
Les fuites mémoire ou memory leaks font partie d’une classe de bugs qui sont assez difficiles à reproduire et à corriger. Je vous propose ici, un cas d’étude de fuite mémoire que j’ai récemment rencontré. Nous verrons comment traquer et expliquer l'origine de cette fuite.
Mise en situation
Pour placer un peu de contexte, le projet sur lequel j’ai travaillé était une application classique Java en Spring Boot 2.x communiquant avec une base de données PostgreSQL. Dans la majeure partie du temps, un framework ORM est utilisé pour la gestion de la persistance, et pour cela, Hibernate est le plus populaire, ce projet n’y fait pas exception.
L’application étant déployée sur le Cloud, les développeurs ont pu observer, à travers des outils de monitoring, une augmentation régulière et continue de la consommation mémoire (RAM) sur plusieurs jours jusqu’à ce qu’elle atteigne un seuil critique où l’application terminait en erreur avec pour motif :
2023-11-12 16:03:57.635 ERROR 10403 --- [nio-8080-exec-1] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Handler dispatch failed; nested exception is java.lang.OutOfMemoryError: Java heap space] with root cause
java.lang.OutOfMemoryError: Java heap spaceIl est plus fréquent qu’une application se termine avec d’autres types d'erreurs plus classiques comme les NullPointerException plutôt qu’un java.lang.OutOfMemoryError: Java heap space.
A partir de cette information, nous allons chercher et tenter de trouver l’origine du problème.
Dans cet article, je vais prendre pour référence ce petit projet qui va mettre en évidence le problème du cache de requête (Query Plan Cache) d’Hibernate 5 : Hibernate-in-clause-memory-leak
Identifier une fuite mémoire
Commençons par définir ce qu’est une fuite mémoire. Il s’agit d’une occupation croissante et non contrôlée de la mémoire qui est dû à la présence de données qui ne sont plus utiles mais qui ne sont pas libérées.
Dans la même veine que les fuites mémoires, il existe aussi le concept de fuite d’espace (Space Leak). Contrairement à une fuite mémoire dont l’espace n’est jamais libéré, une fuite d’espace libère bien la mémoire mais cette libération arrive bien plus tard qu’espérée. Dans le cas d’étude présenté dans cet article, on se rapproche plutôt d’une fuite d’espace.
Un Out Of Memory ne veut pas forcément indiquer une fuite mémoire. En effet, cela indique seulement que la JVM a consommé toute la mémoire qui lui a été allouée et que le Garbage Collector n’a pas été capable de réclamer suffisamment d’espace. Cela peut-être dû simplement à une consommation excessive de mémoire ou effectivement à une fuite mémoire.
Il est possible d’observer autrement s’il y a effectivement une fuite mémoire et ce, à l’aide d’outils de monitoring comme VisualVM ou alors ceux fournit par le service de Cloud. Afin de comprendre visuellement comment on identifie une fuite mémoire, il faut avant tout connaître le comportement de la mémoire dans le cas d’usage classique.
Évolution classique de la mémoire
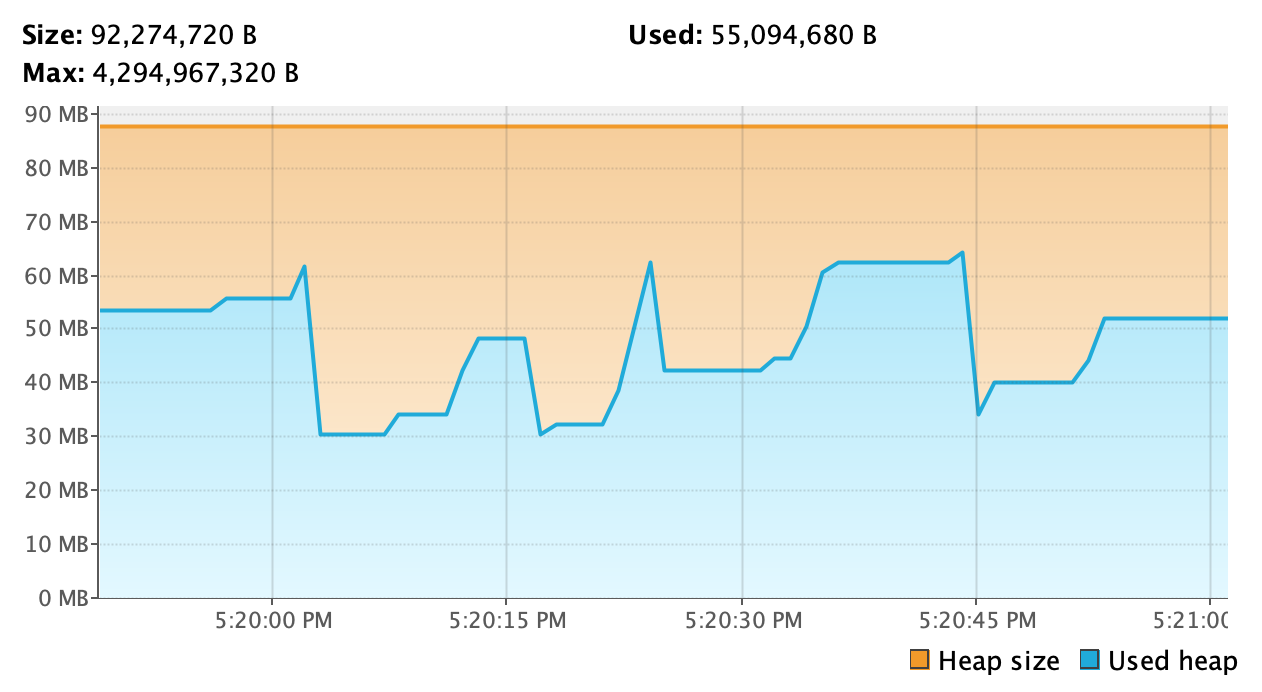
Dans le cas général, la courbe de consommation mémoire est relativement stable. Lors de traitements, la mémoire est utilisée et libérée aux grés des Garbage collections de la JVM.
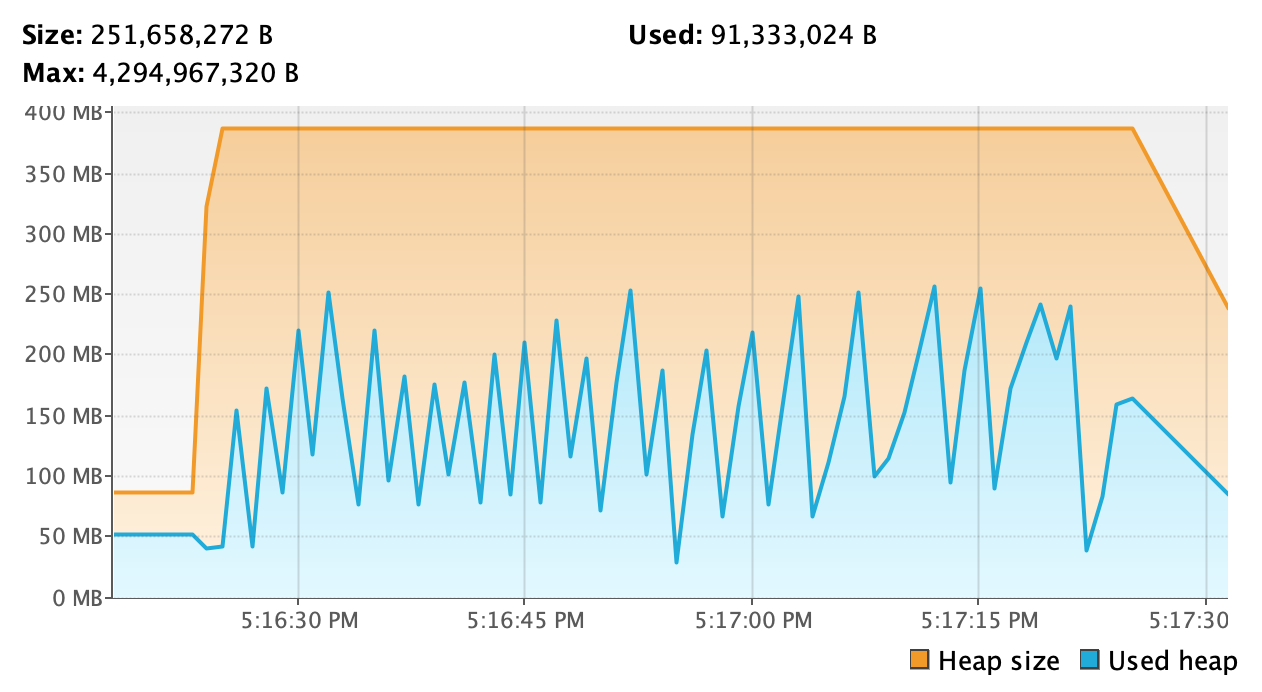
Dans certains cas, il est aussi possible d’observer des courbes en dents de scies qui n’est pas indicatif d’un problème mais qui peut être expliqué par le fait que dans une très grande majorité de cas, les objets ont une durée de vie très faible. Typiquement, les applications transactionnelles allouent des objets pour n’être utilisés qu’au sein d’une transaction. L’espace mémoire de ces mêmes objets sont ensuite rapidement réclamés lors des Minor Garbage Collection.
Fuite mémoire
Dans le cas d’une fuite mémoire, on peut généralement observer un accroissement continue de la consommation mémoire indiquant une accumulation d’objets qui ne sont pas réclamés par le Garbage Collector. In fine, la JVM consommera toute la mémoire qui lui est allouée et terminera en Out Of Memory.
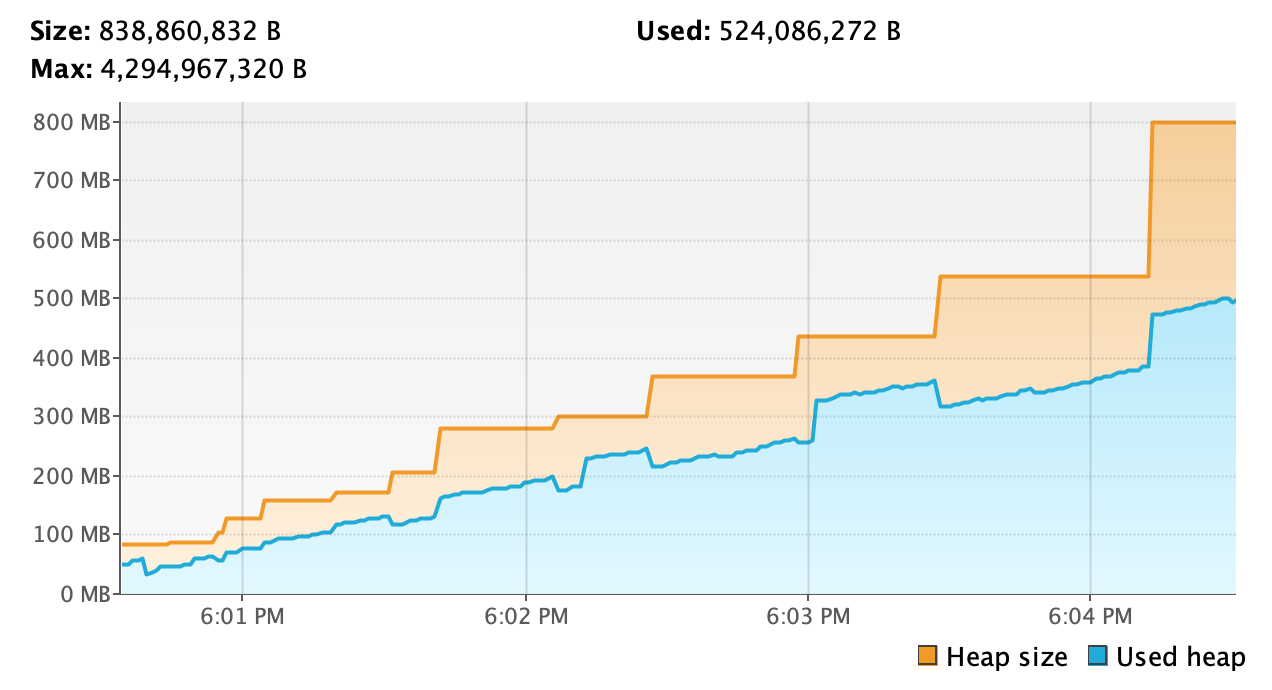
Dans d’autres cas, il est aussi possible d’observer une courbe logarithmique dont le seuil tend vers la limite de la quantité de mémoire allouée par la JVM. Elle est expliquée par le fait que, étant donné que la quantité de mémoire restante disponible est faible, le Garbage Collector de la JVM va passer la majeur partie du temps à tenter de réclamer de l’espace mémoire mais ne sera capable d’en libérer qu’une infime partie par rapport aux besoins du traitement en cours.
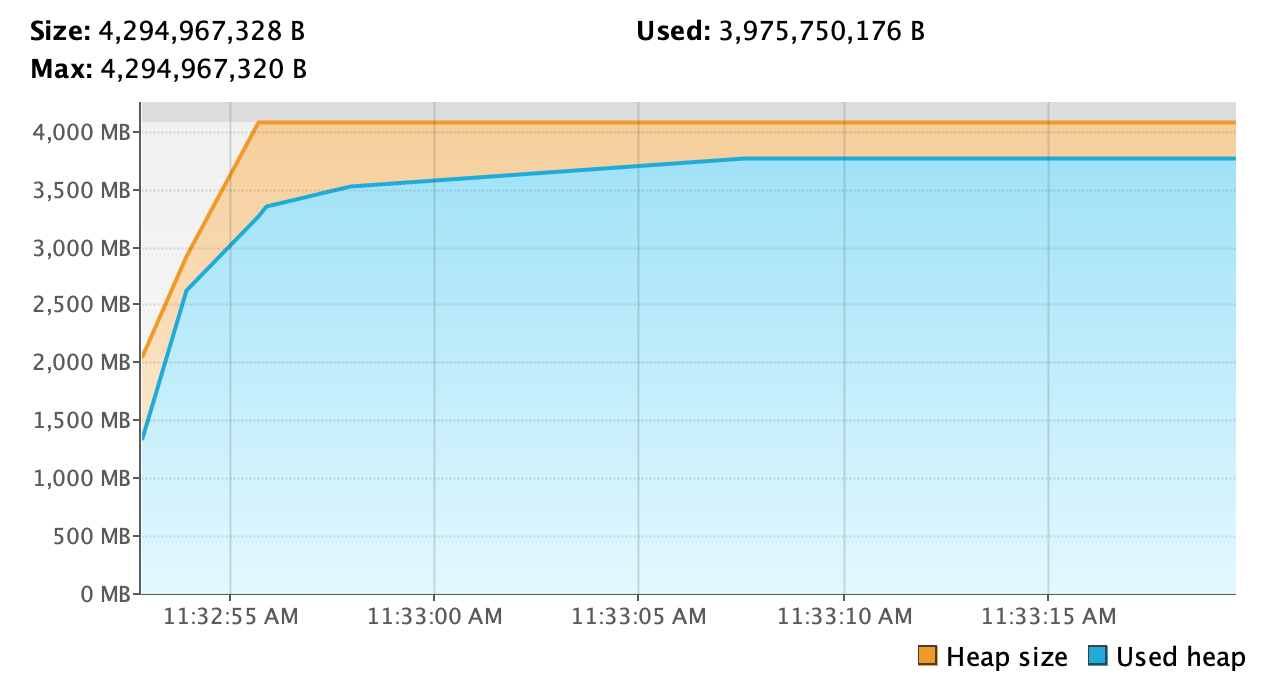
Les exemples présentés ci-dessus sont des cas relativement simples à détecter. Il est à noter que les fuites mémoires peuvent être plus difficiles à observer. De manière générale, si on arrive à extraire de la courbe de consommation mémoire une régression linéaire, affine ou logarithmique croissante, il y a de forte chance que celle-ci soit due à une fuite mémoire.
VisualVM
Les graphiques qui ont été présentés sont issus de VisualVM. Il s’agit d’un outil de visualisation permettant d’étudier le comportement d’une application Java pendant son exécution.
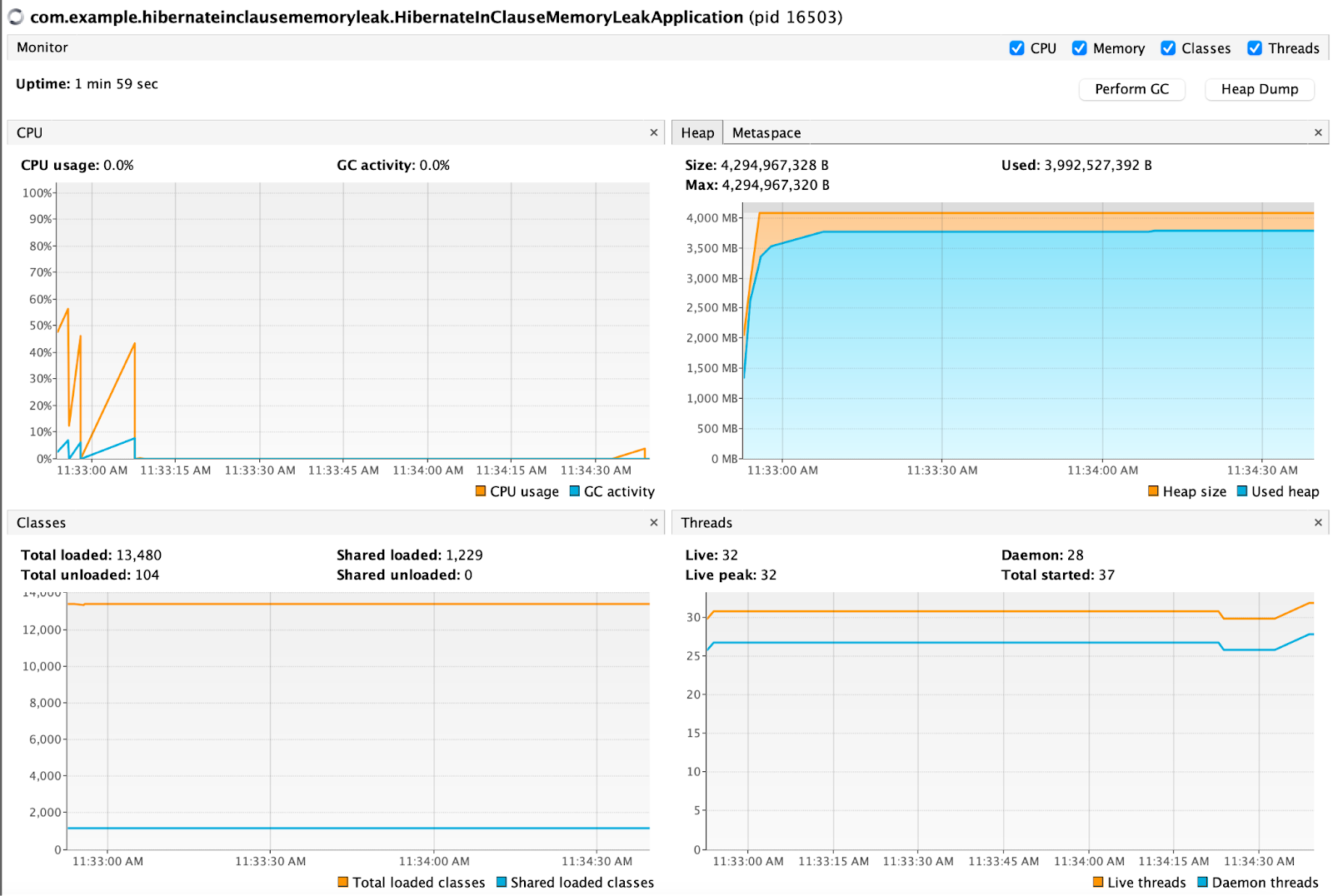
Il est notamment possible d’observer le comportement de la consommation processeur, mémoire ou encore des threads. Il existe aussi d’autres fonctionnalités plus pointues comme par exemple du profiling ou encore la visualisation de la mémoire générationnelle et les réclamations de l’espace mémoire du Garbage Collector avec Visual GC.
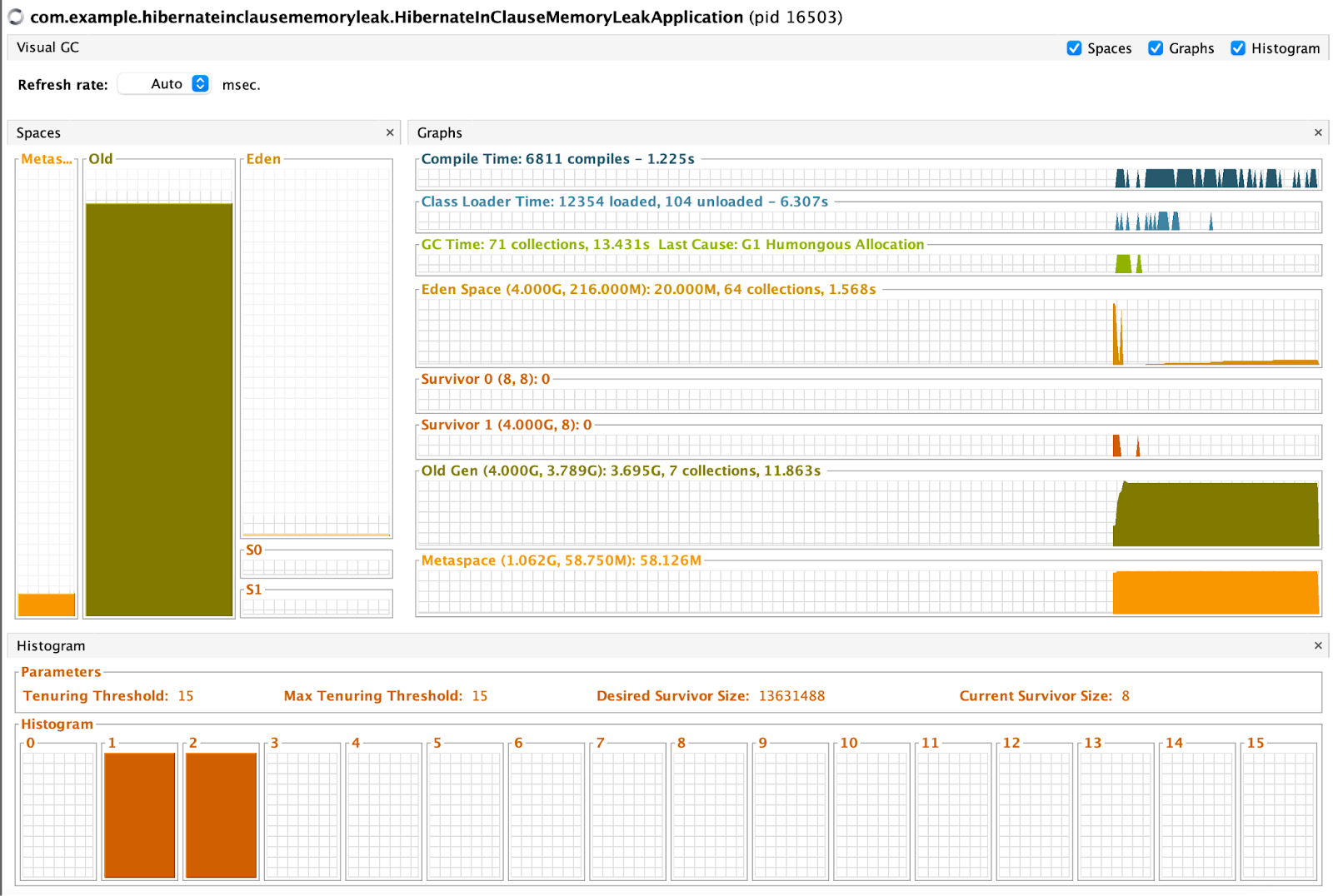
Récupérer les heap dumps
Détecter une fuite mémoire, c’est bien, mais trouver l’origine d’une fuite mémoire c’est mieux. Il est possible de récupérer des images (snapshot) de l’état mémoire de la JVM à un instant donné, cela nous permettrait d'explorer et d'analyser la composition de celle-ci. Ces snapshots sont appelés les heap dumps. Nous allons voir les différents moyens de les récupérer.
Spring Boot Actuator
Si vous avez une application Spring Boot, vous pouvez simplement utiliser Actuator pour récupérer les heap dumps. Il faut rajouter ces deux dépendances à votre projet :
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Il faut ajouter le starter web pour exposer Actuator au travers d’endpoint HTTP :
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>Une fois l’application lancée, vous pouvez simplement appeler l’url http://localhost:8080/actuator/heapdump pour télécharger le heap dump.
Ligne de commande
Jmap
Jmap est un utilitaire pour afficher des données relatives à la mémoire de la JVM. Il est également possible de récupérer des heap dumps en fournissant le PID de l’application via la commande suivante :
jmap -dump:live,format=b,file=/tmp/heapdump.hprof <pid>Option VM
Il est aussi possible de récupérer automatiquement un heap dump lorsque l’application s'arrête dû à un Out Of Memory, pour cela il faut rajouter dans les options de lancement de l’application :
-XX:+HeapDumpOnOutOfMemoryErrorPar contre, cela implique que vous devez pouvoir accéder à la machine sur laquelle la JVM s’exécute pour pouvoir récupérer le heap dump.
Via le code applicatif
Il n’est pas toujours possible d’avoir accès à l’instance sur laquelle s’exécute la JVM ou alors cela implique un travail important ou certaines limitations empêchent de récupérer les heap dumps. Par exemple, sur AWS, si vous exposez des services aux travers de l’API Gateway, il y a une limitation de taille à 10 MB pour les requêtes HTTP et un temps de connexion maximal à 30 secondes, ce qui rend l’utilisation d’Actuator pour récupérer les heap dumps assez complexes étant données que les heap dumps peuvent être volumineux.
Il est donc envisageable de créer une solution personnalisée pour stocker les heap dumps dans un endroit accessible. Suivant les possibilités qui peuvent s’offrir à vous, vous pouvez par exemple utiliser S3 ou une base de données.
La JVM expose l’interface HotSpotDiagnosticMXBean qui permet entre autres de créer un heap dump de manière programmatique. Vous pouvez donc créer le heap dump puis le récupérer et le stocker dans un espace accessible. Il faut faire attention à optimiser la lecture du heap dump pour ne pas charger toute la données en mémoire car celle-ci peut-être très volumineuse.
Voici un exemple de Controller Spring envoyant les heap dumps dans une base de données PostgreSQL :
@Slf4j
@RestController
@RequiredArgsConstructor
public class HeapDumpController {
private final JdbcTemplate jdbcTemplate;
private static final UUID id = UUID.randomUUID();
@PostMapping("/memoryDump")
public ResponseEntity<Void> createHeapDump() throws IOException {
InputStream inputStream = null;
File dumpFile = null;
File dumpFileGzip = null;
try {
HotSpotDiagnosticMXBean diagnosticMXBean = ManagementFactory.getPlatformMXBeans(HotSpotDiagnosticMXBean.class).stream().findFirst().get();
String prefix = String.format("heapdump-%d", System.currentTimeMillis());
dumpFile = File.createTempFile(prefix, ".hprof");
dumpFile.delete();
log.info(String.format("Dumping file to %s", dumpFile.getAbsolutePath()));
diagnosticMXBean.dumpHeap(dumpFile.getAbsolutePath(), true);
dumpFileGzip = File.createTempFile(prefix, ".hprof.gz");
compressGzipFile(dumpFile, dumpFileGzip);
inputStream = new FileInputStream(dumpFileGzip);
InputStream finalInputStream = inputStream;
jdbcTemplate.update("INSERT INTO public.heapdump (uid, \"timestamp\", dump_binary) VALUES (?,?,?)", preparedStatement -> {
preparedStatement.setString(1, id.toString());
preparedStatement.setTimestamp(2, Timestamp.from(ZonedDateTime.now().toInstant()));
preparedStatement.setBinaryStream(3, finalInputStream);
});
log.info("Heap dumped in database");
} catch (Exception e) {
e.printStackTrace();
} finally {
inputStream.close();
dumpFile.delete();
dumpFileGzip.delete();
}
return ResponseEntity.ok().build();
}
public static void compressGzipFile(File sourceFile, File compressedFile) throws IOException {
FileInputStream fis = new FileInputStream(sourceFile);
FileOutputStream fos = new FileOutputStream(compressedFile);
GZIPOutputStream gzipOS = new GZIPOutputStream(fos);
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = fis.read(buffer)) != -1) {
gzipOS.write(buffer, 0, bytesRead);
}
gzipOS.close();
fos.close();
fis.close();
}
}Il est à noter que l’utilisation de GZip permet de stocker tout en minimisant la taille de la donnée car le type bytea de PostgreSQL ne peut contenir des données que jusqu’à 1 Gb. Si le heap dump dépasse la limitation, il faut alors trouver une autre solution de stockage ou alors utiliser les Large Objects de PostgreSQL.
Il est fortement déconseillé d’utiliser ce moyen en production mais cela reste acceptable si vous ne déployez uniquement que dans des environnements de tests où vous arrivez à reproduire la fuite mémoire.
Eclipse Memory Analyzer (MAT)
Eclipse Memory Analyzer est un outil Open Source proposant un panel de fonctionnalités qui a pour but d’aider les développeurs dans l’analyse des heap dumps. Il permet donc la recherche de fuite mémoire, de localiser l’utilisation inefficace de la mémoire ou tout autre problème lié à la mémoire en général.
Dans la suite de cet article, nous allons prendre en exemple le projet hibernate-in-clause-memory-leak dont j’ai récupéré le heap dump après 20 appels à la méthode getBooksById du repository BookRepository (avec en paramètre une collection de taille variables d'ids à chaque appel) :
@Query("""
SELECT b
FROM Book b
WHERE b.id in :ids
""")
Collection<Book> getBooksById(Collection<Integer> ids);Lançons Eclipse MAT et ouvrons le heap dump avec le mode Leak Suspects Report :
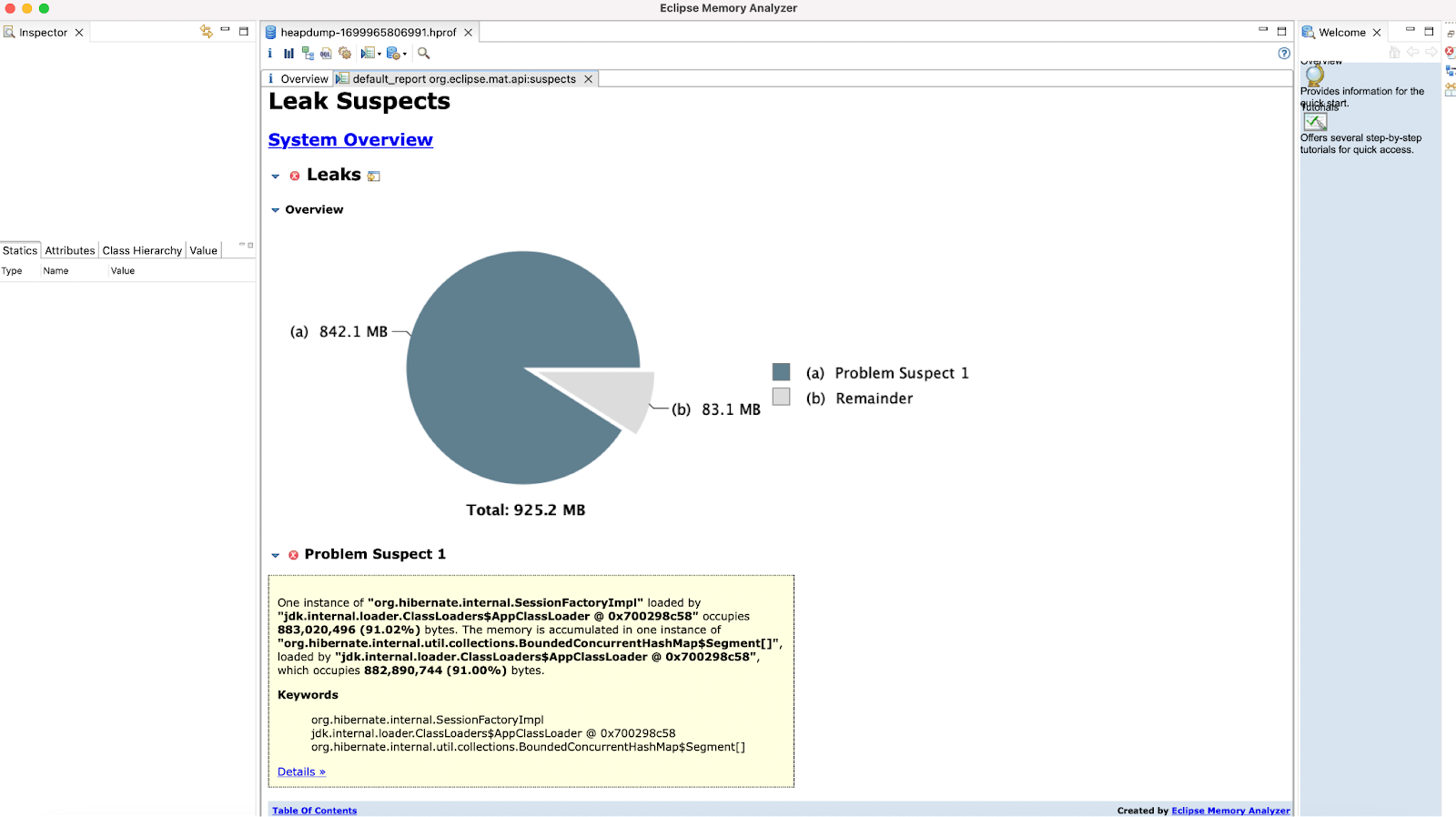
Ce mode est une fonctionnalité très pratique permettant de faire une première passe sur les potentiels suspects de la fuite mémoire. On peut voir ici que 91% de la mémoire est utilisée par org.hibernate.internal.SessionFactoryImpl et plus précisément dans une instance de org.hibernate.internal.util.collections.BoundedConcurrentHashMap$Segment[]. Ce qui nous oriente déjà vers un problème lié à l’utilisation d’Hibernate.
Si nous voulons aller plus loin dans l’analyse, il faut explorer l’état de la mémoire pour trouver l’origine de cette consommation excessive. Pour nous aider, nous pouvons explorer la mémoire sous la forme d’un dominator tree.
Un dominator tree est un arbre obtenu à partir d’un graphe (ici le graphe des objets en mémoire) où un objet x domine un objet y si tous les chemins partant de la racine du graphe doivent passer par x pour atteindre y.
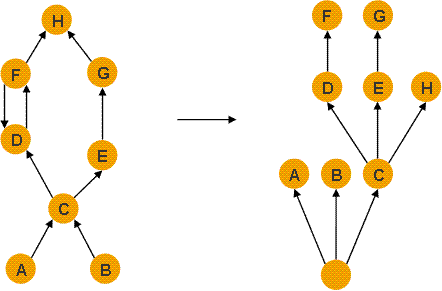
L’utilisation d’un tel arbre nous permet ensuite d’identifier facilement les grappes d’objets consommant le plus de mémoire et les dépendances des objets responsables des maintiens de références des autres objets dans la mémoire.
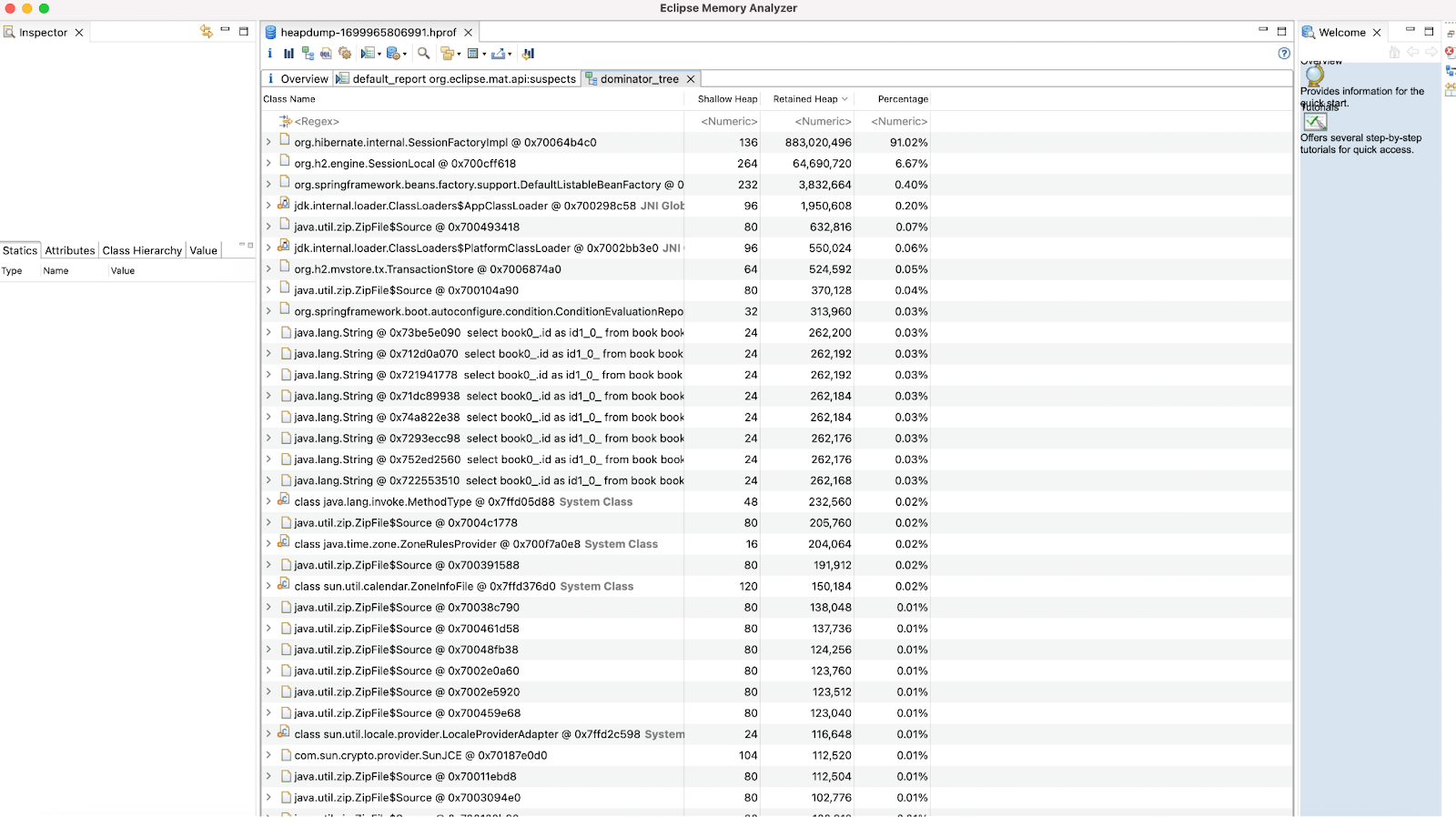
En explorant ce dominator tree et plus précisément l’objet SessionFactoryImpl, on peut observer qu’une très large partie de la mémoire est occupée par le queryPlanCache.
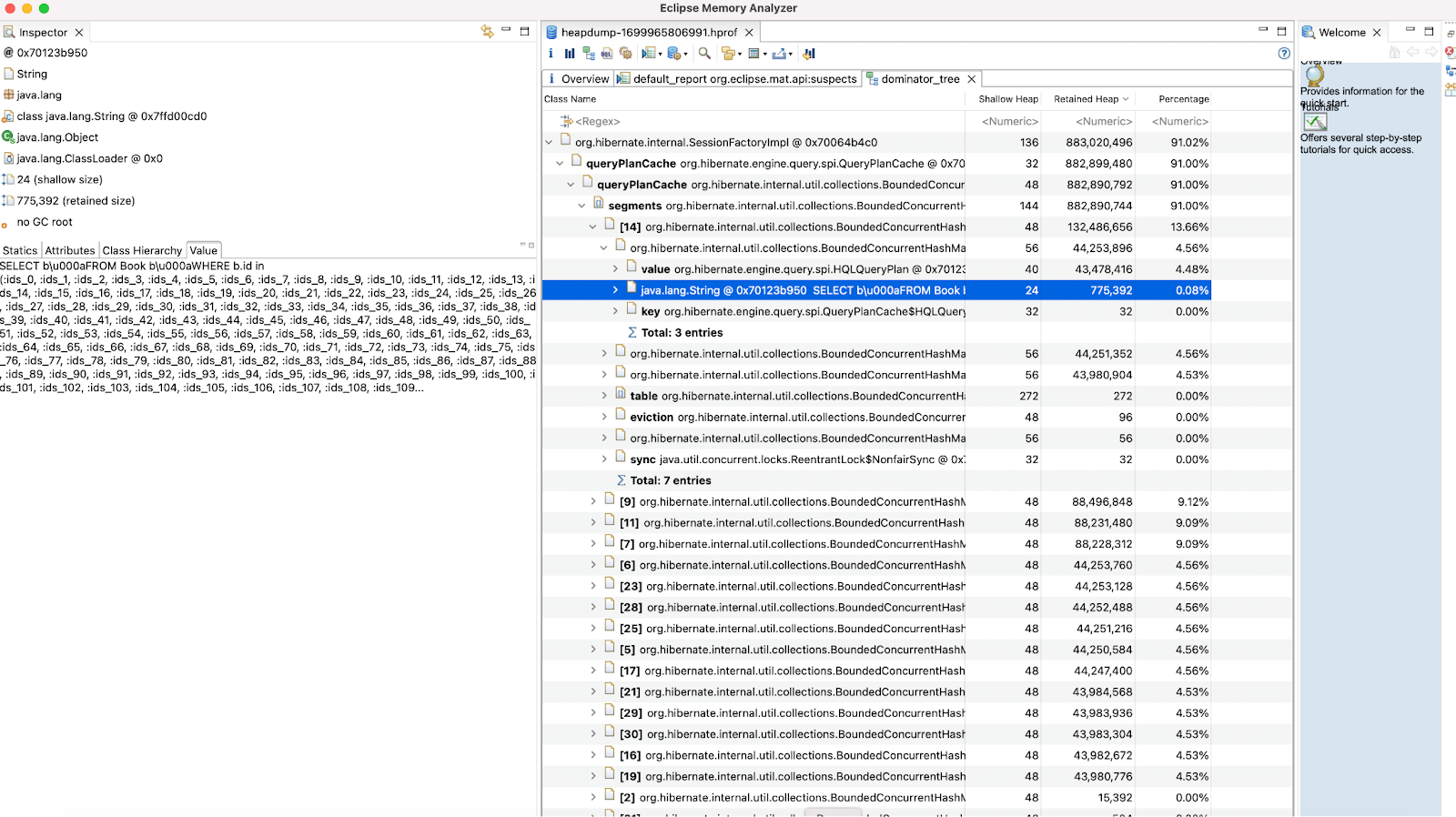
Il est intéressant de noter que la majorité du cache est composé d’entrées dupliquées pour la requête SQL suivante :
SELECT b FROM Book b WHERE b.id in (:ids_0, :ids_1, :ids_2, :ids_3, :ids_4,
:ids_5, :ids_6, :ids_7, :ids_8, :ids_9, :ids_10, :ids_11, :ids_12, :ids_13,
:ids_14, :ids_15, :ids_16, :ids_17, :ids_18, :ids_19, :ids_20, :ids_21,
:ids_22, :ids_23, :ids_24, :ids_25, :ids_26, :ids_27, :ids_28, :ids_29,
:ids_30, :ids_31, :ids_32, :ids_33, :ids_34, :ids_35, :ids_36, :ids_37,
:ids_38, :ids_39, :ids_40, :ids_41, :ids_42, :ids_43, :ids_44, :ids_45,
:ids_46, :ids_47, :ids_48, :ids_49, :ids_50, :ids_51, :ids_52, :ids_53,
:ids_54, :ids_55, :ids_56, :ids_57, :ids_58, :ids_59, :ids_60, :ids_61,
:ids_62, :ids_63, :ids_64, :ids_65, :ids_66, :ids_67, :ids_68, :ids_69,
:ids_70, :ids_71, :ids_72, :ids_73, :ids_74, :ids_75, :ids_76, :ids_77,
:ids_78, :ids_79, :ids_80, :ids_81, :ids_82, :ids_83, :ids_84, :ids_85,
:ids_86, :ids_87, :ids_88, :ids_89, :ids_90, :ids_91, :ids_92, :ids_93,
:ids_94, :ids_95, :ids_96, :ids_97, :ids_98, :ids_99, :ids_100, :ids_101,
:ids_102, :ids_103, :ids_104, :ids_105, :ids_106, :ids_107, :ids_108,
:ids_109...Une telle consommation du cache est anormalement élevée et semble à l’origine du problème de mémoire sur l’application. En effet, pour seulement 20 appels, le cache consomme environ 880 Mb, ce qui est énorme !
Eclipse MAT est une solution très complète et propose d’autres fonctionnalités tel que la comparaison de heap dumps. Cela permet de comparer la différence de l’état de la mémoire entre deux dates et donc dans notre cas de voir l’augmentation de l’utilisation de la mémoire dû au queryPlanCache qui continue de grandir.
Hibernate et la clause IN
Nous avons découvert l’origine de la fuite mémoire mais il nous faut encore expliquer pourquoi les entrées du cache sont dupliquées avec pourtant ce qui semble être la même requête SQL.
Pour comprendre ce qui se passe, il faut déjà comprendre comment fonctionne cette partie.
Avec Hibernate, chaque requête JPQL ou Criteria produit un arbre de syntaxe abstrait (AST) avant de générer une requête SQL qui va ensuite être exécutée en base de données. Cette compilation de requête à un certain coût en ressource et c’est pour cela qu’il est mis en cache dans le queryPlanCache.
Cependant dans le cas d’une requête JPQL impliquant la clause IN, chaque requête va générer une nouvelle entrée dans le cache si le nombre de paramètres est différent. Par exemple, si j'exécute ces 2 appels :
bookRepository.getBooksById(List.of(1, 2, 3));
bookRepository.getBooksById(List.of(1, 2, 3, 4));Il y aura deux entrées distinctes dans le queryPlanCache car cela génère respectivement ces deux requêtes SQL différentes :
SELECT b FROM Book b WHERE b.id in (:ids_0, :ids_1, :ids_2)et
SELECT b FROM Book b WHERE b.id in (:ids_0, :ids_1, :ids_2, :ids_3)Plusieurs solutions existent pour régler ce problème de duplication, mais la plus pertinente serait d’utiliser l’option in_clause_parameter_padding. Cette solution a aussi l’avantage d’être simple à mettre en place, il suffit de rajouter dans la configuration Hibernate :
spring.jpa.hibernate.query.in_clause_parameter_padding=trueCette configuration va permettre dans le cas des requêtes incluant la clause IN de générer 2n paramètres et lors de l’exécution de cette requête les emplacements en “trop” sont remplis par la dernière valeur.
Par exemple :
bookRepository.getBooksById(List.of(1, 2, 3, 4, 5));Produira la requête suivante (23):
SELECT * FROM Book b WHERE b.id in (1, 2, 3, 4, 5, 5, 5, 5);Cependant, il faut faire attention aux limitations du pilote JDBC qui est utilisé. En effet, suivant le pilote, il peut y avoir une limite du nombre de paramètres prit en charge.
S’il existe une limite n, il faut faire attention à ne jamais dépasser 2^(log(n)-1)-1 d’arguments dans la clause IN sinon cela génère une requête dont le nombre de paramètres dépasse la taille autorisé par le pilote.
Ce problème peut être mis en évidence avec Hibernate 5 mais avec Hibernate 6, l'implémentation de la gestion du cache semble avoir été retravaillée et optimisée pour éviter de tels soucis.
Conclusion
Nous avons vu comment rechercher et remonter à l’origine d’une fuite mémoire. La réelle difficulté n’est donc pas forcément de l’identifier mais plutôt de pouvoir récupérer les données et les exploiter efficacement. Cela montre aussi à quel point il est important que les développeurs connaissent et maîtrisent à minima les divers frameworks et librairies qu’ils exploitent.








{kind=link}