
Pourquoi une application “à toute épreuve” ?
Le nouveau contexte de la production moderne
Microservices, API tierces, bases partagées, réseaux capricieux, cloud qui scale… les pannes ne sont plus l’exception.
L’objectif n’est plus d’“éviter” l’incident, mais de maintenir un service acceptable même quand tout ne va pas bien.
Un service qui répond lentement peut asphyxier toute la chaîne.
Un composant en panne peut déclencher un effet de cascade.
Un pic de trafic peut rendre l’application indisponible alors qu’aucune erreur “fonctionnelle” ne s’est produite.
De l’application fragile à la forteresse de résilience
L’image de la forteresse résume bien l’idée : on ne se contente pas de mettre des try/catch.
On conçoit la résilience, on l’éprouve, puis on la mesure.
Dans cet article, on construit cette forteresse en trois couches :
- Resilience4j pour la résilience par design (remparts)
- Chaos Monkey pour l’expérimentation (béliers contrôlés)
- Gatling pour valider sous charge (siège à grande échelle)
L’application d’exemple et le code support
Le fil rouge est une application Spring Boot de streaming vidéo (type Disney+/Netflix), basée sur le repo suivant :
On y retrouve un contrôleur MVC, des services métiers, des dépendances externes simulées, une base H2 et des endpoints REST.
Le front est en Thymeleaf, ce qui permet d’illustrer aussi la partie “expérience utilisateur dégradée”.

vous avez le choix entre 2 interfaces, à vous de choisir
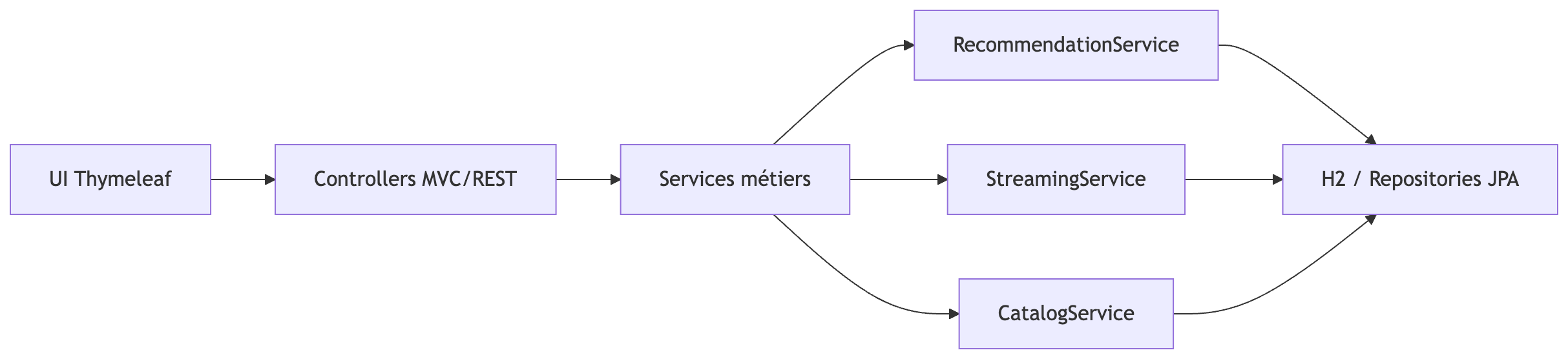
Quelques briques clés du repo :CatalogService, StreamingService, RecommendationService, UserService, des repositories JPA, une UI v1/v2, et des endpoints REST (/api/catalog, /api/streaming, /api/recommendations).
L’objectif est de partir de cette base et de la renforcer couche par couche.
Le trajet d’une requête (et où ça peut casser)
Prenons un parcours “classique” d’utilisateur :
- Il ouvre le catalogue (
GET /api/catalog/videos) - Il lance un stream (
POST /api/streaming/start) - Il récupère des recommandations (
GET /api/recommendations/{userId})
Sur ce trajet, les points de casse sont multiples : base de données, latence réseau, surcharge CPU, services tiers simulés.
L’idée est simple : chaque point de casse mérite un mécanisme de résilience.
Architecture logique (vue simplifiée)
L’article complète trois articles existants :

introduisez du chaos dans votre application spring boot

Résilience applicative avec Resilience4J
Test de charge avec Gatling
L’objectif ici est de les relier dans un même parcours opérationnel.
Poser les fondations : concevoir la résilience avec Resilience4j
Identifier les points de fragilité de l’application
Dans l’application, plusieurs points sont critiques :
- démarrage du streaming (
StreamingService.startStream), - génération de recommandations (
RecommendationService.generateRecommendations), - récupération de données (catalogue, historique, utilisateurs).
Ce sont des appels qui peuvent échouer, ralentir ou saturer.
On commence donc par les cartographier, puis on place des mécanismes de protection.
Exemples concrets de fragilité dans le repo :
- démarrage de stream avec latence simulée (
Thread.sleep(100)),\n- recommandations dépendantes de la base,\n- endpoints de streaming sensibles à la charge (lecture de ressources MP4).
Ce sont des “zones à risque” idéales pour introduire de la résilience.
Pour rendre cela explicite, on peut cartographier risques et contre‑mesures :
| Zone fragile | Risque | Protection |
|---|---|---|
StreamingService.startStream |
Latence / indisponibilité | Timeout + Retry + CircuitBreaker + Fallback |
RecommendationService |
Erreurs DB / surcharge | CircuitBreaker + Fallback |
| Endpoints streaming | Saturation threads | Bulkhead + RateLimiter |
Timeouts et isolation : ne pas subir la lenteur
Un service qui met 30 secondes à répondre ne doit jamais bloquer une requête utilisateur aussi longtemps.
La première brique de résilience, ce sont les timeouts.
Dans ce repo, on illustre le timeout via une exécution encapsulée :
on limite le temps d’un appel avec un Future.get(timeout), et on transforme l’expiration en exception métier.
private <T> T executeWithTimeout(String taskName, Supplier<T> supplier) {
ExecutorService executor = Executors.newSingleThreadExecutor();
try {
log.info("[{}] ⏳ Début attente (Timeout réglé à 2s)...", taskName);
Future<T> future = executor.submit(() -> {
long start = System.currentTimeMillis();
log.info("[{}] 🟢 Thread Worker démarré", taskName);
T result = supplier.get();
log.info("[{}] ✅ Service terminé proprement en {} ms", taskName,
(System.currentTimeMillis() - start));
return result;
});
return future.get(2, TimeUnit.SECONDS);
} catch (TimeoutException e) {
log.error("[{}] 💥 TIMEOUT déclenché ! Fermeture forcée du thread.", taskName);
throw new RequestTimeoutException("Le service a mis trop de temps.");
} catch (InterruptedException | ExecutionException e) {
log.error("[{}] ❌ Erreur : {}", taskName, e.getMessage());
throw new RuntimeException("Erreur lors de l'exécution", e);
} finally {
executor.shutdownNow();
}
}gestion globale du timeOut
Ce n’est pas la seule approche possible, mais elle rend le timeout visible et testable.
Sans timeout, la latence se propage.
Avec un timeout, on borne la dégradation : la requête échoue vite, et on peut basculer sur un fallback.
Cette approche est parfaite pour illustrer la mécanique du timeout et la réaction du système.
Dans une vraie app, on préférera propager le timeout au niveau des clients HTTP (WebClient, RestClient),
afin d’éviter de multiplier des threads dédiés.
Ici, l’objectif pédagogique est clair : voir le timeout, déclencher le fallback, mesurer l’impact.
Circuit Breaker : casser l’effet “marteau‑piqueur”
Le circuit breaker évite d’acharner un service déjà en panne.
Dans RecommendationService, il protège l’appel qui récupère les recommandations :
@CircuitBreaker(name = "recommendationService", fallbackMethod = "fallbackRecommendations")
public List<Recommendation> getRecommendationsForUser(Long userId) {
log.info("Fetching recommendations for user: {}", userId);
return recommendationRepository.findTop10ByUserIdOrderByScoreDesc(userId);
}
En cas de panne, le fallback renvoie un contenu dégradé mais utile :
public List<Recommendation> fallbackRecommendations(Long userId, Throwable t) {
log.warn("Circuit breaker open or error fetching recommendations for user {}. Reason: {}", userId, t.getMessage());
List<Video> popular = videoRepository.findTop10ByOrderByViewCountDesc();
return popular.stream()
.map(v -> new Recommendation(userId, v.getId(), 0.0, "Popular now (Fallback)"))
.collect(Collectors.toList());
}
La configuration associée est déclarée dans application.properties :
resilience4j.circuitbreaker.instances.recommendationService.registerHealthIndicator=true
resilience4j.circuitbreaker.instances.recommendationService.slidingWindowSize=10
resilience4j.circuitbreaker.instances.recommendationService.failureRateThreshold=50
resilience4j.circuitbreaker.instances.recommendationService.waitDurationInOpenState=10s
configuration du circuitBreaker
Ce sont ces paramètres qui dictent quand le disjoncteur s’ouvre et combien de temps il reste ouvert.
Retry et backoff : encaisser les pannes transitoires
Les pannes transitoires (réseau, surcharge temporaire) peuvent souvent être absorbées par un retry contrôlé.
Dans StreamingService, un retry est appliqué sur le démarrage du stream :
@Retry(name = "streamingService", fallbackMethod = "fallbackStartStream")
@CircuitBreaker(name = "streamingService")
public Map<String, Object> startStream(Long userId, Long videoId) {
// ...
}
La configuration du retry est centralisée dans application.properties :
resilience4j.retry.instances.recommendationService.maxAttempts=3
resilience4j.retry.instances.recommendationService.waitDuration=500ms
resilience4j.retry.instances.streamingService.maxAttempts=3
resilience4j.retry.instances.streamingService.waitDuration=1s
configuration du retry
On reste volontairement raisonnable sur le nombre de tentatives pour ne pas saturer un service déjà fragile.
2026-03-20T08:24:11.905+01:00 INFO 62729 --- Attempting to start stream for user: 1 and video: 15
2026-03-20T08:24:11.916+01:00 INFO 62729 --- Chaos Monkey - exception
2026-03-20T08:24:12.919+01:00 INFO 62729 --- Attempting to start stream for user: 1 and video: 15
2026-03-20T08:24:12.929+01:00 INFO 62729 --- Chaos Monkey - exception
2026-03-20T08:24:13.932+01:00 INFO 62729 --- Attempting to start stream for user: 1 and video: 15
2026-03-20T08:24:13.935+01:00 INFO 62729 --- Chaos Monkey - exceptionon peut voir le retry en action dans les logs
Bulkhead et Rate Limiter : protéger les ressources internes
Même si un service externe tombe, il ne doit pas consommer tous les threads de l’application.
C’est exactement le rôle des bulkheads (sémaphores ou pools dédiés) et des rate limiters.
Dans ce repo, ils ne sont pas encore activés, mais l’architecture est prête.
On pourrait isoler les appels vers des dépendances externes en dédiant un pool par service.
L’idée est simple : même si RecommendationService s’effondre, StreamingService doit continuer à fonctionner.
La résilience ne sert à rien si un seul composant peut “tout faire tomber”.
Fallbacks : offrir une expérience dégradée mais contrôlée
La résilience n’est pas seulement “ne pas planter”.
C’est rendre un service acceptable même dégradé.
Dans StreamingService, le fallback fournit un statut explicite :
public Map<String, Object> fallbackStartStream(Long userId, Long videoId, Throwable t) {
log.error("Streaming service error for user {} and video {}. Reason: {}", userId, videoId, t.getMessage());
log.info("Returning unavailable status as fallback for stream request");
Map<String, Object> streamInfo = new HashMap<>();
streamInfo.put("userId", userId);
streamInfo.put("videoId", videoId);
streamInfo.put("streamUrl", "");
streamInfo.put("quality", "N/A");
streamInfo.put("status", "TEMPORARILY_UNAVAILABLE");
streamInfo.put("error", t.getMessage());
return streamInfo;
}notre fallback en cas de problème de streaming
2026-03-20T08:24:13.937+01:00 ERROR 62729 --- Streaming service error for user 1 and video 15. Reason: Video not found
2026-03-20T08:24:13.937+01:00 INFO 62729 --- Returning unavailable status as fallback for stream requestsuite des logs de retry, trop d'échec, on arrive dans le fallback
Pour l’utilisateur, la différence est majeure :
on ne renvoie pas une erreur opaque, on renvoie une réponse compréhensible et gérable côté UI.
Dans l’application, les pages d’erreur sont thématiques, ce qui renforce cette logique de “dégradation contrôlée”.
Mettre la forteresse à l’épreuve : Chaos Monkey en environnement contrôlé
Pourquoi le chaos est indispensable à la résilience
Sans expérimentation, la résilience reste théorique.
Le chaos engineering permet de valider en conditions contrôlées que les mécanismes de protection fonctionnent vraiment.
Brancher Chaos Monkey sur l’application Spring Boot
Le repo intègre chaos-monkey-spring-boot directement dans le module chaos-application :
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>chaos-monkey-spring-boot</artifactId>
<version>4.0.0</version>
</dependency>
la dépendance vers la version 4, ça y est on peut casser les applications Spring Boot 4
Un profil dédié active l’exposition des endpoints dans application-chaos-monkey.yaml :
management:
endpoint:
chaosmonkey:
enabled: true
endpoints:
web:
exposure:
include: chaosmonkey, health, info, circuitbreakers, retries
extrait de notre application.yml
On lance l’application avec ce profil : chaos-monkey.
Pour en savoir plus sur les profils dans Spring Boot, c'est par ici :

les profils dans spring boot, comment et pourquoi ?
Ce qui nous permet d'avoir dans la console au démarrage, la petite bannière chaos monkey :

Nous pouvons désormais piloter le chaos via les actuators spring boot :

Simuler la latence : tester les timeouts et les retries
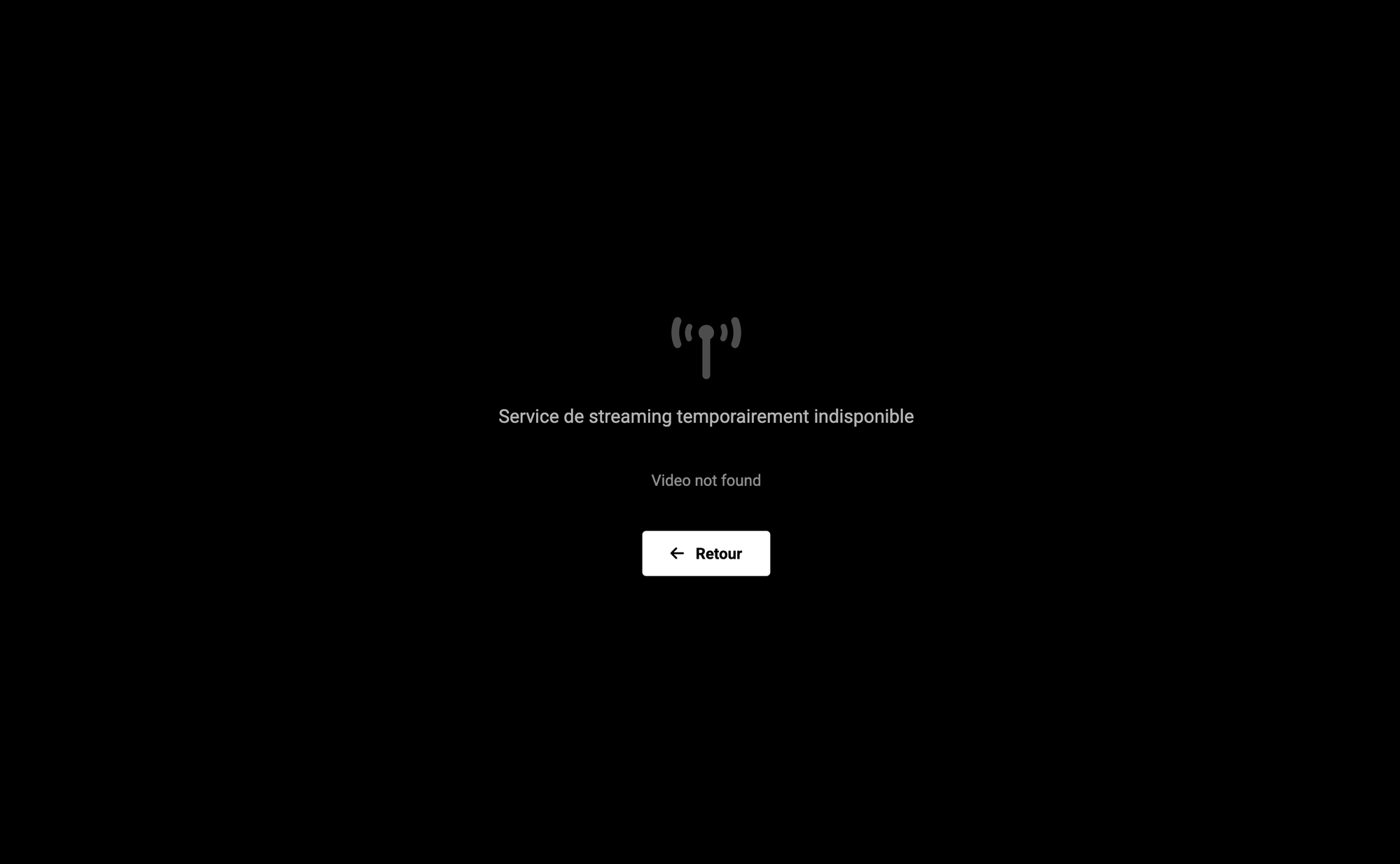
Scénario : injection de latence sur StreamingService.
On observe alors :
- des timeouts côté client,
- des retries Resilience4j,
- et, si la panne persiste, le fallback.
Exemple simple pour déclencher un stream :
curl -X POST http://localhost:8080/api/streaming/start \\
-H \"Content-Type: application/json\" \\
-d '{\"userId\": 1, \"videoId\": 1}'
Provoquer des erreurs : valider le circuit breaker
Scénario : injection d’exceptions sur les recommandations.
Le circuit breaker s’ouvre, et l’on bascule vers le fallback “contenu populaire”.
Exemple côté recommandations :
curl http://localhost:8080/api/recommendations/1
Quand le breaker s’ouvre, la réponse reste valide, mais le contenu devient “Popular now (Fallback)”.
2026-03-20T12:49:36.510+01:00 INFO 78533 --- Fetching recommendations for user: 2
2026-03-20T12:49:36.511+01:00 INFO 78533 --- Circuit breaker open or error fetching recommendations for user 2. Reason: Simulation d’erreur pour ouvrir le CB dès la première tentative
2026-03-20T12:49:36.512+01:00 INFO 78533 --- Returning popular content as fallback recommendations for user 2Documenter les scénarios de chaos dans le code
Les scénarios doivent être reproductibles.
L’idée est de documenter clairement :
- les endpoints Actuators utilisés,
- les types de pannes injectées,
- la réaction attendue (fallback, breaker, logs).
Une bonne pratique consiste à conserver un petit runbook dans le repo ou dans le README (mais si vous savez, ces fichiers en markdown rarement mis à jour par nous autre développeurs) avec les commandes à rejouer.
Exemple de runbook minimal :
# Activer le chaos
curl -X POST http://localhost:8080/actuator/chaosmonkey/enable
# Vérifier l’état des breakers
curl http://localhost:8080/actuator/circuitbreakers
# Tester un stream
curl -X POST http://localhost:8080/api/streaming/start \\
-H \"Content-Type: application/json\" \\
-d '{\"userId\": 1, \"videoId\": 1}'
exemple de runbook
Tester la forteresse sous pression : charge et performance avec Gatling
Pourquoi la résilience doit résister à la montée en charge
Certaines faiblesses n’apparaissent qu’avec la charge : saturation de pools, ouverture du circuit breaker, montée des erreurs.
Le test de charge valide que les remparts tiennent quand la pression augmente.
Scénario de charge : reproduire un trafic réaliste
Le scénario Gatling (ChaosSimulation) simule des parcours d’utilisateurs réalistes :
- navigation catalogue,
- démarrage d’un streaming,
- visionnage partiel,
- mise à jour de progression.
Il alterne plusieurs profils (browser, watcher, social_watcher) pour éviter un trafic artificiel.
Extrait d’assertions définies dans la simulation :
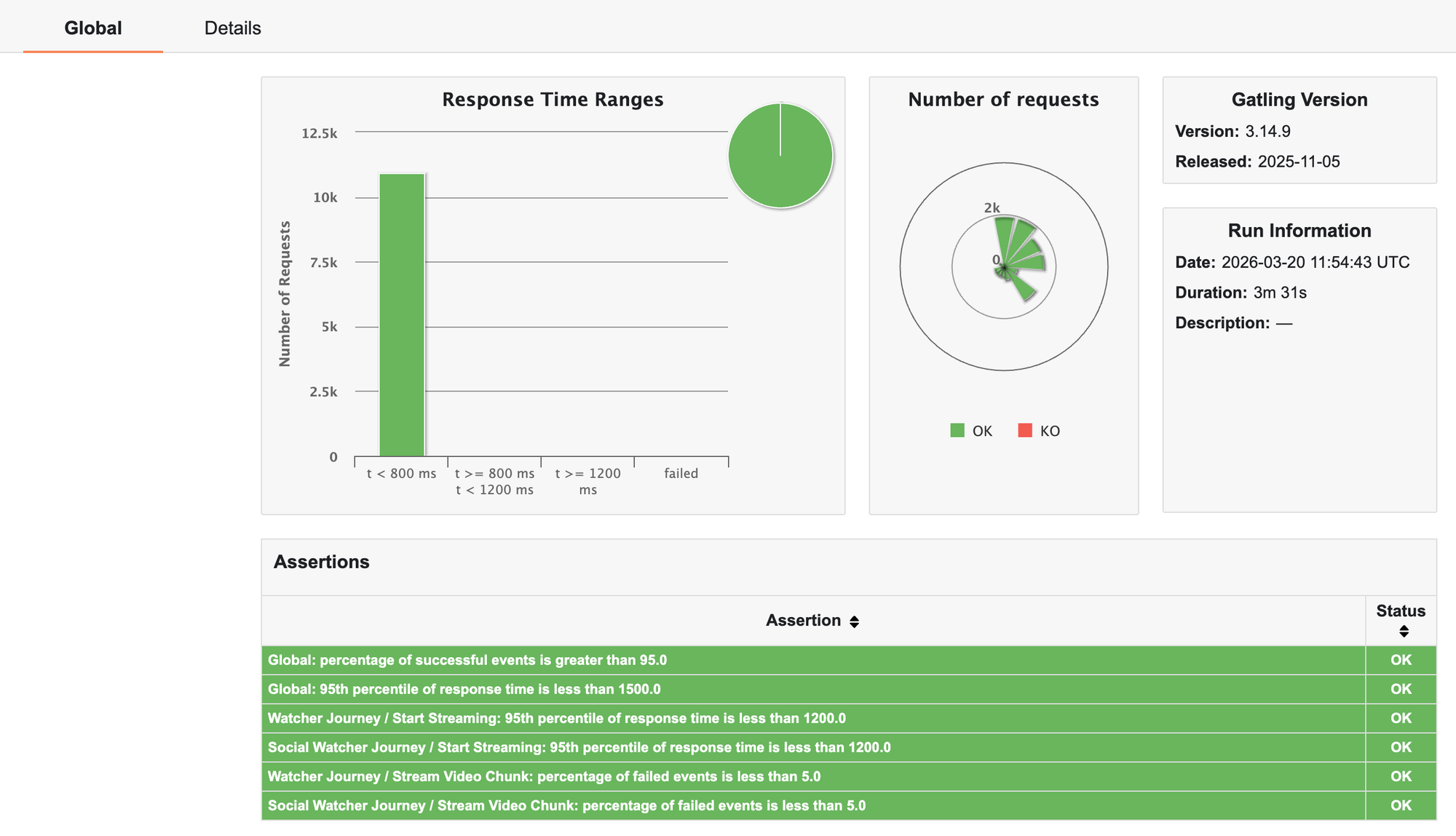
assertions(
global().successfulRequests().percent().gt(95.0),
global().responseTime().percentile3().lt(1500),
details("Watcher Journey", "Stream Video Chunk").failedRequests().percent().lt(5.0)
)
Gatling génère automatiquement un rapport HTML par exécution.
On peut donc comparer avec et sans chaos très visuellement.
Les rapports se trouvent dans :gatling-test/target/gatling/
chaque exécution crée un dossier daté avec un index.html.
public ChaosSimulation() {
System.out.printf("[ChaosSimulation] baseUrl=%s%n", BASE_URL);
setUp(
userJourneyScenario.injectOpen(
incrementUsersPerSec(5)
.times(5)
.eachLevelLasting(Duration.ofSeconds(30))
.separatedByRampsLasting(Duration.ofSeconds(10))
.startingFrom(10)
)
).protocols(HTTP_PROTOCOL)
.assertions(
global().successfulRequests().percent().gt(95.0),
global().responseTime().percentile3().lt(1500),
details("Watcher Journey", "Start Streaming").responseTime().percentile3().lt(1200),
details("Social Watcher Journey", "Start Streaming").responseTime().percentile3().lt(1200),
details("Watcher Journey", "Stream Video Chunk").failedRequests().percent().lt(5.0),
details("Social Watcher Journey", "Stream Video Chunk").failedRequests().percent().lt(5.0)
);
}Lancement de la simulation Gatling
Interpréter les résultats : SLO et décisions concrètes
Une simulation Gatling ou un run Chaos Monkey n’a de valeur que si elle est reliée à des objectifs précis. Il ne s’agit pas de constater que “ça casse”, mais de mesurer où et comment la résilience tient.
Quelques indicateurs clés :
- Taux de succès global : pourcentage de requêtes ayant renvoyé un statut attendu (200 OK par ex.).
- Percentiles de latence (95/99) : indiquent la réactivité de l’application sous charge.
- Taux de réponses dégradées : proportion de requêtes ayant utilisé un fallback.
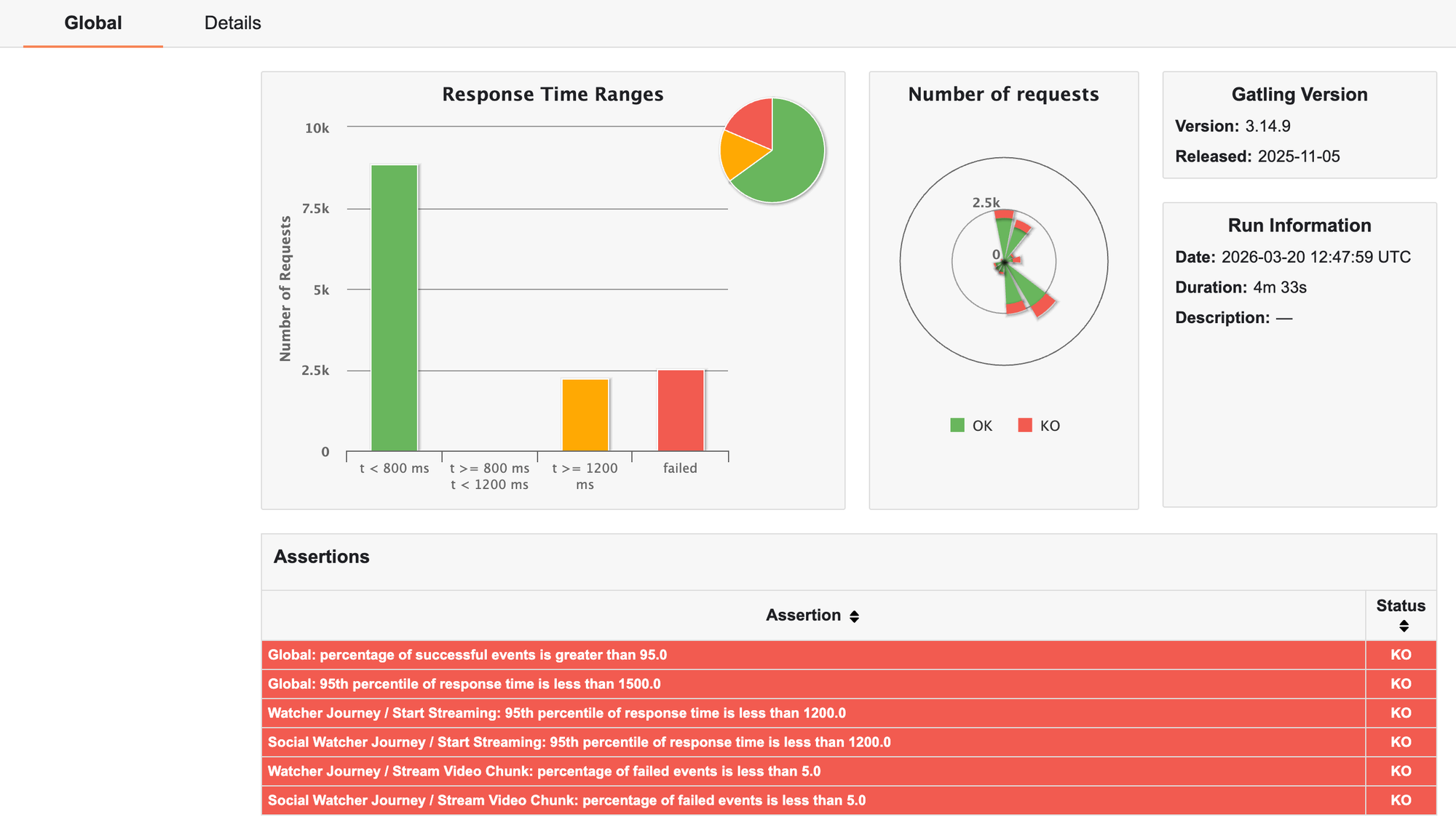
En pratique, un résultat comme celui-ci :
Succès global : 81 %
95e percentile : 5,4 s
Stream Video Chunk échoué : 46 %
indique clairement que certains services subissent des saturations ou des erreurs non absorbées.
Décisions concrètes à partir de ces observations :
- Ajuster le circuit breaker : augmenter la fenêtre ou réduire le seuil de détection si le breaker s’ouvre trop tôt.
- Revoir le nombre de retries : limiter les tentatives si elles aggravent la charge, ou au contraire les augmenter si la panne est transitoire.
- Limiter la charge sur les endpoints critiques : utiliser bulkhead ou rate limiter pour protéger les threads et ressources internes.
- Optimiser la latence ou les traitements : identifier les points qui prennent trop de temps et appliquer un timeout ou une isolation.
L’idée centrale : la résilience est itérative. On observe, on ajuste, on reteste, jusqu’à atteindre un compromis acceptable entre disponibilité, latence et charge.
Voir pour croire : observabilité et signaux de résilience
Instrumenter les patterns de résilience
Les métriques Resilience4j sont exposées via Actuator :
GET /actuator/circuitbreakersGET /actuator/retries
Ces métriques permettent de savoir quand un breaker s’ouvre, combien de retries sont déclenchés, et à quelle fréquence.
Dans le profil chaos-monkey, la santé des breakers est aussi exposée via health :
management:
health:
circuitbreakers:
enabled: true
Cela donne une lecture simple : breaker ouvert = état dégradé.
{
"circuitBreakers": {
"recommendationService": {
"bufferedCalls": 20,
"failedCalls": 4,
"failureRate": "20.0%",
"failureRateThreshold": "40.0%",
"notPermittedCalls": 0,
"slowCallRate": "15.0%",
"slowCallRateThreshold": "50.0%",
"slowCalls": 3,
"slowFailedCalls": 0,
"state": "CLOSED"
},
"streamingService": {
"bufferedCalls": 2,
"failedCalls": 1,
"failureRate": "50.0%",
"failureRateThreshold": "40.0%",
"notPermittedCalls": 39,
"slowCallRate": "50.0%",
"slowCallRateThreshold": "50.0%",
"slowCalls": 1,
"slowFailedCalls": 0,
"state": "OPEN"
}
}
}Un aperçu de nos circuits breakers après le test de charge
Dashboards et alertes : surveiller la forteresse en continu
Même sans stack Prometheus/Grafana, un tableau minimal (latence + état des breakers) donne une vraie lecture.
Cela permet d’identifier les dérives avant que la prod ne souffre.
Avec une stack métriques, on peut afficher :
- ratio d’erreurs vs trafic,
- latence moyenne vs percentile 95/99,
- état des breakers (closed/open/half-open).
Conclusion
Construire une application “à toute épreuve” ne se résume pas à quelques annotations. Il s’agit d’une démarche globale :
- Concevoir la résilience : identifier les zones à risque, appliquer timeout, circuit breaker, retry, fallback.
- Tester la résilience : injecter des latences et erreurs via Chaos Monkey, simuler la charge via Gatling.
- Mesurer et surveiller : suivre les metrics Resilience4j, les taux de succès, les percentiles de latence et les réponses dégradées.
Avec cette approche, une application peut continuer à servir un système acceptable, même sous pression, et offrir à l’utilisateur une expérience cohérente, dégradée mais compréhensible. La résilience devient alors un processus mesurable et répétable, et non une simple réaction aux incidents.









{kind=link}