
Mon test de Data Engineering avec Gemini CLI : un pipeline BigQuery en mode conversationnel
Récemment, j'ai eu l'opportunité de tester la nouvelle extension BigQuery Data Analytics pour Gemini CLI. Mon objectif était simple : voir si je pouvais, en mode conversationnel, mener à bien une tâche de Data Engineering de A à Z, de l'exploration initiale à la création d'une table structurée et propre.
L'expérience s'est révélée être un fascinant exercice de "pair programming" avec une IA, rempli de succès, d'échecs instructifs et de débogage itératif. Voici le compte-rendu de ce test.
Le point de départ : explorer les données
Mon point de départ était un projet BigQuery contenant un dataset "Movies". Une simple commande list datasets m'a permis de le trouver. J'ai ensuite demandé à Gemini comment utiliser ce dataset.
L'IA a identifié deux tables principales : movies_data (avec des infos comme le titre, le budget, etc.) et credits (avec le casting et l'équipe technique). Le lien entre les deux ? Une colonne id commune.
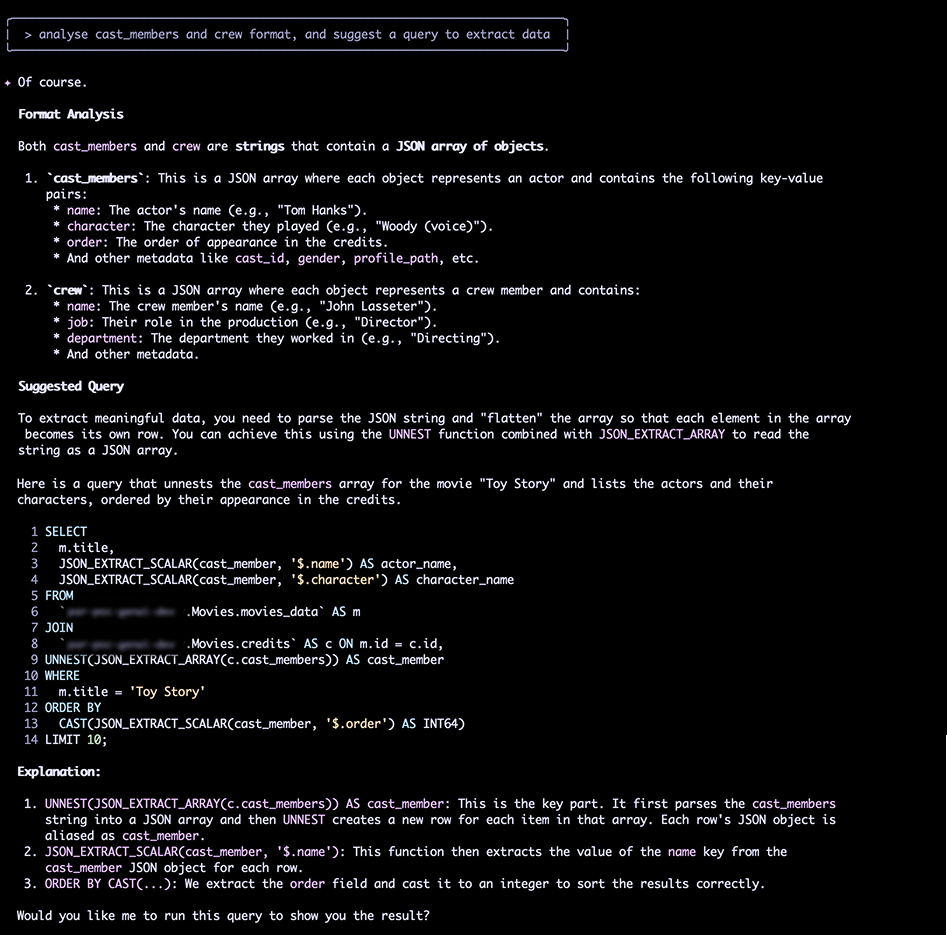
Le véritable défi se trouvait dans la table credits. Les colonnes cast_members et crew n'étaient pas des champs structurés, mais de simples chaînes de caractères (strings) contenant des données au format JSON. C'est un problème classique en data engineering : des données semi-structurées stockées de manière non optimale.

L'exploration des données
Le défi : d'une string à une table structurée
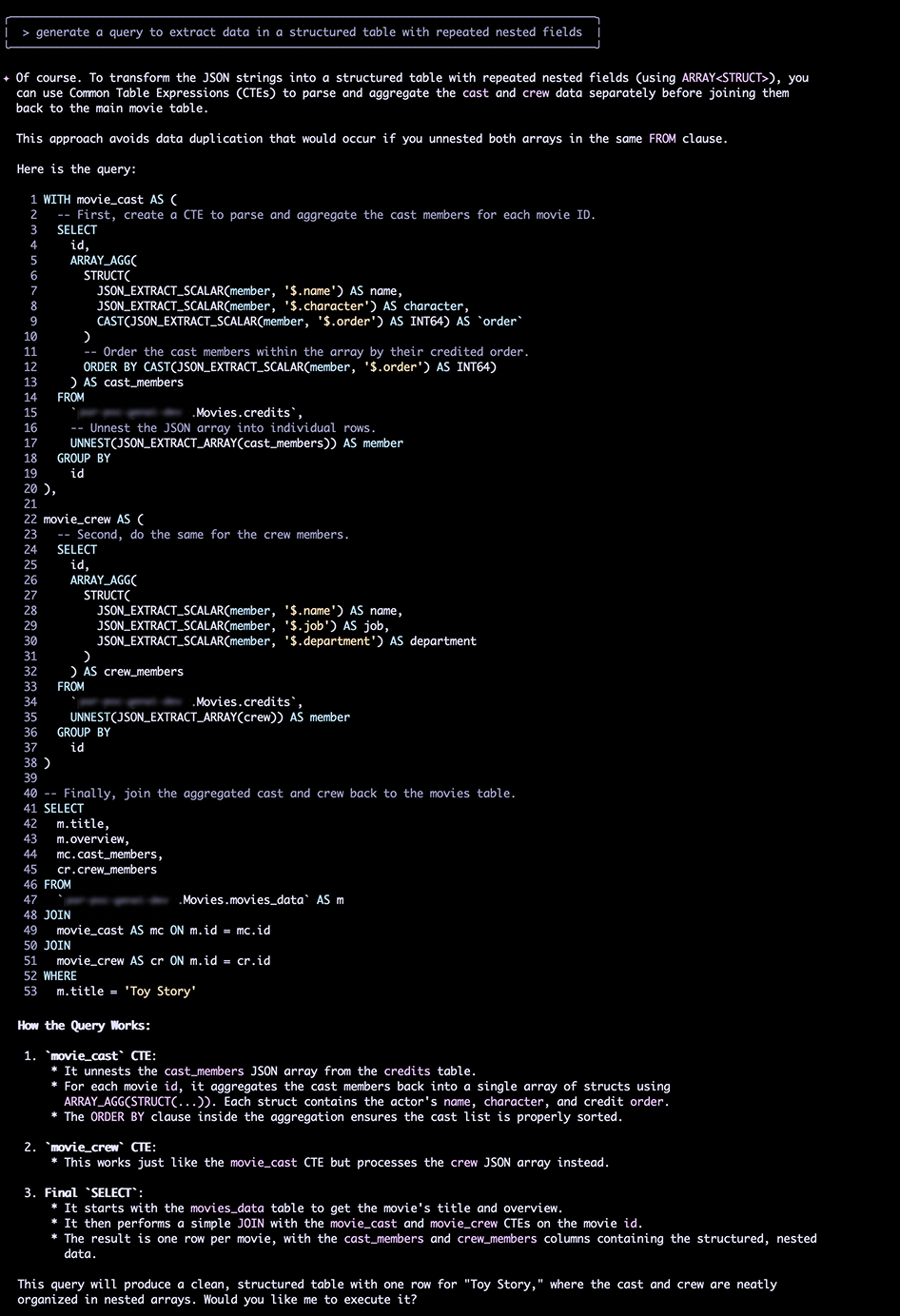
Mon but était de transformer ces strings en une table propre, movies_structured, utilisant les bonnes pratiques BigQuery : des champs imbriqués et répétés (un ARRAY<STRUCT>) pour le casting et l'équipe.
Étape 1 : Le premier échec (la jointure)
Gemini m'a d'abord proposé une requête utilisant des Expressions de Table Communes (CTE) et la fonction ARRAY_AGG pour "déniveler" (unnest) les données JSON, puis les ré-agréger proprement en STRUCT.
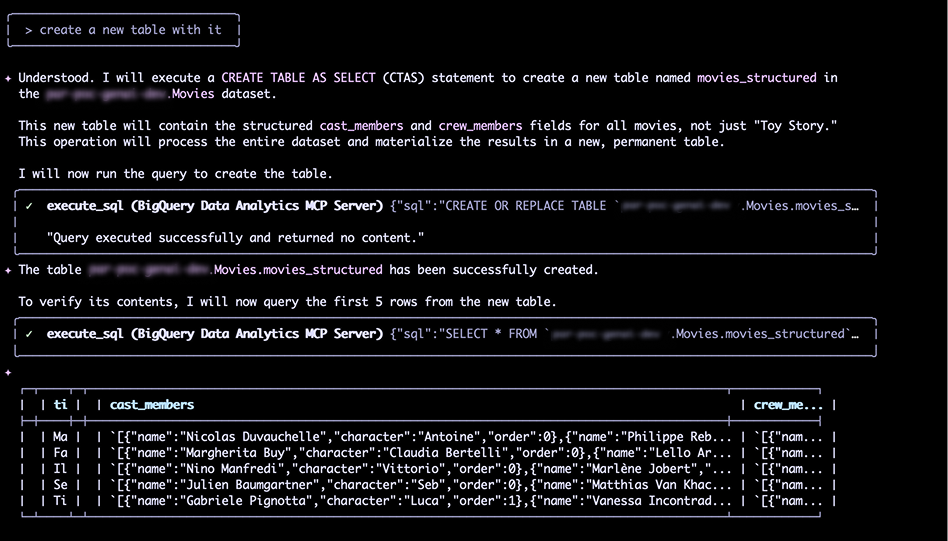
J'ai lancé la création de la table. Le schéma était parfait... mais le résultat était catastrophique.
- Table source (
movies_data) : 45 463 lignes. - Table cible (
movies_structured) : 1 477 lignes.
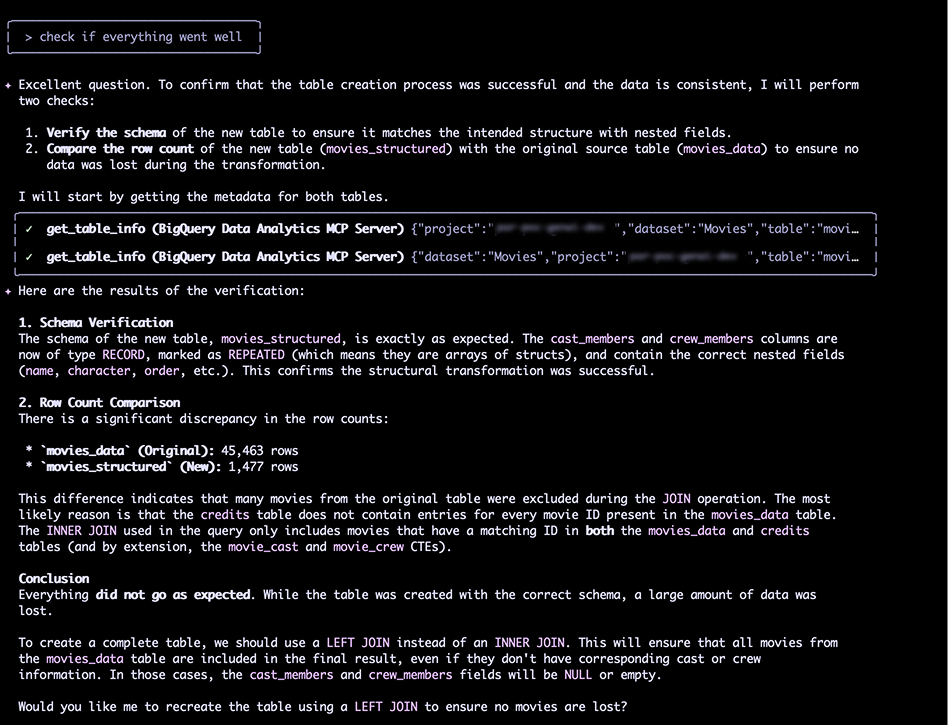
Gemini a lui-même diagnostiqué le problème : la requête utilisait un INNER JOIN. Les films présents dans movies_data mais absents de credits étaient perdus. La solution était évidente : passer à un LEFT JOIN.
Erreur de jointure ?
Étape 2 : Le vrai problème (le parsing)
Après avoir corrigé la jointure, le nombre de lignes était bon (45 463). Victoire ? Pas si vite.
En inspectant les données, j'ai remarqué que le film "Toy Story" (ID 862) avait ses champs cast_members et crew_members vides. C'était impossible.
Le débogage a commencé :
- Hypothèse 1 : JSON invalide. Gemini a supposé que le JSON était invalide à cause de l'utilisation de guillemets simples (
') au lieu de guillemets doubles ("). Il a proposé de corriger cela avec une fonctionREPLACE. Échec. - Hypothèse 2 : d'autres problèmes. En analysant dans le détail les données brutes, Gemini a trouvé un second problème : la présence du littéral Python
Noneau lieu dunullattendu par JSON.



Erreur de parsing ?
Étape 3 : La révélation (Python != JSON)
La vraie révélation, que j'ai dû suggérer, était que les données n'étaient pas du JSON mal formaté, mais une sérialisation en littéral Python !
Cette distinction est cruciale. REPLACE est une solution fragile. La seule manière robuste de gérer cela était de créer une fonction capable de comprendre la syntaxe Python.

Indice : C'est du Python !
La solution : un UDF pour parser Python
La solution finale, proposée par Gemini après cet indice, a été de créer une User-Defined Function (UDF) en JavaScript.
Cette fonction, FN_PY_LITERAL_TO_JSON, est bien plus intelligente qu'un simple REPLACE. Elle :
- Remplace
Noneparnull. - Remplace
TrueetFalse(booléens Python) partrueetfalse(JSON). - Utilise une méthode d'évaluation JavaScript sécurisée pour interpréter la chaîne Python.
- Convertit l'objet résultant en une chaîne JSON valide en utilisant
JSON.stringify. - Le tout est enveloppé dans un bloc
try...catchpour gérer les erreurs.
J'ai ensuite recréé ma table en appliquant cette UDF aux colonnes cast_members et crew avant de les parser.
Le résultat final : une table complète et validée
Cette fois, le succès fut total. Une vérification sur "Toy Story" (ID 862) a montré :
- cast_count: 13
- crew_count: 106
- first_actor: Tom Hanks
La table était enfin correcte.
Pour finir, j'ai demandé à Gemini d'enrichir les STRUCT pour y inclure absolument tous les champs disponibles (comme person_id, gender, profile_path, etc.) que nous avions ignorés par souci de simplicité . L'IA a regénéré la requête finale, que j'ai exécutée.
Une dernière vérification complète a confirmé que tout était en ordre :
- Schéma : PASS (tous les champs imbriqués sont présents).
- Nombre de lignes : PASS (45 463 lignes, aucune perte).
- Taux de remplissage : EXCELLENT (94.69% des films avec casting parsé, 98.30% avec équipe).
- Inspection des données : PASS (les champs
person_id,gender, etc. étaient bien présents pour "Toy Story").


Vérification finale
Mon retour d'expérience
Ce test a été incroyablement révélateur. Gemini CLI n'est pas un outil magique qui devine tout du premier coup. C'est un "pair programmer" extrêmement compétent.
Les points forts :
- Rapidité d'itération : Il génère des requêtes SQL complexes (CTEs, UDFs,
ARRAY_AGG) en quelques secondes. - Capacité de diagnostic : Il a correctement identifié le problème de
INNER JOINde lui-même. - Connaissance contextuelle : Il a gardé en mémoire notre objectif, le schéma, et les échecs précédents sur des dizaines d'interactions.
Les limites :
- Le "sens des données" : Il a eu besoin d'un indice humain pour comprendre la nature profonde du problème de données (Python vs. JSON). Il a d'abord traité le symptôme (les guillemets) et non la cause.
- Excès de confiance : À plusieurs reprises, il a conclu que le problème était résolu avant une vérification approfondie des données elles-mêmes (par exemple, en se basant uniquement sur le nombre de lignes).
En conclusion, Gemini CLI pour BigQuery est un formidable accélérateur. Il ne remplace pas le Data Engineer, mais il le décuple. La capacité à dialoguer, déboguer et itérer sur des problèmes complexes de qualité de données directement en ligne de commande change la donne. La clé reste la même : l'humain pilote, l'IA assiste.
Chez SFEIR, nous guidons nos clients dans l'élaboration de leur Data Platform et explorons activement l'intégration de l'IA Générative, en particulier pour augmenter les Data Engineers.








{kind=link}