "connais".
Ce que la certif Claude m'a appris (et qui sert encore au travail)
Une certif vaut le coup quand ce qu'on en retient sert après. Les règles de décision que la préparation m'a forcé à clarifier, je les utilise désormais au quotidien sur de vrais systèmes :
- Comportement au prompt, perte d'information à l'architecture. Avant de complexifier une chaîne d'agents, je vérifie si le problème est juste un comportement à cadrer.
- Activation : toujours-actif vs à la demande. Une convention générale va dans une règle toujours chargée ; un savoir-faire ponctuel va dans un skill déclenché à la tâche. Ne pas confondre activation par périmètre et activation par tâche.
- Async vs synchrone. Du traitement planifié, nocturne, sans humain qui attend et en un seul passage, c'est du batch. Dès qu'il y a un humain bloquant ou des appels d'outils itératifs, c'est du synchrone. Distinguer la gêne pratique (latence) de l'impossibilité architecturale.
- Escalader sur un trou de politique, pas sur l'inconfort. On remonte à un humain quand les règles existantes ne couvrent pas le cas, pas quand la décision est juste émotionnellement désagréable.
- Relecture critique : instance fraîche, pas auto-critique. Pour remettre en cause une décision déjà prise, je lance un second passage en contexte vierge plutôt qu'une auto-revue qui finit par se donner raison.
Aucune de ces idées n'est originale. Mais les avoir formulées proprement, sous pression d'examen, les a vraiment ancrées.
Et maintenant ? Mon verdict sur la certification CCA-F
Pour qui c'est utile ? Si vous concevez des agents, si vous êtes référent IA dans votre boîte, ou si vous poussez Claude Code dans vos équipes : oui, ça vaut le détour. Pas pour le badge, mais pour la méthode de décision qu'elle oblige à clarifier.
Pour qui ça l'est moins : si vous cherchez une validation de syntaxe ou un tuto pas-à-pas, ce n'est pas l'examen qu'il vous faut.
Un mot sur le coût réel : au-delà du temps, il y a la pression du délai de six mois en cas d'échec, qui pousse mécaniquement à sur-préparer. Avec le recul, cinq jours bien ciblés suffisent si on travaille les bons réflexes plutôt que d'empiler les heures. Le piège n'est pas le manque de travail, c'est le mauvais type de travail : réviser large et se rassurer, au lieu de cibler ses zones rouges et de re-justifier chaque réponse.
Ce que je ferais différemment : moins me fier aux examens blancs, varier les sources, et accepter que "ça passe à 813" est un résultat honnête, pas un échec déguisé. Prochaine étape pour moi : voir comment transformer ça en brique de formation interne, parce qu'une certif ne vaut que si ce qu'on en retire sert ensuite.






{kind=link}