
J'adore les jeux de société, et la ludothèque commence à prendre une place très sérieuse à la maison.

Le problème, c’est qu’avec l’accumulation des boîtes, on finit par hésiter sur des détails de règles en pleine partie. Et dans ce moment-là, on veut une réponse rapide, sourcée, et sans débat infini autour de la table.
Dans De la question naturelle à la requête JPA : tool calling avec Spring AI, nous avons vu comment connecter un LLM à des tools métier.
Ici, nous changeons d’angle : les réponses ne viennent plus d’une base relationnelle, mais d’un corpus documentaire de règles.
Objectif : construire une API REST qui répond à des questions en langage naturel sur des jeux de société avec un pipeline RAG local.
Le besoin réel
Quand on demande :
- "Comment gagne-t-on à Prey Another Day ?"
- "Cette action est-elle autorisée pendant l’appel ?"
on veut une réponse basée sur la règle, pas une improvisation probable du modèle.
Le RAG répond à ce besoin :
- ingestion des règles,
- découpage en chunks,
- embeddings + indexation,
- recherche des passages pertinents,
- génération d’une réponse sourcée.
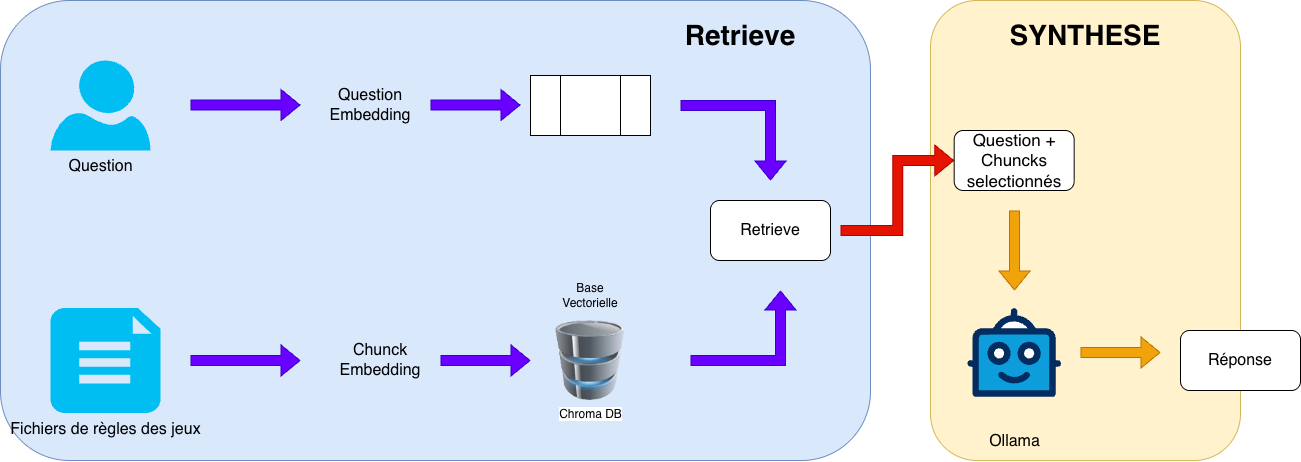
Stack technique
- Spring Boot
- Spring AI (
ollama+vector-store-chroma) - Ollama local (chat + embeddings)
- Chroma pour le stockage vectoriel
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-chroma</artifactId>
</dependency>
les dépendances nécessaires
API exposée
Le point d’entrée est volontairement minimal :
POST /api/ludo/rules/ask
@RestController
@RequestMapping("/api/ludo/rules")
public class LudoRuleController {
private final RuleRagService ruleRagService;
public LudoRuleController(RuleRagService ruleRagService) {
this.ruleRagService = ruleRagService;
}
@PostMapping("/ask")
public RuleAnswerResponse ask(@RequestBody RuleQuestionRequest request) {
// Le controller ne "réfléchit" pas: il délègue la logique RAG au service
return ruleRagService.answer(request.question(), request.game());
}
}
un controller minimaliste
Le contrôleur reste volontairement fin : il reçoit la requête, puis délègue toute l’orchestration au service RAG.
Cette séparation garde l’API lisible et facilite les tests unitaires.
Chargement du corpus de règles
Les fichiers .md sont stockés dans src/main/resources/rules.
Le loader les lit puis les découpe par section (##) pour conserver une granularité métier.
@Component
public class RuleCorpusLoader {
public List<Document> loadAllRules() {
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
try {
Resource[] resources = resolver.getResources("classpath:/rules/*.md");
List<Document> documents = new ArrayList<>();
for (Resource resource : resources) {
String content = resource.getContentAsString(StandardCharsets.UTF_8);
String filename = resource.getFilename() != null ? resource.getFilename() : "unknown";
String game = filename.replace(".md", "").replace('-', ' ').trim();
documents.addAll(toSectionDocuments(content, game, filename));
}
return documents;
}
catch (IOException e) {
throw new IllegalStateException("Unable to load boardgame rules corpus", e);
}
}
private List<Document> toSectionDocuments(String markdown, String game, String source) {
List<Document> docs = new ArrayList<>();
Map<String, StringBuilder> sections = splitMarkdownBySection(markdown);
for (Map.Entry<String, StringBuilder> entry : sections.entrySet()) {
String section = entry.getKey();
String text = entry.getValue().toString().trim();
if (text.isBlank()) {
continue;
}
// Ces métadonnées seront réutilisées pour filtrer, tracer et afficher les sources.
docs.add(new Document(text).mutate()
.metadata("game", game)
.metadata("source", source)
.metadata("section", section)
.build());
}
return docs;
}
}
préparation des règles avant ingestion dans le RAG
Ce découpage par sections améliore la pertinence des réponses et la lisibilité des preuves renvoyées (section, excerpt, score).
Les métadonnées jouent un rôle clé dans la qualité finale :
gamepermet de filtrer les passages quand l'utilisateur cible un jeu précis,sectionaméliore l'explicabilité de la réponse (on sait d'où vient l'information),sourcefacilite le retour au document d'origine et les vérifications.
Sans ces métadonnées, le moteur peut retrouver un texte proche sémantiquement, mais il devient plus difficile de prioriser correctement les résultats et d'afficher des sources utiles côté API.
Pourquoi du Markdown et pas directement du PDF ?
C'est un choix d'ingénierie, pas un choix esthétique.
Un PDF est parfait pour la lecture humaine, mais souvent moins pratique pour un pipeline RAG :
- l'extraction de texte peut mélanger titres, en-têtes, pieds de page et colonnes,
- la structure logique (sections, sous-sections, listes) est parfois difficile à reconstituer,
- le chunking devient moins prédictible et donc moins pertinent.
Avec du Markdown, nous gagnons sur plusieurs axes :
- structure explicite (
#,##, listes) facile à parser, - découpage plus propre par sections métier,
- métadonnées plus fiables (
game,source,section), - meilleure qualité de retrieval,
- meilleure traçabilité des sources affichées à l'utilisateur.
Et surtout : cela aide à maîtriser la taille du contexte envoyé au modèle.
Un corpus brut issu de PDF tend à produire des chunks trop longs ou trop bruités, ce qui augmente :
- le risque de dépasser la fenêtre de contexte (chat ou embeddings),
- le coût de traitement,
- le bruit dans la réponse finale.
Le compromis retenu ici est donc :
- source officielle en PDF,
- restructuration en Markdown propre,
- ingestion RAG sur la version structurée.
Indexation dans Chroma au démarrage
L’indexeur est exécuté au startup via CommandLineRunner.
Il segmente les sections en chunks, borne leur taille, puis les pousse dans le VectorStore.
@Component
public class RuleDocumentIndexer implements CommandLineRunner {
private final RuleCorpusLoader ruleCorpusLoader;
private final VectorStore vectorStore;
private final boolean reindexOnStartup;
private final int maxChunkChars;
public RuleDocumentIndexer(RuleCorpusLoader ruleCorpusLoader,
VectorStore vectorStore,
@Value("${app.rag.reindex-on-startup:true}") boolean reindexOnStartup,
@Value("${app.rag.max-embedding-chunk-chars:1200}") int maxChunkChars) {
this.ruleCorpusLoader = ruleCorpusLoader;
this.vectorStore = vectorStore;
this.reindexOnStartup = reindexOnStartup;
this.maxChunkChars = maxChunkChars;
}
@Override
public void run(String... args) {
if (!reindexOnStartup) {
return;
}
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(220)
.withMinChunkSizeChars(80)
.withMinChunkLengthToEmbed(40)
.withMaxNumChunks(20_000)
.withKeepSeparator(true)
.build();
List<Document> chunks = new ArrayList<>();
for (Document sectionDoc : ruleCorpusLoader.loadAllRules()) {
List<Document> split = splitter.split(sectionDoc);
int chunkIndex = 0;
for (Document splitChunk : split) {
for (String safeText : splitToMaxChars(splitChunk.getText(), maxChunkChars)) {
chunks.add(new Document(safeText).mutate()
// ID stable pour éviter les collisions lors des réindexations
.id(sectionDoc.getMetadata().get("source") + "#"
+ sectionDoc.getMetadata().get("section") + "#" + chunkIndex)
.metadata(sectionDoc.getMetadata())
.metadata("chunk", chunkIndex)
.build());
chunkIndex++;
}
}
}
vectorStore.add(chunks);
}
}
Point important : le bornage (max-embedding-chunk-chars) évite les erreurs de contexte de l’embed model sur des règles longues.
Service RAG : retrieval + synthèse
Le service récupère des chunks pertinents, construit un contexte borné, puis demande au LLM de répondre en s’appuyant sur ce contexte.
@Service
public class RuleRagService {
private final VectorStore vectorStore;
private final ChatClient chatClient;
public RuleRagService(VectorStore vectorStore, ChatClient.Builder chatClientBuilder) {
this.vectorStore = vectorStore;
this.chatClient = chatClientBuilder.build();
}
public RuleAnswerResponse answer(String question, String game) {
SearchRequest request = SearchRequest.builder()
.query(question)
.topK(20)
.build();
List<Document> candidates = vectorStore.similaritySearch(request);
// Filtrage fonctionnel: si un jeu est demandé, on priorise ce jeu.
List<Document> filtered = candidates.stream()
.filter(doc -> game == null || game.isBlank() || game.equalsIgnoreCase((String) doc.getMetadata().get("game")))
.toList();
String context = filtered.stream()
.limit(8)
.map(Document::getText)
.collect(Collectors.joining("\n\n---\n\n"));
String answer = chatClient.prompt()
.system("""
Vous êtes un assistant de règles de jeux de société.
Répondez uniquement à partir du contexte fourni.
Si l'information manque, dites-le explicitement.
""")
.user("Question: " + question + "\n\nContexte:\n" + context)
.call()
.content();
return RuleAnswerResponse.from(question, game, answer, filtered);
}
}
Concrètement, on évite la "magie" implicite : stratégie de retrieval, filtrage et cadrage du prompt restent dans du code explicite et versionné.
Configuration applicative
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: llama3.2
embedding:
options:
model: mxbai-embed-large
vectorstore:
chroma:
client:
host: http://localhost
port: 8000
initialize-schema: false
tenant-name: default_tenant
database-name: default_database
collection-name: boardgame-rules
app:
rag:
reindex-on-startup: true
retrieval-top-k: 20
max-context-tokens: 1200
max-embedding-chunk-chars: 1200
Sur cette brique, nous avons aussi dû gérer l’initialisation explicite de la collection Chroma au démarrage pour éviter les erreurs de bootstrap.
Point tricky : bootstrap de la collection Chroma
Un point moins visible, mais important en pratique : au démarrage, le ChromaVectorStore tente d'utiliser la collection configurée.
Si la collection n'existe pas encore, on peut tomber sur une erreur de type :
Collection [boardgame-rules] does not exist
La solution retenue dans le module consiste à initialiser explicitement le schéma Chroma (tenant, database, collection) avant de construire le VectorStore.
@Configuration
public class ChromaCollectionBootstrapConfiguration {
@Bean
ChromaVectorStore vectorStore(EmbeddingModel embeddingModel,
ChromaApi chromaApi,
ChromaVectorStoreProperties properties,
ObjectProvider<ObservationRegistry> observationRegistry,
ObjectProvider<VectorStoreObservationConvention> customObservationConvention,
BatchingStrategy chromaBatchingStrategy) {
String tenant = properties.getTenantName();
String database = properties.getDatabaseName();
String collection = properties.getCollectionName();
createTenantIfMissing(chromaApi, tenant);
createDatabaseIfMissing(chromaApi, tenant, database);
createCollectionIfMissing(chromaApi, tenant, database, collection);
return ChromaVectorStore.builder(chromaApi, embeddingModel)
.tenantName(tenant)
.databaseName(database)
.collectionName(collection)
.initializeSchema(false)
.observationRegistry(observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP))
.customObservationConvention(customObservationConvention.getIfAvailable(DefaultVectorStoreObservationConvention::new))
.batchingStrategy(chromaBatchingStrategy)
.build();
}
}
configuration de chroma
Ce bootstrap évite les démarrages aléatoires liés à l'ordre d'initialisation des beans. Il reste idempotent (création si absent, pas d'échec si déjà présent) et simple à tester.
Exemple d’appel
Ici je me pose une question sur Prey Another Day, un petit jeu d'ambiance bien sympa pour égayer vos soirées

curl -X POST "http://localhost:8080/api/ludo/rules/ask" \
-H "Content-Type: application/json" \
-d '{
"question": "À Prey Another Day, comment gagner la partie ?",
"game": "prey another day"
}'
exemple de requête envoyée au service
Réponse :
- un texte synthétique,
- des sources avec
game,source,section,excerpt,score.
{
"question": "À Prey Another Day, comment gagner la partie ?",
"game": "prey another day",
"answer": "Pour gagner la partie à Prey Another Day, il faut cumuler 5 jetons Nourriture. Cela peut se faire de différentes manières :\n\n* Soit une seule personne atteint 5 jetons Nourriture avant les autres joueurs.\n* Si plusieurs joueurs atteignent 5 jetons Nourriture au même tour avec le même total, la partie continue jusqu'à ce qu'un joueur ait strictement le plus grand nombre de jetons.\n\n Il faut que ce seuil soit atteint pour gagner la partie.",
"retrievedDocuments": 9,
"sources": [
{
"game": "prey another day",
"source": "prey-another-day.md",
"section": "general",
"excerpt": "Source officielle : https://media.play-in.com/pdf/rules_games/prey_another_day_fr.pdf\n\n> Note : texte restructuré en Markdown pour l'indexation RAG.",
"score": 0.7869998216629028
},
....
]
}la réponse à notre question
Cette traçabilité est essentielle pour la confiance utilisateur.
Aller plus loin
- enrichir les métadonnées (version de règle, extension, langue, éditeur),
- ajouter un reranker pour mieux ordonner les chunks,
- exclure certaines sections de bruit (mentions légales, sommaires),
- gérer une déduplication inter-chunks plus stricte,
- ajouter un mode "citation stricte" (réponse uniquement appuyée sur extraits),
- historiser les questions pour identifier les zones de règles ambiguës,
- exposer des métriques via les actuators (lien à mettre) et les exploiter via prometheus et grafana.
Conclusion
Avec ce module, nous passons d’une question naturelle appliquée à des données relationnelles à une question naturelle appliquée à un corpus documentaire. Le pattern RAG permet d’obtenir des réponses synthétiques tout en gardant un lien explicite avec les sources, ce qui limite les hallucinations et améliore la confiance dans le résultat.
Dans le cas d’une ludothèque, cela permet de retrouver rapidement un point de règle sans interrompre la partie pour parcourir un livret ou un PDF.
Plus largement, ce type d’architecture s’applique très bien à des bases de connaissances, de la documentation technique ou du support client. Avec Spring AI, ces briques restent intégrées dans une architecture classique Spring Boot : explicite, testable et maîtrisée.
Et au passage, cela permet aussi d’arbitrer plus vite autour de la table… et de reprendre la partie.
Tout le code relatif à cet article est trouvable ici :





{kind=link}