
L'étincelle
Un matin d'automne, mon fil LinkedIn m'a proposé un article signé par un "top 10" du data engineering français. Intrigué par cette recommandation algorithmique, j'ai cliqué. Le conseil principal, adressé aux débutants qui souhaitent percer dans le métier, évoquait Hadoop.
J'ai relu. Puis relu encore. Hadoop... en 2025, sérieusement ?
Pourquoi conseiller ça à des novices ? Cela m'a mené à deux questions : une sur le contenu, l'autre sur le contenant.
Le paradoxe de l'expert
Pourquoi un professionnel établi recommande-t-il une technologie en déclin ? La question admet plusieurs réponses, toutes instructives.
L'inertie de l'expertise. Un consultant qui a bâti sa réputation sur Cloudera ou Hortonworks possède un capital de connaissances qu'il lui est difficile de déprécier publiquement. Recommander Hadoop, c'est implicitement valider son propre parcours, ses années d'investissement, ses certifications d'un autre temps. Personne n'aime admettre que le sol sur lequel il a construit sa maison s'est transformé en sable.
Le décalage avec le marché. Les experts établis travaillent parfois dans des niches techniques. Ils sont tellement experts dans leur domaine qu'ils pourront maintenir des clusters Hadoop pendant encore dix ans. Mais ces contextes ne sont pas représentatifs du marché global, où les architectures lakehouse, le data mesh et les plateformes cloud-native dominent les offres d'emploi. L'expert confond son écosystème avec l'écosystème.
La confusion entre fondamentaux et outils. Il est vrai que comprendre les principes du calcul distribué, du partitionnement, de la tolérance aux pannes reste précieux. Mais ces concepts s'apprennent aussi bien, voire mieux, via Spark, Kafka ou les certifications cloud (par exemple GCP Professional Data Engineer) que via une immersion dans l'écosystème Hadoop. Recommander l'outil alors qu'on veut enseigner le concept, c'est conseiller d'apprendre le latin pour comprendre la grammaire.
Un autre archétype mérite mention : l'expert qui dénigre les certifications tout en vendant sa propre formation. Le discours est rodé : « Les certifications ne prouvent rien, seule l'expérience compte. Et voici mon programme pour acquérir cette expérience. » Le paradoxe saute aux yeux : il délégitimise une forme de validation pour en substituer une autre, non reconnue par l'industrie mais monétisée par lui. Il abat un temple pour en ériger un autre : le sien.
Les cas sont légion. Je ne les citerai pas tous ici.
Mais avant de suivre un conseil, posez-vous une question simple : quel est l'intérêt de celui qui écrit ? Le mien ? Vous proposer un prochain article 😅.
Cinq critères pour évaluer un conseil technique
Comment distinguer une recommandation pertinente d'un écho du passé ? Voici cinq critères opérationnels que j'applique systématiquement.
Vérifier la demande du marché. Une recherche sur Glassdoor, Welcome to the Jungle ou LinkedIn révèle les profils que les entreprises recrutent réellement. Les offres mentionnant Spark, Airflow, dbt, Snowflake, BigQuery ou Databricks surpassent largement celles exigeant Hadoop. Les données sont publiques. Les ignorer est un choix.
Dater le conseil. Une recommandation d'il y a dix ans sur le Big Data n'a pas la même valeur qu'une analyse récente. Le rythme d'obsolescence dans notre domaine est brutal : cinq ans suffisent à transformer une best practice en anti-pattern. Vérifiez toujours la date de publication, et méfiez-vous des contenus qui n'en ont pas.
Identifier le contexte. « Apprenez Hadoop » est un conseil différent de « Apprenez Hadoop si vous ciblez des postes de maintenance legacy dans le secteur bancaire européen ». La première formulation est une injonction ; la seconde, une recommandation située. La généralisation abusive est un signal d'alerte.
Examiner les incitations. L'auteur vend-il une formation ? Un livre ? Des services de consulting sur la technologie qu'il recommande ? Les conflits d'intérêts ne disqualifient pas automatiquement un conseil, mais ils doivent être pris en compte. Suivez l'argent.
Croiser les sources. Reddit (r/dataengineering), Hacker News, les blogs d'engineering des grandes tech companies (Netflix, Uber, Airbnb) offrent des perspectives complémentaires, souvent plus proches du terrain que les tribunes LinkedIn. Un conseil qui ne survit pas au croisement des sources mérite la suspicion.
L'usine à contenus
Reste la seconde question : comment cet article avait-il atterri devant mes yeux ?
La réponse tient dans l'architecture des systèmes de recommandation. L'algorithme de LinkedIn, comme ceux de YouTube ou de Twitter, optimise l'engagement mais pas la pertinence. Il analyse vos clics, vos lectures, vos interactions passées pour vous proposer du contenu similaire. Si vous avez lu des articles sur le Big Data il y a cinq ans, il continuera de vous en proposer même si le paysage technique a changé.
Mais il y a plus préoccupant encore : la nature même du contenu a changé.
Imaginons que je suis entrepreneur ou consultant. Quoi de mieux que la visibilité sur LinkedIn ? C'est de la publicité gratuite. Chronophage, certes, mais gratuite. Or, depuis l'avènement des LLMs, cette contrainte a sauté.
La recette est connue :
- Publier régulièrement, une à plusieurs fois par semaine
- Viser le mardi ou le jeudi, aux heures où les gens prennent le métro
- Demander au LLM de rechercher les tendances sur sa spécialité
- Générer des dizaines d'articles à l'avance
- Planifier les envois
- Pour les plus paresseux : automatiser l'ensemble avec une clé API et un outil comme N8N
Le résultat ? Une inflation de contenus générés, optimisés pour l'algorithme, pas pour le lecteur. Des articles qui ressemblent à des articles. Des conseils qui ressemblent à des conseils. Une bibliothèque qui se remplit de livres que personne n'a vraiment écrits.
Et ces contenus, à leur tour, alimentent les LLMs qui généreront les contenus de demain. La boucle se referme.
L'empoisonnement
Ce cercle vicieux porte un nom : AI slop. Le terme, entré récemment dans le Cambridge Dictionary, désigne ce contenu numérique de basse qualité généré par IA, produit en masse sans égard pour la pertinence ou l'exactitude. C'est le spam de notre époque : omniprésent, optimisé pour l'engagement, vide de substance.
Mais le slop n'est que le symptôme. La maladie s'appelle model collapse. Quand un modèle de langage est entraîné sur des données générées par d'autres modèles, la qualité se dégrade génération après génération. Les nuances disparaissent. Les erreurs se cristallisent. Le signal se noie dans le bruit.
Ce qui vaut pour les modèles vaut pour nos fils d'actualité. De moins en moins de gens écrivent des articles de A à Z. De plus en plus de contenus sont générés, reformulés, recyclés par des machines. La proportion de texte authentiquement humain diminue, et avec elle, la proportion de pensée originale.
Mais voici le paradoxe : ce qui semble une catastrophe est aussi une opportunité.
Ce qui vous distingue d'un vibe coder

Si tout le monde peut générer du contenu en trois clics, qu'est-ce qui vous différencie ?
La réponse tient en quelques mots : l'expérience vécue, l'esprit critique, la capacité de jugement et l'authenticité.
Un LLM peut compiler des informations sur Hadoop. Il ne peut pas vous dire que cette technologie lui a coûté six mois de sa carrière. Il peut lister les avantages de Spark. Il ne peut pas raconter la frustration d'un cluster mal configuré à minuit, ni la satisfaction d'une pipeline qui tourne enfin.
Un LLM produit du texte probable. Vous produisez du texte ancré dans une expérience, un contexte, une trajectoire. C'est cette singularité qui a de la valeur. C'est elle que les recruteurs, les clients, les lecteurs recherchent, même s'ils ne savent pas toujours la nommer.
Bien entendu, je ne vis pas dans une grotte : j'utilise plusieurs LLMs au quotidien pour m'assister dans différentes tâches, y compris pour m'aider à la mise en forme de cet article.
Dans un océan de contenus génériques, l'authenticité devient un avantage compétitif.
Encore faut-il la cultiver.
Conclusion : la veille comme hygiène
La veille technologique n'est pas un luxe ; c'est une hygiène professionnelle. Mais elle exige un filtre critique, sans quoi elle devient une source de confusion plutôt que de clarté.
Les algorithmes de recommandation amplifient ce qui nous est familier. Les experts établis projettent leur parcours sur les nouveaux entrants. Les vendeurs de formations dénigrent les validations qu'ils ne contrôlent pas. Les LLMs inondent nos fils de contenus synthétiques. Dans ce bruit, la seule boussole fiable reste l'analyse directe du marché : que demandent les offres d'emploi ? Quelles architectures déploient les entreprises qui recrutent ? Quelles compétences valorisent-elles réellement ?
Ces questions sont prosaïques. Elles n'ont pas l'élégance d'un conseil d'oracle. Mais elles ont un avantage décisif : elles peuvent être vérifiées.
Et dans un monde où la vérification devient rare, c'est peut-être la compétence la plus précieuse.
La suite de cet article, "L'Ascension du Data Engineer", proposera un learning path concret pour débuter dans le métier. Pas une liste de technologies à la mode, mais une stratégie de montée en compétences adaptée au marché réel.

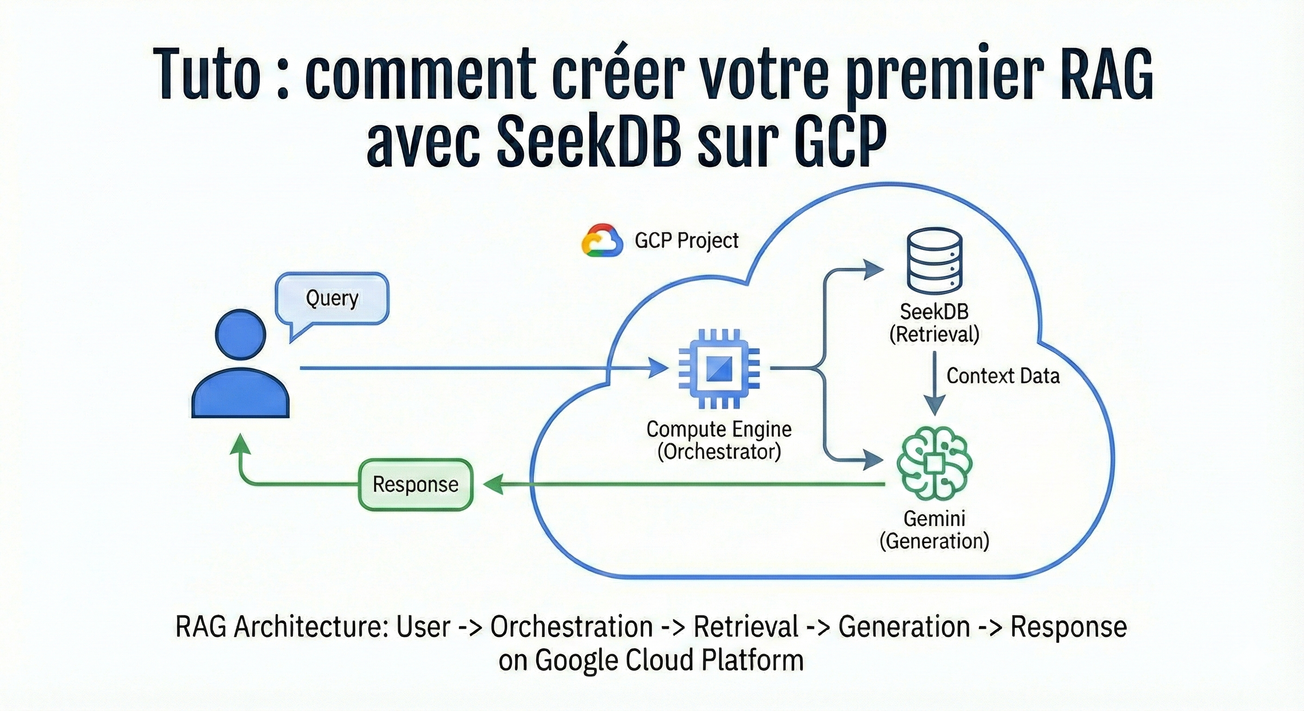





{kind=link}