
Constat : l’ingestion est un point de douleur
Que ce soit financièrement ou techniquement, dlt (Data Load Tool) répond à plusieurs problématiques majeures :
- Complexité des pipelines : Écriture de « glue-code » ELT fastidieux, dispersé dans les DAGs, ou pire, dans des ELT graphiques non migrables.
- Évolutivité du schéma : Gestion de l’ajout de colonnes, de listes imbriquées ou de formats semi-structurés qui cassent régulièrement les pipelines.
- Portabilité de l'exécution : Adaptation du code lors du passage d’un notebook de R&D à Airflow ou à une fonction Lambda.
- Flexibilité du code : Tout est en Python, modifiable et adaptable à vos scénarios.
- Réduction significative des coûts : L’ingestion représente souvent un poste budgétaire important dans la stack data.
- Faible consommation et rapidité d’ingestion : Consommation mémoire/CPU réduite, permettant l’intégration de petits pipelines dans des lambdas ou notebooks.
dlt en un coup d’œil
dlt (Data Load Tool) est une librairie Python (Apache 2.0) à importer dans vos scripts, sans plateforme à maintenir. Son approche code-first permet :
- Contrôle total : Versionnable et testable en Python.
- Courbe d’apprentissage linéaire : Concepts simples (@dlt.resource, pipeline.run).
- Portabilité immédiate : local ➜ orchestrateur ➜ serverless, sans serveur propriétaire
ℹ️ Chiffres clés
- 60+ connecteurs « verified »
- ~3,900 ⭐ sur GitHub
- Jusqu'à 6× les performances d'Airbyte sur des flux SQL massifs
Architecture Extract → Normalize → Load
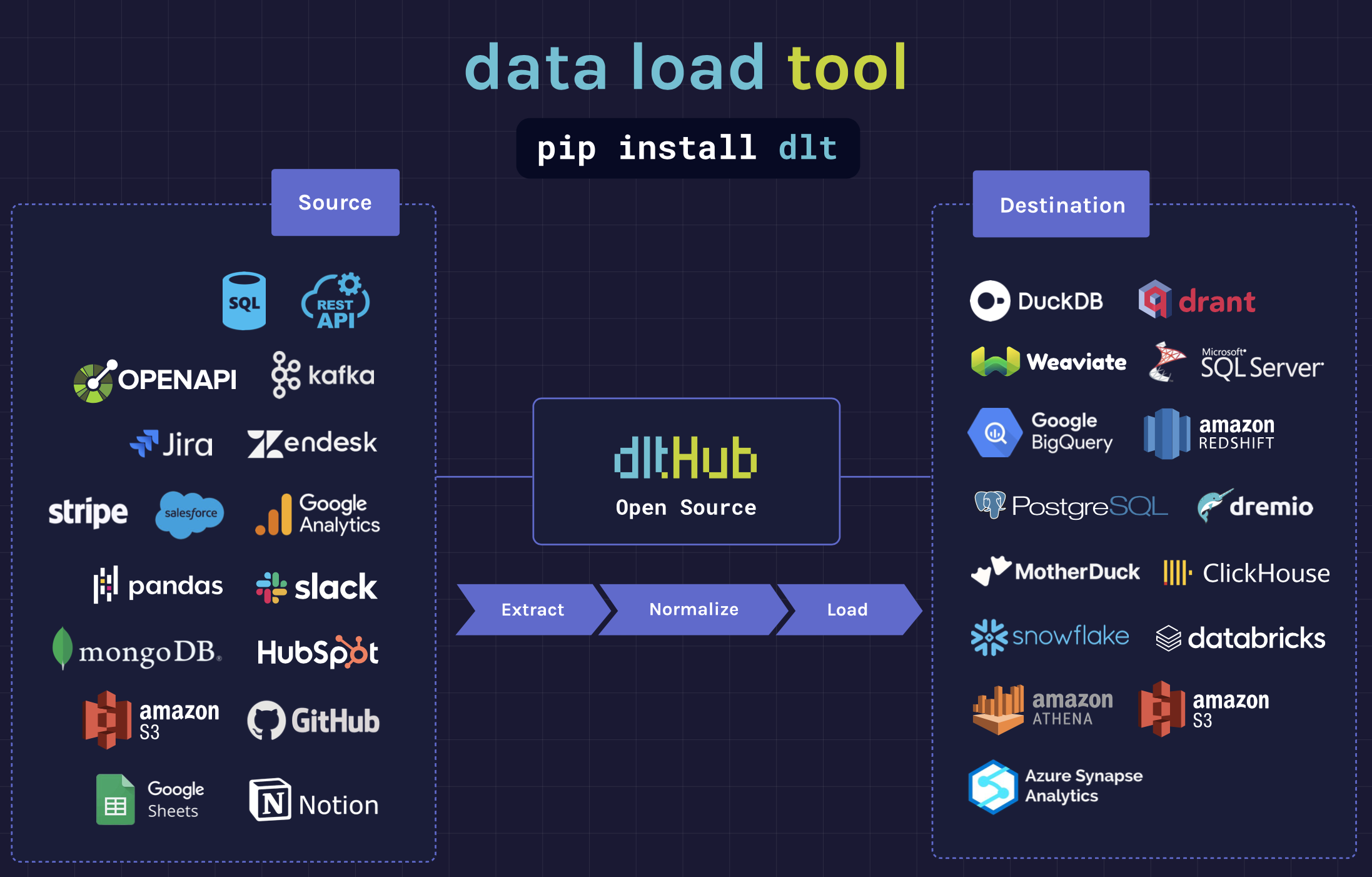
Vue d'ensemble
- Extract : chaque resource émet un flux d'objets Python. dlt sérialise ces lignes dans un load package (parquet, jsonl…) sur disque pour fiabiliser la suite.
- Normalize : l'algorithme Schema Discovery parcourt les paquets, infère les types, unnest les champs nested (👉 parent__child), génère un plan SQL cible et – si nécessaire – crée les tables enfant.
- Load : dlt applique le plan sur la destination, crée ou migre le schéma, puis ingère en parallèle (chunk de 100k lignes par thread par défaut, configurable).
Persistance de l’état
~/.dlt/pipelines/<pipeline_name>/
├── schema.json # définition du schéma (versionnée)
├── state.json # curseurs incrémentaux & dernier load_id
└── load_packages/
└── <timestamp>/ # données intermédiaires compresséesContenu du pipeline
Prise en main
⚠️ Préambule :
- Utilisez un environnement virtuel pour éviter les conflits de dépendances (venv, poetry, conda, etc.)
- Vérifiez votre version de Python. Si vous prévoyez d'utiliser ConnectorX (le connecteur SQL ultra-performant basé sur Rust), vérifiez sa compatibilité sur ConnectorX PyPI
Installation
pip install "dlt[duckdb]"
# ou pour Oracle vers Databricks : dlt[sql-database,databricks]
Initialisation de dlt
Génération du squelette de pipeline
dlt init rest duckdb simpsons_quickstartcréation des fichiers d'exemple et config
- Crée les fichiers d’exemple, installe les dépendances, crée le dossier du projet.
Structure du projet
simpsons_quickstart/
├── .dlt/
│ ├── config.toml # configurations non sensibles
│ └── secrets.toml # clés (API, DB…)
├── pipeline.py # script Python auto-généré
├── requirements.txt # versions figées
└── README.md # rappel des commandes utilesContenu du projet
ℹ️ le fichier config.toml contient les valeurs par défaut (log-level, dataset name, etc.). Les secrets (secrets.toml) sont ignorés par Git (.gitignore) pour éviter toute fuite de credentials.
Exécution du pipeline de démonstration
cd simpsons_quickstart
python pipeline.py # charge les données vers DuckDB
lancement du pipeline
Premier pipeline : « Hello DuckDB »
Dans ce premier pipeline, nous allons générer une table "characters" dans DuckDB.
import dlt, pandas as pd
DATA = pd.DataFrame({
"id": [1, 2, 3],
"name": ["Lisa", "Bart", "Maggie"],
"age": [8, 10, 1],
})
pipe = dlt.pipeline(
pipeline_name="simpsons_quickstart",
destination="duckdb", # postgres | bigquery | snowflake …
dataset_name="simpsons_ds",
)
pipe.run(DATA.to_dict("records"), table_name="characters")
print(pipe.last_trace.load_packages[0].jobs_summary())
premier pipeline de A à Z
Ce qu'il se passe
- dlt crée un load package
characters_20250711T1800…sur disque - Le Normalizer détecte les colonnes
id:int,name:str,age:int - La phase Load crée le fichier
simpsons_quickstart.duckdbpuis la tablecharacters - La trace est stockée dans
~/.dlt/pipelines/simpsons_quickstart/
Si le traitement échoue après plusieurs étapes, vous pourrez corriger et reprendre là où vous en étiez. Ce qui est particulièrement pratique lorsque vous avez des milliards de lignes.
Interrogation immédiate
>>> pipe.dataset().characters.df().head()
id name age
0 1 Lisa 8
1 2 Bart 10
2 3 Maggie 1requête des données
Aussi simple que ça !
Aller plus loin avec DuckDB
dlt s’intègre naturellement avec DuckDB, ce qui en fait une solution idéale pour :
- Prototypage rapide : pipelines en local ou dans des notebooks, sans serveur
- Tests unitaires : validez vos transformations avant de cibler un warehouse cloud
- Migration : passez de DuckDB à BigQuery, Snowflake, etc. sans changer votre code, simplement en modifiant la destination
Exemple
Pour migrer un pipeline de DuckDB à Snowflake :
dlt pipeline simpsons_quickstart --destination snowflake --dataset simpsons_raw --credentials ~/.creds/snowflake.tomldlt reconstruit le schéma et migre si nécessaire
Approche « ad-hoc » vs décorateurs @dlt.resource
dlt permet deux styles d'utilisation :
- Ad-hoc :
pipeline.run(data)(minimal, rapide) - Décorateurs :
@dlt.resource,@dlt.source(plus verbeux, mais puissants et réutilisables)
Comparatif
| Critère | pipeline.run(iterable) | @dlt.resource / @dlt.source |
|---|---|---|
| Boilerplate | Minimal (1 ligne) | Plus verbeux |
| Ré-utilisable | ❌ | ✅ |
| Incrémental / merge | Logique manuelle | ✔︎ (incremental(), write_disposition) |
| Pagination / Auth | Manuel | Helpers REST auto |
| Contrats de schéma | Global seulement | Par resource / table |
| Observabilité | Stats par table | Stats par resource |
Exemple ad-hoc
pipe.run([{"id": 1, "name": "John"}], table_name="users")
lancement simple
Exemple modulaire avec décorateurs :
@dlt.resource(write_disposition={"disposition": "merge", "strategy": "scd2"})
def users():
yield {"id": 1, "name": "John"}
pipe.run(users())lancement industrialisable
Sources, Resources & Transformers
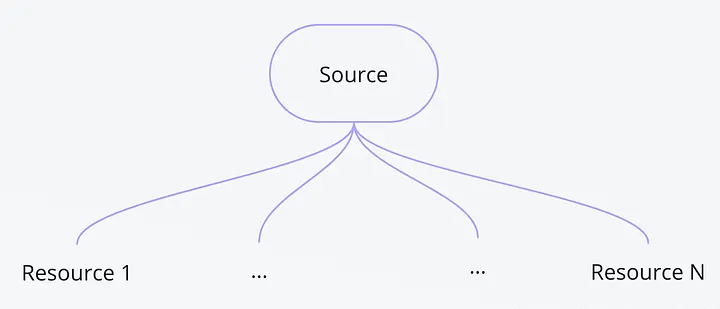
- Une Source dans dlt est une localisation qui détient des données avec une certaine structure, organisée en une ou plusieurs resources. Elle peut être une base de données, une API, etc. Elle expose des paramètres configurables globaux.
- Une Resource est un regroupement logique de données au sein d'une source de données. Par exemple, les tables d'une base de données ou les routes d'une API. Chaque resource peut être surchargée avec ses propres paramètres.
- Un Transformer peut prendre en entrée des données brutes ou intermédiaires et produire des données modifiées ou enrichies. Par exemple, dans notre cas ci-dessous, le transformer
anonymize_emailanonymisera les emails. Avec l'option@dlt.defer, un transformer peut exécuter ses opérations en parallèle pour améliorer la performance.
Prenons un cas d’usage concret : ingestion de données d’utilisateurs et de leurs commandes depuis une API, avec anonymisation des emails.
Exemple source
@dlt.source(name="shop_api")
def shop_api_source(api_token: str = dlt.secrets.value, country: str = "FR"):
# On passe le paramètre country à chaque resource si besoin
return [
users(api_token=api_token),
orders(api_token=api_token)
]ici on configure la source des données (Une api, un DB etc...)
Exemple resource
@dlt.resource(table_name="users", write_disposition="merge")
def users(api_token: str = dlt.secrets.value):
# Appel à une API pour récupérer les utilisateurs
for user in fetch_users_from_api(api_token):
yield user
@dlt.resource(table_name="orders", write_disposition="append")
def orders(api_token: str = dlt.secrets.value):
# Appel à une API pour récupérer les commandes
for order in fetch_orders_from_api(api_token):
yield orderici on peut paramétrer chaque resource indépendamment de l'autre.
Exemple transformer
@dlt.transformer()
def anonymize_email(row: dict):
if "email" in row:
row["email"] = "***anonymized***"
return rowanonymisation des emails
Exécution du pipeline avec source et transformer
pipeline.run(
shop_api_source(api_token="my-token").add_transformer(anonymize_email)
)exemple avec un transformer
Dans cet exemple
- La source
shop_api_sourceorchestre les resourcesusersetorderset permet de paramétrer l’API token (et potentiellement d’autres paramètres comme le pays). - Les resources extraient les données brutes depuis l’API.
- Le transformer anonymise les emails à la volée avant le chargement.
- Le pipeline exécute l’ensemble, de façon modulaire et réutilisable.
Authentification et gestion des secrets
dlt simplifie la gestion sécurisée des secrets et des identifiants d’API grâce à un système de résolution en couches, pensé pour s’adapter à tous les environnements (local, cloud, CI/CD). Lorsqu’un pipeline a besoin d’un secret (par exemple un token d’authentification), dlt va automatiquement le rechercher selon l’ordre de priorité suivant :
- Variables d’environnement : Idéal pour injecter dynamiquement des secrets lors du déploiement ou dans un pipeline CI/CD, sans laisser de traces sur le disque.
- Fichier
.dlt/secrets.toml: Un fichier local, non versionné, qui centralise les secrets pour le développement ou les environnements de test. Il permet de stocker plusieurs clés, organisées par section. Je vous déconseille fortement de l'utiliser, sauf en local sur des environnements de test. - Secret Manager cloud (AWS/GCP, optionnel) : Pour les déploiements en production, dlt peut interroger automatiquement les gestionnaires de secrets natifs du cloud afin de récupérer les valeurs sensibles de façon sécurisée. C'est ce qu'il faut utiliser en production.
- Valeur codée en dur dans le code : En dernier recours, une valeur par défaut peut être codée en dur, mais cette pratique est déconseillée pour la production. Je vous rappelle qu'on ne met jamais de secrets dans le code, donc à ne jamais faire !
Pour des besoins spécifiques, il est possible de définir un provider custom qui viendra compléter ou remplacer cette logique.
Exemple de fichier .dlt/secrets.toml
[github]
token = "ghp_…"N'utilisez pas ça en production (c'est pour l'exemple ici)
Ce fichier doit être exclu du contrôle de version (ajouté au .gitignore) afin de garantir la confidentialité des secrets. dlt init le fait par défaut lors de la création d'un nouveau projet.
Ce mécanisme permet de
- Centraliser la gestion des secrets pour tous les environnements.
- Sécuriser l’accès aux identifiants sensibles.
- Surcharger ou remplacer facilement les valeurs selon le contexte d’exécution, sans modifier le code.
Configuration hiérarchique et versionnable
dlt propose un système de configuration structuré, conçu pour être à la fois flexible, lisible et adapté au versioning. La configuration générale du pipeline est stockée dans le fichier .dlt/config.toml, qui définit les paramètres de fonctionnement, les options de logging, ou les réglages spécifiques à chaque source.
Exemple de fichier .dlt/config.toml
[pipeline]
log_level = "DEBUG"
[github]
per_page = 50paramétrisation dans le fichier de config
- Hiérarchique : Les paramètres sont organisés par section (pipeline, source, etc.), ce qui facilite la lecture et la maintenance.
- Versionnable : Ce fichier peut être ajouté au contrôle de version pour suivre l’évolution de la configuration au fil du temps, sans jamais contenir de secrets.
- Surchargeable à la volée : Chaque paramètre peut être temporairement modifié via une variable d’environnement, ce qui est particulièrement utile pour les tests, les déploiements automatisés ou les environnements multi-utilisateurs.
Exemple de surcharge via variable d’environnement
GITHUB__PER_PAGE=200
on peut aussi le faire via une variable d’environnement
Ici, le paramètre per_page de la section [github] est temporairement fixé à 200 pour la session en cours.
Ce modèle garantit
- Une séparation stricte entre configuration applicative et secrets.
- Une adaptation rapide du comportement du pipeline selon l’environnement ou le contexte d’exécution.
- Une traçabilité et une reproductibilité accrues grâce au versioning de la configuration.
En résumé, dlt offre une gestion robuste, sécurisée et flexible de l’authentification et de la configuration, adaptée aussi bien au développement local qu’aux déploiements en production.
Pagination avancée : GraphQL, curseur inversé, stream
L’ingestion de données via API implique souvent de gérer la pagination, c’est-à-dire la récupération séquentielle de gros volumes de données découpés en pages. dlt facilite la gestion de la pagination avancée grâce à ses helpers intégrés, couvrant plusieurs modes courants :
1. Pagination par page (offset/limit)
La méthode classique : chaque requête API récupère une page de résultats à l’aide de paramètres comme ?page=2 ou ?offset=100. dlt automatise ce schéma en incrémentant les paramètres appropriés à chaque appel.
2. Pagination par curseur (cursor-based)
De nombreuses APIs modernes (REST ou GraphQL) utilisent un curseur (cursor, start, after, etc.) pour pointer vers la position suivante dans le flux de données. Ce mode est plus robuste pour les datasets évolutifs ou volumineux. dlt détecte et adapte automatiquement le paramètre de curseur selon la convention de l’API.
3. Curseur inversé (reverse cursor)
Certaines APIs permettent de paginer “à rebours”, par exemple pour remonter dans l’historique, en utilisant un curseur pointant vers la page précédente. dlt gère ce cas en ajustant la direction de pagination et en maintenant la cohérence des données extraites.
4. Streaming continu
Pour les APIs qui supportent le streaming (données push ou polling continu), dlt permet de consommer les flux en temps réel, en itérant sur les nouveaux événements ou en maintenant une connexion ouverte.
Application dans dlt
dlt propose le helper RESTClient.get_paginated(auto_backoff=True) qui :
- Gère automatiquement la pagination, quel que soit le mode (page, curseur, reverse, stream).
- Adapte dynamiquement le paramètre de pagination (
?page=,?cursor=,?start=, etc.) selon la structure de l’API. - Implémente une politique de backoff automatique : si l’API retourne un code 429 (rate limit), dlt respecte le délai indiqué par
Retry-Afteravant de relancer la requête. - Émet des événements
rate_limitedconsultables dans le trace du pipeline pour un suivi précis des ralentissements ou blocages liés au throttling.
Exemple d’utilisation dans une resource dlt
from dlt.sources.helpers.rest_client import RESTClient
@dlt.resource(write_disposition="merge")
def fetch_all_issues(api_token: str = dlt.secrets.value):
client = RESTClient(
base_url="https://api.github.com",
headers={"Authorization": f"Bearer {api_token}"}
)
# Pagination automatique, gestion du rate limit
for issue in client.get_paginated(
"/repos/myorg/myrepo/issues",
params={"per_page": 100},
auto_backoff=True
):
yield issueparametrisation de la resource
À retenir
- dlt vous libère de la gestion manuelle de la pagination, même pour les APIs complexes (GraphQL, curseur inversé, stream).
- Le helper adapte automatiquement la logique de pagination et gère les limitations de débit.
- Les traces dlt permettent d’auditer précisément le comportement du pipeline face aux contraintes d’API.
Cela garantit une ingestion fiable, performante et résiliente, même sur des volumes importants ou des APIs exigeantes.
Pagination avancée : GraphQL, curseur inversé, stream
Le helper RESTClient propose get_paginated(auto_backoff=True) qui :
- suit la Backoff-Policy si l'API retourne 429 + Retry-After
- adapte le paramètre de page (
?page=/?cursor=/?start=) automatiquement - émet des events
rate_limitedconsultables dans le trace
Destinations & stratégies d'exécution
| Type | Exemples | Notes |
|---|---|---|
| Embedded | DuckDB | Idéal R&D, zéro serveur |
| Databases | Postgres, MySQL, MSSQL | SQLAlchemy, merge natif |
| Warehouses | BigQuery, Snowflake, Redshift, Databricks | COPY multithread, partitioning |
| Data Lakes | S3 + Parquet/Delta, GCS + Iceberg | Idempotence par version de fichier |
| Vector DB | Weaviate, Qdrant, LanceDB | embedding_column, upsert vector_id |
Changer de destination sans toucher au code
# même pipeline, nouveaux paramètres
dlt pipeline github_pipe --destination snowflake --dataset github_raw --credentials ~/.creds/snowflake.toml
En production on utilisera plutôt des secrets managers
Stratégies d'écriture & mise à jour des données
Avant de plonger dans les mécaniques avancées (merge, SCD2…), il est essentiel de comprendre les quatre grandes stratégies de gestion des écritures proposées par dlt. Elles déterminent comment les données sont insérées, remplacées ou mises à jour dans la destination cible.
Tableau comparatif des stratégies
| Disposition | Description | SCD | Déduplication | Historisation | Cas d’usage |
|---|---|---|---|---|---|
| append (défaut) | Rajoute les lignes | ❌ | ❌ | ❌ | Logs / événements bruts |
| replace | Drop + recreate + insert | ❌ | ❌ | ❌ | Snapshots batch |
| merge | UPSERT par primary_key |
❌ | ✅ | ❌ | CDC, SCD1 |
merge + "scd2" |
Versionnement complet | ✅ | ✅ | ✅ | Dimensions SCD2 |
ℹ️ Le choix de la stratégie dépend de la nature des données (transient vs master), de la source (API vs SQL) et du besoin de traçabilité (SCD, audit…).
Incrémental multi-curseurs
dlt permet de déclarer plusieurs curseurs afin de ne pas rater de lignes même si des valeurs inférieures subsistent dans l'une des colonnes :
cursor_ts = dlt.sources.incremental("updated_at") # timestamp
cursor_id = dlt.sources.incremental("id", initial_value=0) # identifiant
# Chaque curseur maintient son propre état indépendamment
# dlt utilise la valeur de chaque curseur pour filtrer les données correspondantes :
watermark = min(cursor_ts.last_value, cursor_id.last_value)
On peut aussi déclarer ces curseurs dynamiquement grâce à apply_hints :
issues.apply_hints(
write_disposition="merge",
primary_key="id",
incremental=dlt.sources.incremental("updated_at")
)
traque les mises à jour
ℹ️ primary_key & cursor : contrairement au curseur qui est unique, la primary_key peut être composite et dlt attend une liste.
Merge avancé : gestion des SCD2
@dlt.resource(
write_disposition={"disposition": "merge", "strategy": "scd2"}
)
def dim_customer():
yield [
{"customer_key": 1, "name": "Alice"},
{"customer_key": 2, "name": "Bob"},
]
pipe = dlt.pipeline("dim_pipeline", destination="duckdb")
pipe.run(dim_customer())
remplacement des lignes modifiées et ajout des nouvelles
- Les lignes inchangées sont conservées
- Les lignes modifiées créent une nouvelle version avec
_dlt_valid_from/_dlt_valid_to - Un hash
_dlt_idpermet de détecter les changements de contenu
Exemple append : ingestion brute de logs
@dlt.resource(write_disposition="append")
def web_events():
yield from [
{"user_id": 123, "event": "click", "timestamp": "2025-07-10T12:34:00Z"},
{"user_id": 456, "event": "signup", "timestamp": "2025-07-10T12:35:10Z"},
]
pipe = dlt.pipeline("events_pipeline", destination="duckdb")
pipe.run(web_events())mode append
Aucun risque de suppression accidentelle : les événements sont ajoutés à chaque exécution.
Exemple replace : snapshot complet
@dlt.resource(write_disposition="replace")
def dim_date():
yield from [
{"date": "2025-07-11", "is_weekend": False},
{"date": "2025-07-12", "is_weekend": True},
]
dlt.pipeline("dim_date_pipeline", destination="duckdb").run(dim_date())
écrasement de l'existant
Tous les enregistrements précédents sont recréés à chaque chargement : pratique si la source ne fournit pas de marque de mise à jour.
Change Data Capture (CDC) — Postgres → BigQuery
import dlt
from dlt.sources.helpers import connectorx
updated_at = dlt.sources.incremental(
"updated_at", initial_value="2000-01-01"
)
@dlt.resource(
name="orders",
primary_key="id",
write_disposition="merge"
)
def pg_orders():
query = "SELECT * FROM orders WHERE updated_at > :cursor"
yield from connectorx.read_sql(
"postgresql://user:pass@host/db",
query,
params={"cursor": updated_at.last_value},
)
pipe = dlt.pipeline("orders_pipeline", destination="bigquery")
pipe.run(pg_orders())
exemple de CDC (batch)
Pourquoi ça marche ?
incremental()conserve la valeur la plus récente deupdated_at- La requête SQL est paramétrée avec
cursor - Le mode
mergefait l'UPSERT automatique surid - Chaque exécution ne transfère que les lignes nouvelles ou modifiées
Suivi d’état & métadonnées opérationnelles du pipeline
trace = pipeline.last_trace
trace.print_summary()
# ➜ nb lignes, taille paquets, durée, CPU, retries
print(pipeline.state()["issues"]["updated_at"].last_value)
afficher le résumé des traces
Tables système
| Table | Rôle |
|---|---|
__dlt_loads | Journal des exécutions (id, timestamp, statut, erreurs) |
__dlt_pipeline_state | Curseurs, schéma, dernière exécution |
__dlt_version | Version dlt & compatibilité destination |
Refresh ciblé
pipeline.with_resources("orders").run(refresh="data")
rejouer seulement en partie le pipeline
data: recharge les données uniquementschema: reconstruit le schémaall: pipeline vierge (comme au premier run)
L'état nous aide à avoir
- des traces riches (temps, CPU, taux d'erreur)
- des tables système pour audit et reprise
- faire un refresh sélectif (sources | data | packages)
Performances, parallélisme & scalabilité
| Facteur | Mécanisme | Impact |
|---|---|---|
| Load parallelism | Threads / processus par job | + 200–300 MB/s |
| Chunk size | 100 k lignes (défaut) | RAM ↔ vitesse |
| ConnectorX | Lecteur SQL Rust | × 5–6 en extraction |
| Arrow IO | Colonnes + compression ZSTD | I/O réduit |
| Load package reuse | Pas de re-extract après crash | Idempotence / coût |
Pour les gros volumes (>1 To), combinez chunk_size, ConnectorX, partitionnement, et ajustez le nombre de threads.
C'est pour moi la partie qui vous demandera le plus de temps à maîtriser. Faites des tests empiriques ! Observez les performances pour ne pas surdimensionner votre infrastructure ou surcharger vos serveurs.
⚠️ Important
- Attention à ne pas tuer la base de données source surtout si c'est de la prod
- C'est très performant, mais si vous cassez la production, ne venez pas me voir ! 😃
- Pareil pour les APIs et autres services SaaS !
Gouvernance : schémas, contrats & évolution
Inspection & diff
$ dlt schema show github_pipe
Table `issues` cols: id:int, title:str, …
révision du schéma
Chaque exécution produit un fichier schema.<hash>.json ; on peut donc versionner les diffs (git diff).
Contrats
Ajustez la rigidité (souple, types stricts, colonnes gelées, contrat complet)
issues.apply_hints(comments_count={"data_type": "bigint", "nullable": False})
issues.freeze() # verrouille toute nouvelle colonne
exemple d'utilisation de contrat
dlt lèvera une SchemaViolationError si l'API renvoie un champ inattendu.
| Contrat (niveau de rigidité) | allow_new_columns | strict_types | Nullability / autres hints | Validation & exceptions | Cas d’usage typiques |
|---|---|---|---|---|---|
| Souple (par défaut) | True | False | Hérite du schéma existant ou des hints | Cast si possible, sinon SchemaViolationError | Exploration, prototypes, ingestion initiale |
| Types stricts | True | True | Hérite du schéma existant ou des hints | Erreur si le type ne correspond pas exactement | Qualité renforcée sans bloquer l’ajout de colonnes |
| Colonnes gelées | False (via freeze()) | False / True | Hérite du schéma existant ou des hints | Erreur dès qu’une colonne inattendue apparaît | API stables, pipelines critiques en production |
| Contrat complet | False | True | Nullability fixée (nullable=False, PK, …) | Erreur sur nouvelle colonne ou type/nullability incorrects | Données réglementées, reporting financier, conformité RGPD |
Astuce : vous pouvez combiner freeze(), strict_types=True et apply_hints() pour verrouiller simultanément les nouvelles colonnes, types et nullabilité.
Évolution guidée
Pour ajuster dynamiquement le comportement sans figer tout le pipeline :
allow_new_columns = True # (défaut) ➜ ajout automatique
strict_types = False # (défaut) ➜ cast si possible, sinon erreur
exemple de configuration des contrats d'un pipeline
Ces paramètres peuvent être appliqués globalement, par table, ou directement via les hints.
Conclusion
dlt se distingue par sa simplicité, sa puissance et sa flexibilité. Il permet de prototyper rapidement des pipelines légers dans un notebook, mais aussi de construire des architectures data robustes, versionnées et auditables, prêtes pour le cloud et la production.
À retenir concernant dlt
- Simplicité Python, zéro infra à maintenir
- Intégration fine : merge, scd2, schémas, observabilité
- Idéal de l'ad-hoc à la production full-scale
- La communauté dltHubers est à l’écoute
- Produit jeune, robuste, en évolution rapide
Ressources pour aller plus loin
- Cours certifiants et workshops gratuits
- Repo officiel
- Cours vidéo par Alexey Grigorev & Adrian Brudaru
- Communauté & support
Sur AWS, j'ai mis en place toute la stack avec un Airflow managé, un cluster ECS avec des tasks DBT et dlt pour gérer notre bronze, silver, gold sur Databricks. Aucun compute n'est fait sur Airflow mais bien dans les containers ou les DWH Databricks.
Si mon client était sur GCP, je ferais la même chose en remplaçant mes tasks ECS par des Cloud Run.







{kind=link}