
La KubeCon d'Amsterdam, c'est officiellement trois jours de conférences, d'ateliers et de rencontres autour de l'écosystème cloud native. Mais pour qui sait où regarder, l'événement commence bien avant l'ouverture des portes officielles. De plus en plus d'entreprises profitent en effet de ce rendez-vous incontournable pour organiser leurs propres "side events" dans les jours précédents, à proximité du lieu principal. C'est notamment le cas des Container Days de Google, un événement satellite qu'il faut avoir sur son radar. Et une fois la journée terminée, la communauté continue de se retrouver lors de meetups en soirée, occasions idéales pour des échanges informels autour d'un repas et d'un verre — avec modération, bien sûr — avant d'attaquer une nouvelle journée bien chargée !
J0: Google Container Day

Le Google Container Day donne le ton dès la première intervention : Kubernetes s'impose comme la plateforme de référence pour faire tourner des workloads d'IA. Un fil rouge qui traversera toute la semaine de la KubeCon.
Au programme, 6 talks denses, avec une première salve de nouveautés orientées IA. Du côté du scheduling, le DRA (Dynamic Resource Allocation) apporte une gestion fine et optimisée des ressources matérielles spécialisées comme les GPUs. Les Compute Classes permettent quant à elles de définir des pools de nodes spécifiquement taillés pour les workloads IA. Enfin, grâce à gVisor et sa capacité de snapshot, le démarrage des pods est considérablement accéléré : le pod redémarre avec l'intégralité de son contexte déjà chargé en mémoire, évitant ainsi une initialisation à froid.
Mais les annonces ne se limitent pas à l'IA. Google promet une accélération globale de Kubernetes : scheduling des pods plus réactif, création des nodes plus rapide lors du scaling du cluster, et démarrage des applications boosté grâce au CPU Boost — qui alloue davantage de CPU au lancement, particulièrement bénéfique pour les applications Java gourmandes à l'initialisation. La démo parlait d'elle-même : un pod passant de 42 à 12 secondes avant d'être prêt.
Enfin, Google réaffirme son engagement envers Kubernetes open source, au-delà de GKE, avec plusieurs fonctionnalités clés :
- Kueue / MultiKueue : gestion de files d'attente de jobs à l'échelle, avec un cluster maître orchestrant plusieurs clusters workers
- JobSet : orchestration de groupes de jobs coordonnés, idéal pour les entraînements distribués
- DRA (Dynamic Resource Allocation) : mécanisme permettant aux pods de demander et consommer des ressources matérielles spécialisées de manière dynamique et flexible
- Leader Working Set : optimisation mémoire permettant de partager les pages mémoire communes entre plusieurs pods similaires, réduisant ainsi l'empreinte globale
🐝 Isovalent eBee Quest at KubeCon Amsterdam
En soirée, direction les hauteurs d'Amsterdam pour ce second side event, organisé cette fois par Isovalent autour de son produit phare, Cilium. Le cadre est saisissant : dernier étage d'un hôtel avec une vue panoramique sur la ville. Difficile de rester concentré... mais le contenu est là pour nous y aider ! 😄
L'année précédente j'avais participé à un lab autour de Falco, et cette année, c'est Isovalent qui propose un challenge autour de Cilium, le plugin réseau (CNI) de Kubernetes. Le principe : une série de 30 labs à enchaîner, et il faut en compléter le plus possible !

Au-delà de l'aspect ludique et compétitif, le format est redoutablement efficace pour apprendre. En manipulant vraiment le produit sur des environnements éphémères, on comprend vite que Cilium va bien au-delà de la simple configuration réseau — assignation d'IPs et gestion du routage. On découvre notamment :
- Hubble : une couche d'observabilité puissante pour visualiser et analyser les flux réseau
- Une UI intuitive pour explorer et comprendre ce qui se passe dans le cluster
- Chiffrement et sécurisation des communications entre les pods
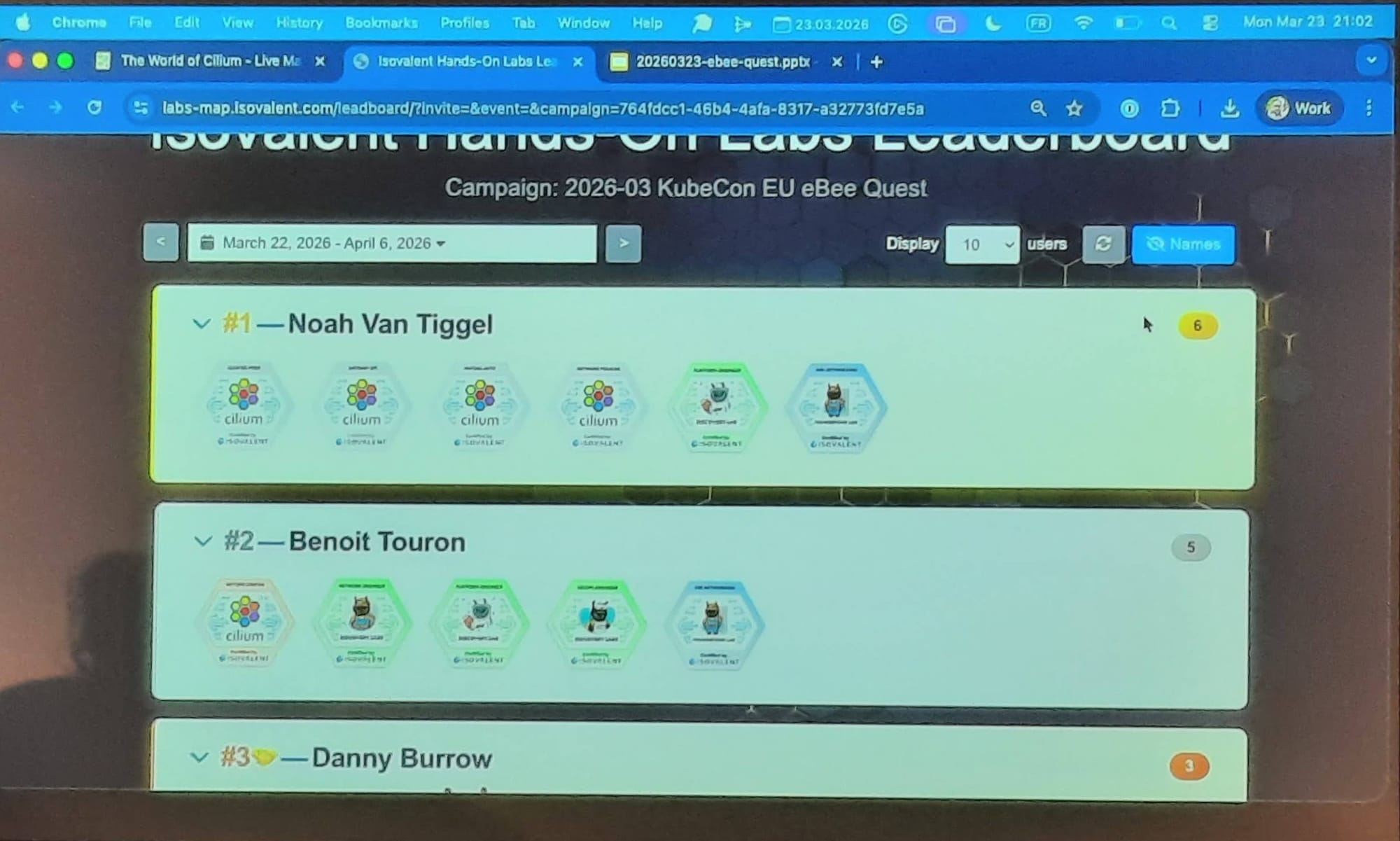
Très instructif, et clairement de quoi donner envie de creuser le sujet plus en profondeur. Ah, et petit détail qui ne gâche rien : je termine 2ème du challenge ! 🏆
Jour 1 : ouverture en grande pompe au RAI d'Amsterdam
Le coup d'envoi de la KubeCon officielle est donné au RAI d'Amsterdam, et le moins que l'on puisse dire, c'est que le spectacle est au rendez-vous. 13 000 participants ont fait le déplacement, faisant de cette édition l'une des plus grandes KubeCon jamais organisées. L'écosystème CNCF continue quant à lui de s'élargir avec désormais 230 projets sous son égide.
Parmi les annonces marquantes, NVIDIA rejoint la CNCF en tant que nouveau partenaire — un signal fort qui en dit long sur la trajectoire de Kubernetes vers l'IA.
Kubernetes, plateforme de référence pour l'IA
Comme pressenti dès le Google Container Day, le message est clair : Kubernetes devient le standard de facto pour opérer des workloads d'IA à l'échelle. Plusieurs projets illustrent cette tendance :
- vLLM : moteur d'inférence haute performance optimisé pour faire tourner des grands modèles de langage sur un seul nœud
- LLMD : solution de distribution des modèles LLM à travers plusieurs nœuds pour passer à l'échelle
- Inference Gateway : une passerelle intelligente qui analyse les prompts entrants et les route vers le nœud le plus adapté, notamment celui qui dispose déjà du contexte chargé en mémoire
Une citation résume parfaitement l'esprit de cette évolution :
"Kubernetes n'a pas été conçu pour l'IA, il a été conçu pour l'orchestration et la distribution."
...mais tout cela s'applique précisément à l'IA. C'est la nature ouverte et extensible de Kubernetes qui en fait aujourd'hui le choix naturel pour opérer de l'IA à grande échelle.
Les temps forts de la keynote
- Nvidia a présenté AICR, son outil dédié au déploiement de workloads IA dans Kubernetes
- Le dashboard Headlamp s'enrichit d'une intégration IA via un serveur MCP couplé à HolmesGPT, apportant une assistance intelligente directement dans l'interface
- Lin Sun de Solo.io monte sur scène avec son énergie communicative et fait voler un drone en live — la salle est conquise 🚁
- Clou du spectacle : un planeur sur scène ! Développé en partenariat avec le CERN, ce planeur électrique a été transformé en véritable laboratoire scientifique volant, équipé de capteurs mesurant les conditions atmosphériques, les niveaux de radiation et même la concentration en microplastiques. Les données sont streamées en temps réel via un pipeline de télémétrie et de visualisation basé sur... Kubernetes dans les nuages, à 8000 mètres d'altitude ! 🛩️
Une ouverture pleine d'énergie et de spectacle, qui donne le ton pour le reste de la semaine. La barre est haute ! 🚀
Les Breakout Sessions : l'embarras du choix
Une fois la keynote terminée, place aux breakout sessions. Et c'est là que commence un autre défi : choisir parmi des centaines de conférences et autant de speakers de talent. Impossible d'être partout à la fois ! Voici quelques-unes de celles qui m'ont particulièrement marqué.
Rust Vs. Go: Building a Container Network Stack From Scratch
Depuis plus d'une décennie, Go s'est imposé comme le langage de référence du cloud native. Mais est-il toujours le bon choix ? C'est la question que s'est posée l'équipe Podman au moment de réécrire leur stack réseau avec Netavark et Aardvark. Malgré des années d'expérience en Go, ils ont fait le choix audacieux de Rust.
Matt Heon, mainteneur core de Podman, revient sur les raisons concrètes de ce choix, les avantages observés et les compromis acceptés. Le talk est complétée par le témoignage de Shivang K. Raghuvanshi, mentee LFX, qui partage son expérience de contribution au projet et la résolution d'un bug critique dans la stack réseau — une belle illustration de ce que le mentorat en open source peut accomplir.
Rust vs Go, le bilan : le succès d'une telle migration dépend avant tout des équipes. Rust est indéniablement plus complexe que Go, mais offre en contrepartie une gestion des erreurs nettement supérieure et des garanties de sécurité mémoire appréciables dans un contexte réseau.
Au final, le choix semble judicieux et assumé : les développeurs sont satisfaits et s'accommodent bien de cette complexité relative. La revue de code est certes un peu plus exigeante, mais le gain en robustesse en vaut la chandelle. 🦀
The Developer’s Nightmare: How To Survive Compliance Checklists (and Still Ship Fast)

Vous avez terminé votre nouvelle feature et vous n'attendez qu'une chose : la shipper en prod. Mais c'est sans compter sur les Gardiens de la Compliance qui surgissent avec leur lot de questions :
- Les licences de vos dépendances sont-elles toutes approuvées ? (→ SBOM intégré au cycle de release)
- Y a-t-il des CVE connues sur vos nouvelles dépendances ?
- Pouvez-vous garantir que l'artefact en production n'a pas été altéré ? (→ signature des commits et des images avec Cosign)
S'ensuivent checklists, paperasse et réunions... avant d'obtenir enfin le précieux sésame. Pas vraiment fun. Où est passée la joie du développeur ?
Alexandra et Thomas explorent comment briser ces barrières de conformité, même dans les secteurs les plus régulés, en s'appuyant sur des outils open source comme Backstage, Dependency-Track, Sigstore et Buildpacks — avec l'objectif de laisser la plateforme automatiser et assurer les contrôles, sans freiner les développeurs.
Ce que j'ai particulièrement apprécié, c'est l'énergie et le storytelling des deux speakers : Alexandra incarne une développeuse enthousiaste, pressée de montrer sa toute nouvelle feature au monde entier, tandis que Thomas joue les gardiens vigilants, là pour veiller au grain et assurer la conformité. Un duo savoureux qui rend le sujet aussi vivant qu'instructif ! 🎭
Jour 2: Keynote sous le signe de la souveraineté

Nouvel angle pour cette seconde keynote : la souveraineté. Dans le contexte géopolitique actuel, le sujet prend une résonance toute particulière. Le message est fort : le code est un bien commun, il n'appartient pas à une entreprise mais à la communauté. L'open source prend ici tout son sens et toute son importance.
Le Cyber Resilience Act (CRA) : l'open source face à la réglementation européenne
Le CRA (Cyber Resilience Act) est une réglementation européenne qui impose des exigences de cybersécurité aux fabricants et éditeurs de logiciels commercialisés dans l'UE — y compris ceux intégrant des composants open source. Un défi majeur pour la communauté, qui doit désormais composer avec des obligations de transparence, de gestion des vulnérabilités et de documentation de sécurité.

L'OpenSSF (Open Source Security Foundation) joue ici un rôle clé en accompagnant la communauté open source pour répondre à ces nouvelles exigences et peser dans les discussions avec les instances européennes via le CRA Expert Group.
Timeline : le CRA entre en vigueur progressivement, avec une échéance critique pour les fabricants prévue dans quelques mois seulement. Le compte à rebours est lancé.
La SNCF : un cloud souverain 100% open source
Belle illustration concrète de souveraineté avec le témoignage de la SNCF, qui s'appuie sur des technologies open source — notamment OpenStack — pour construire et opérer un cloud interne totalement souverain. Une démarche qui permet à l'entreprise de garder la maîtrise de ses infrastructures et de ses données, sans dépendance à un hyperscaler étranger. Un exemple concret à l'heure où la question de la souveraineté numérique est plus que jamais au cœur des débats.
On revient à l'IA, mais toujours vue sous l'angle de la souveraineté.
L'IA souveraine selon RedHat
L'IA passe rapidement du stade de l'expérimentation à celui des workloads critiques en production. Mais déployer des pipelines d'inférence à grande échelle soulève des défis inédits : performance, résilience, conformité et souveraineté des données.
Mais souveraineté ne signifie pas isolation, et RedHat introduit le concept de Sovereign AI : une approche Kubernetes-native pour orchestrer des workloads d'inférence en gardant le contrôle.
L'objectif est clair : permettre aux entreprises de faire tourner des services d'IA performants, résilients, conformes aux réglementations — et surtout souverains. Sans sacrifier l'efficacité opérationnelle au profit du contrôle, ni l'inverse.

Un message qui résonne particulièrement dans le contexte européen actuel, et qui confirme que la souveraineté n'est pas qu'un sujet politique : c'est aussi une architecture à part entière. 🔐
Hello World, Meet the Spanimals: Observability for Beginners

Une session rafraîchissante et particulièrement bien amenée. Les speakers commencent par poser les fondamentaux de l'observabilité de façon didactique et accessible, avec une analogie autour d'animaux qui rend le tout mémorable 🐾 : traces, profiling, logs, métriques, collecte.
Place ensuite à une explication plus technique avec le panorama des principaux outils open source avec leur équivalent dans la stack Grafana:
- Tracing: Jaeger / Grafana Tempo
- Profiling: Parca / Grafana Pyroscope
- Collecte: Open Telemetry / Grafana Alloy
- Logs: Stack ELK / EFK / Grafana Loki
- Métriques: Prometheus / Grafana Mimir
La session se conclut par une démo de bout en bout de la stack Grafana, qui illustre concrètement comment tous ces composants s'articulent ensemble. Une excellente introduction pour qui souhaite se lancer dans l'observabilité sans se noyer dès le départ. 📊
Jour 3 : Keynote — Kubernetes grandit, l'IA prend les commandes
Cette troisième keynote dessine une vision d'ensemble cohérente : Kubernetes est en pleine évolution. Né comme un simple orchestrateur de conteneurs, il s'impose aujourd'hui comme le système d'exploitation distribué de référence pour une infrastructure de plus en plus complexe, hétérogène et autonome.
Le fil conducteur est clair : comment faire évoluer les architectures cloud native — applications, plateformes, réseaux — pour répondre aux exigences de l'ère de l'IA ? Plusieurs angles sont explorés :
- La gouvernance et la maturité des projets CNCF, guidées par les retours des utilisateurs finaux (Red Hat, Apple, Boeing, New York Times)
- L'architecture des plateformes, qui échoue souvent silencieusement faute de séparation claire des responsabilités — un appel à appliquer à nos plateformes la même rigueur architecturale que celle qui a fait le succès des applications cloud native
- Le passage du Cloud Native à l'Accelerator Native : Kubernetes devient le médiateur universel entre des hardwares spécialisés (GPU, TPU) et des frameworks IA en constante évolution
- L'émergence des agents IA comme utilisateurs à part entière des systèmes de production, redessinant la frontière entre l'humain et la machine
- Enfin, les réseaux autonomes de Nokia, qui s'appuient sur le cloud native pour rapprocher télécoms et infrastructure moderne
En filigrane, une question se pose : à mesure que l'IA prend les commandes de nos infrastructures, où s'arrête l'OS et où commence l'application ? 🤖
Pour ce dernier jour de conférence, deux m'ont particulièrement plu.
Cloud Native at the Far(m) Edge: Running Kubernetes and AI on Tractors

Lors de la première Keynote, nous avons vu Kubernetes dans les nuages. Ici, Aurea Imaging et Spectro Cloud nous emmènent... dans les champs agricoles.
Le principe : faire tourner de l'inférence IA directement sur des tracteurs, équipés de capteurs, caméras et GPUs embarqués sur du hardware du type nvidia Jetson. L'objectif est concret et vertueux : analyser les arbres en temps réel pour optimiser la pulvérisation des traitements, réduire le gaspillage des récoltes et améliorer la qualité des produits — une application directe de la précision agricole.
Mais faire tourner des workloads cloud native sur des engins agricoles, souvent déconnectés, en environnement hostile et sans accès réseau, c'est un défi à part entière. La solution ? S'appuyer sur Kairos, projet CNCF Sandbox, pour construire une plateforme où les appareils bootent directement depuis des images de conteneurs : un système immuable et reproductible, tournant sur K3s, géré entièrement "as code". Les mises à jour se font en OTA (Over The Air), sans intervention manuelle sur le terrain.
Une démonstration éloquente que le cloud native n'est pas réservé aux grandes salles climatisées, et que Kubernetes peut prospérer là où on l'attend le moins — y compris à 8h du matin, entre deux rangées d'arbres fruitiers, sans connexion wifi. 🌿
SB💣💣M: Making SBOMs Play Together

Tout a commencé par une erreur de salle — le RAI d'Amsterdam est décidément immense. Mais quelle bonne surprise ! Cette session s'est révélée être vraiment intéressante.
Le contexte : le Cyber Resilience Act (CRA) impose désormais de prouver que le code est sécurisé tout au long de son cycle de vie. L'outil central de cette démarche ? Le SBOM (Software Bill of Materials) — un inventaire transparent de tous les composants d'une application, permettant de tracer les dépendances et d'identifier les vulnérabilités.
En théorie, les outils open source et cloud sont là pour générer ces SBOMs automatiquement. En pratique, c'est une autre histoire : les résultats divergent, se contredisent, et produisent des listes de packages incohérentes d'un outil à l'autre. La session compare plusieurs scanners populaires comme Syft, Trivy ou Scout, et la conclusion est contre-intuitive : celui qui trouve le plus de vulnérabilités n'est pas forcément le meilleur. Exemple parlant : les vulnérabilités liées au kernel n'ont tout simplement aucun sens dans un contexte de conteneurs.
Au cœur du problème : le manque de standardisation des pURL (Package URLs), ces identifiants censés référencer les packages de manière universelle. Sans interopérabilité entre les outils, impossible de construire une chaîne d'approvisionnement logicielle vraiment fiable et conforme.
Un talk passionnant, qui fait écho aux discussions sur le CRA de la keynote du Jour 2. Le hasard fait parfois vraiment bien les choses ! 🎲

Conclusion : Amsterdam, une KubeCon qui marque les esprits
Trois jours de conférences, des side events, des meetups, des labs... et une question qui revient en fil rouge tout au long de la semaine : où va Kubernetes ?
La réponse s'est dessinée progressivement, keynote après keynote, session après session : Kubernetes ne se contente plus d'orchestrer des conteneurs. Il devient l'infrastructure universelle sur laquelle repose l'IA, la souveraineté numérique, la sécurité de la chaîne logicielle, et même... l'agriculture de précision.
Quelques grandes tendances à retenir de cette édition :
- L'IA est partout, mais elle ne réinvente pas Kubernetes — elle révèle sa puissance. L'orchestration, la distribution, le scheduling : tout ce qui a fait le succès de Kubernetes s'applique naturellement aux workloads IA.
- La souveraineté n'est plus un sujet politique, c'est une architecture. Entre le CRA, l'exemple de la SNCF et le concept de Sovereign AI, l'Europe affirme sa volonté de reprendre le contrôle.
- L'écosystème cloud native déborde des data centers : des tracteurs aux planeurs scientifiques du CERN, Kubernetes s'invite là où on ne l'attendait pas.
Et puis, au-delà des technologies, ce qui fait la force de la KubeCon, c'est avant tout sa communauté : des milliers de passionnés qui partagent, contribuent, débattent et construisent ensemble l'infrastructure de demain. Une énergie communicative qui donne envie de retrousser les manches dès le retour au bureau.

Rendez-vous à Barcelone en 2027 ! 🚀🌍


![[KubeCon 25] Comment sécuriser vos conteneurs Kubernetes avec Falco et Talon ?](/content/images/size/w1304/2025/04/falco2.png)





{kind=link}