Comment je structure un ticket avant que l'IA touche la moindre ligne de code.
On m'a souvent reproché de passer trop de temps sur le cadrage. "Tu perds du temps, lance-toi."
Depuis que je pilote des agents IA sur RAISE, la plateforme GenAI de SFEIR, je passe plus de temps qu'avant sur le cadrage — et je livre quatre fois plus vite que le moi version 2025.
Ce n'est pas un paradoxe, c'est la seule chose qui a vraiment changé dans ma pratique.
Cet article s'adresse aux développeurs et tech leads qui utilisent Claude Code, Cursor, Copilot ou équivalent en équipe, avec des dizaines de PRs à merger par semaine.
Si tu as lu l'épisode 1, cet article répond au premier red flag : "l'IA résout le ticket, plus personne ne tient le cadre." Si tu pratiques déjà le SDD d'Erwan Le Tutour avec Specify, saute directement à la section sur la règle des trois reformulations — je tourne autour de sa méthode, sans l'outillage.
Je vais montrer, sur un ticket que j'ai écrit il y a quelques semaines sur RAISE, comment un cadrage de cinq minutes divise par six le temps de revue, fait passer le taux d'imports fantômes de 14 % à 2 %, et rend l'IA honnête sur ce qu'elle ne sait pas.
Le vibe coding n'est pas le problème, c'est l'absence de cadrage qui l'est
Lucas Macori a posé la définition du vibe coding avec ses trois dangers : sécurité, maintenabilité, absence de tests. Erwan Le Tutour a proposé la suite logique : le Specification Driven Development, outillé avec Specify/Speckit — tu écris spec.md, plan.md, task.md, puis tu laisses Gemini exécuter. Les deux articles sont justes.
Aucun des deux ne dit ce que je fais en équipe.
Specify formalise une méthode. C'est précieux pour un POC. Sur une plateforme en production avec trente contributions mergées par semaine par des devs de séniorités variées, tu ne peux pas demander à un junior d'installer un outil supplémentaire, d'apprendre six commandes /speckit.* et de générer trois fichiers Markdown à chaque ticket.
Il faut que le cadrage tienne dans le workflow existant : le ticket Jira ou l'issue GitHub, le CLAUDE.md partagé, et la discussion de cinq minutes en standup.
Ma règle : le cadrage doit être plus court que l'exécution. Si écrire le ticket prend plus de temps que coder la feature à la main sans IA, il y a un problème dans le ticket, pas dans l'IA.
Comment structurer un ticket en 5 minutes ?
La plupart des tickets IA qu'on voit échouer ont un point commun : ils disent ce qu'on veut faire, mais jamais ce qu'on ne fait pas. L'IA, elle, comble — et c'est là que ça dérape.
Voici le template qu'on a fini par adopter après plusieurs itérations. Six sections, pas une de plus :
- Intention — une phrase qui dit pourquoi on fait ça. Pas le quoi. Le pourquoi.
- Contraintes — les limites dures : compatibilité, perf, sécurité, noms de variables imposés.
- Non-goals — ce qu'on ne fait pas dans ce ticket. C'est la section la plus importante, et celle qu'on oublie en premier.
- Fichiers à toucher — 3 à 7 chemins, pas plus.
- Fichiers interdits — les modules sensibles que l'IA ne doit pas ouvrir. L'auth, les migrations, les intégrations clients.
- Critères d'acceptation — en Gherkin ou en phrases simples, mais vérifiables.
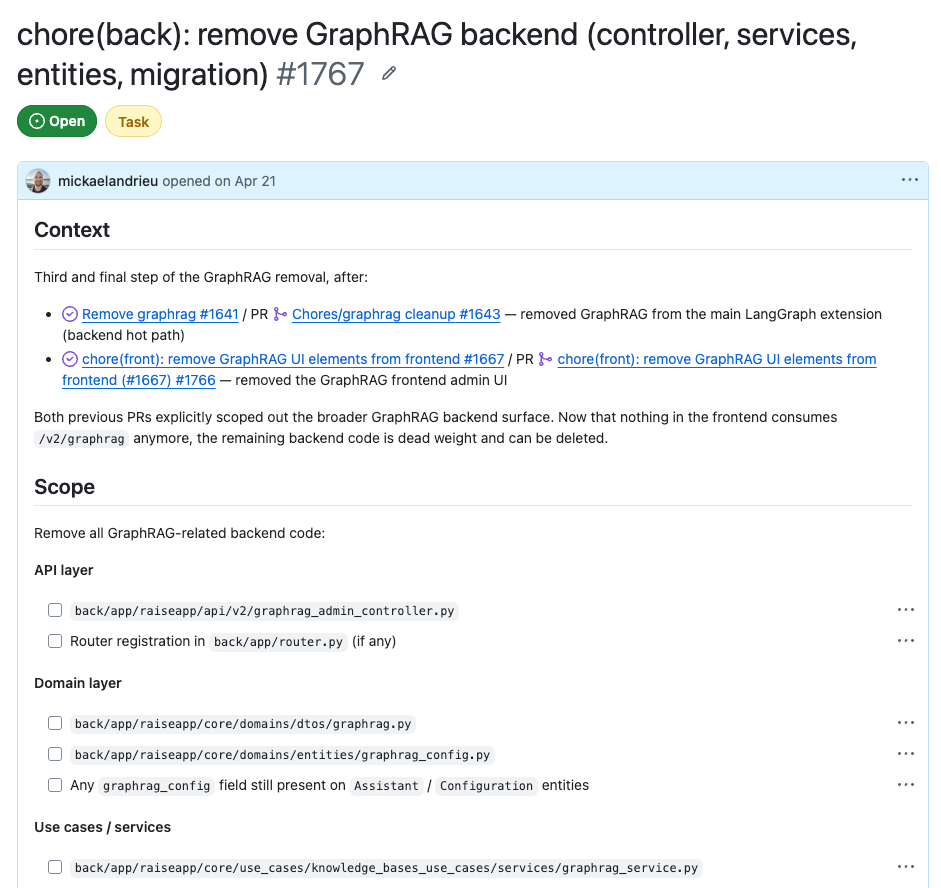
Le ticket que j'ai écrit la semaine dernière sur RAISE illustre les six cases cochées. Intitulé : "chore(back): remove GraphRAG backend — controller, services, entities, migration".
C'est la troisième et dernière étape d'un retrait qu'on étale sur trois semaines. L'intention tient en deux lignes, avec renvoi explicite aux deux PRs précédentes qui ont déjà vidé le hot-path LangGraph puis l'UI admin — c'est la façon la plus économique de poser les non-goals : "ce qu'on ne refait pas ici parce que c'est déjà fait ailleurs".
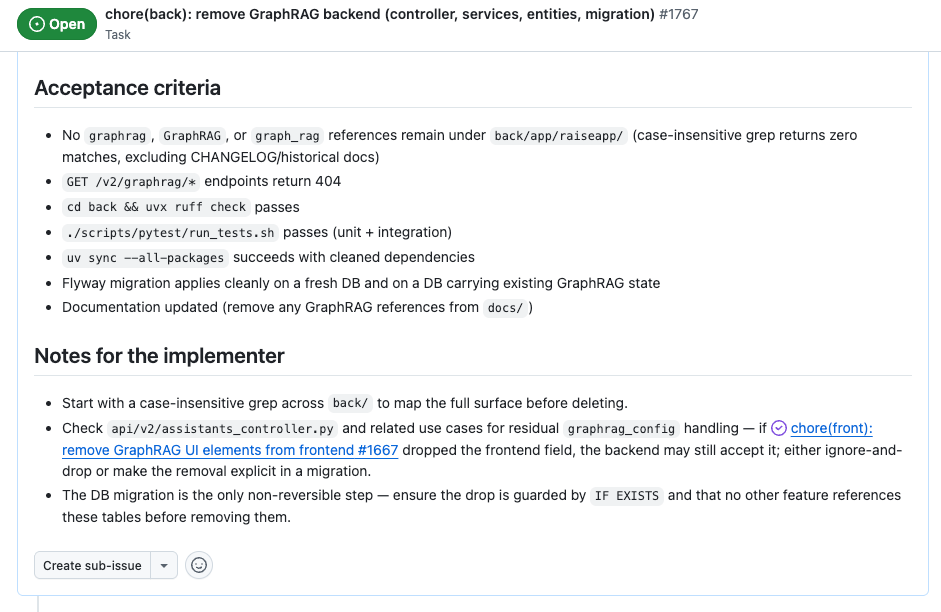
Les contraintes portent sur la migration base, qui doit être idempotente (DROP ... IF EXISTS). La section "Fichiers à toucher" liste vingt-trois chemins exacts, organisés couche par couche : API controller, DTOs, entities, use-cases, tests unitaires, tests d'intégration, wiring DI, migration Flyway.
Les fichiers interdits ? Aucun — parce qu'on a validé avant d'ouvrir le ticket qu'aucun consommateur ne subsistait.
C'est précisément cette vérification préalable qui rend le ticket "automatisable". Les critères d'acceptation tiennent en une ligne : la suite de tests passe sans les fichiers supprimés, la migration tourne en idempotent sur une base déjà nettoyée.
À comparer avec un ticket qu'on voit souvent passer : "Ajouter des bulk actions dans l'admin."
L'objectif est clair sur le papier, mais il ne dit pas sur quels listings (il y a trois candidats possibles dans l'admin), ne mentionne aucun fichier, et ne pose aucun non-goal. L'IA peut partir dans trois directions en parallèle, avec trois conceptions différentes du mot "delete" — soft ou hard, cascade ou pas.
Ce n'est pas nécessairement un mauvais ticket humain (et encore). C'est juste un ticket qui n'est pas IA-ready. La différence entre les deux n'est pas dans la complexité du code à produire — elle est dans les cinq minutes qu'on a pris, ou pas, pour délimiter le périmètre avant d'ouvrir l'éditeur.
Comment cadrer quand le besoin n'est pas clair ?
La moitié des tickets ne sont pas prêts à être codés au moment où ils arrivent. Pas par mauvaise volonté — parce que personne n'a pris dix minutes pour écrire ce qu'on voulait vraiment.
J'ai une méthode pour ça : la règle des trois reformulations.
Je colle le ticket dans Claude, je demande "reformule ce que tu comprends, en une phrase". Je lis. Je corrige ce qui a dérivé. Je redemande. Je corrige. Je redemande une troisième fois.
Ma règle : si au troisième passage la reformulation n'est pas celle que j'attends, le problème n'est pas prêt à être codé. Il faut retourner parler au PO, au client, ou à mon "cerveau du matin", après le café.
(Il m'a fallu six mois pour admettre que le faux-ticket, c'était souvent le mien — pas l'IA qui ne comprenait rien.)
Exemple (fictif) de ticket qui n'aurait pas passé le test, la semaine dernière : "améliorer la pagination des rapports". Reformulation 1 : "ajouter plus de pages". Reformulation 2, après correction : "réduire le temps de chargement de la liste des rapports". Reformulation 3 : "ajouter un cache côté serveur sur les rapports". Trois interprétations, trois features différentes, aucune qui soit celle demandée — laquelle, au fait ? Retour au PO : il voulait en fait "garder la position de scroll quand on revient à la liste après avoir ouvert un rapport". Aucun rapport avec la pagination. Coût évité : une demi-journée de code pour la mauvaise feature.
Ce test fait passer un nombre gênant de faux-tickets au rebut avant que l'IA n'ait touché une ligne. Coût : cinq minutes. Gain : ne pas ouvrir une PR de 600 lignes qu'on va rejeter.
Evidemment, maintenant je me sers d'un agent pour qualifier les tickets, mais avant de créer l'agent faîtes d'abord manuellement.
Comment empêcher l'IA d'inventer ce qu'elle ne sait pas ?
Les modèles hallucinent des fichiers. Pas parfois — souvent. Ils inventent un helpers/csv.py parce que c'est plausible, puis l'importent, puis testent contre cet import fantôme. La CI peut même passer si le mock est cohérent avec le fichier inventé (cf. red flag #3 de l'épisode 1).
La règle : tout fichier mentionné dans une PR doit exister avant qu'on le réutilise, ou être listé dans la section "Fichiers à toucher" du ticket — sinon rejet.
C'est bête, c'est mécanique, c'est redoutable. Sur un échantillon de 120 PRs avant/après application de la règle sur RAISE, on est passé de 14 % de PRs avec au moins un import fantôme à 2 %.
(Les 2 % restants ? Je n'ai pas l'explication à ce stade, l'enquête suit son cours)
Plus le ticket est pauvre en contexte, plus l'IA comble ; plus elle comble, plus elle hallucine. Ton ticket est ton garde-fou.
Pourquoi cinq minutes de cadrage économisent trente minutes de revue
Un ticket bien cadré est une forme de relecture anticipée. Tu as formulé l'intention, posé les contraintes, délimité le périmètre — c'est la moitié du travail mental de review, fait avant qu'il y ait du code.
C'est le même mécanisme que la relecture à voix haute qu'on apprend en école primaire : on trouve ses erreurs parce qu'on reformule avant qu'elles soient figées.
Et ça me rappelle aussi l'époque où j'avais "Dark Duck", un canard en plastique avec un casque de dark vador, auquel j'expliquais ce que j'essayais de faire quand je tombais sur un bug que je ne parvenais pas à tâcler. Je pense qu'avec l'IA, plus personne n'utilise de canard .. ?

Reformuler en amont coûte une fraction du coût de reformuler en aval, sur 600 lignes de diff, en étant fatigué un vendredi soir.
Je n'ai pas d'étude à citer, juste un an de mesures empiriques sur RAISE :
- Temps moyen de revue d'une PR bien cadrée = 6 minutes.
- Temps moyen d'une PR mal cadrée à taille équivalente = 35 minutes.
La différence, ce n'est pas la qualité du code — c'est la clarté de l'intention.
Ce que je retiens de mon expérience tient en quelques lignes.
Le cadrage ne remplace pas l'IA, il la rend utilisable. Six champs sur une page, dont les non-goals qui sont à la fois la section la plus oubliée et la plus décisive.
Plusieurs reformulations avant d'envoyer, parce qu'un ticket dont l'IA ne retrouve pas l'intention est un ticket qui n'est pas prêt — quel que soit le modèle.
Et une règle dure sur les fichiers : tout ce qui est mentionné doit exister ou être listé, sinon rejet.
Je le répète : Si le cadrage commence à prendre plus de temps que l'exécution, c'est le ticket qui a un problème — pas l'IA.
Bonus : le ticket rédigé à l'oral
Astuce que j'ai découvert dans une vidéo d'un développeur freelance "full IA" et que je n'abandonne plus : dicter le ticket à voix haute pendant deux minutes, puis demander à l'IA de le transformer en template structuré.
Parler est plus rapide qu'écrire, et surtout plus honnête : on entend ce qui coince, on se reprend, on précise naturellement. L'IA ne fait qu'une chose — remettre en forme. Elle n'invente rien parce qu'il y a tout le matériau dans la transcription.
J'ai mis plus de dix ans à accepter de parler à mon ordinateur, et honnêtement, hormis sur Mac je n'ai jamais été satisfait de la qualité de la retranscription.
Aujourd'hui c'est le premier geste quand j'ouvre un ticket vide. Comme quoi, l'outil qu'on snobe le plus longtemps est parfois celui qui change le plus de choses !
Maintenant que tu sais cadrer un ticket, la question suivante est : une fois la PR produite, qu'est-ce que tu acceptes, qu'est-ce que tu refuses, qu'est-ce que tu réécris ? Ce sera le sujet principal de l'épisode 3 de cette série : "Accepter, refuser, réécrire : ma grille de décision pour les PRs IA."
Mais encore ... ?
Depuis la date de rédaction et préparation de cet article, la structuration et les sections de nos issues ont encore changé, bien aidées par le feedback de chaque membre de l'équipe, et de nos outils d'évaluation de la qualité de nos agents.
S'il faudra un jour que je contribue sur la thématique de l'évaluation de la qualité des agents et des processes, ce qu'il faut retenir pour cet article, c'est que vous devez adapter les outils et les méthodes à chaque projet.
Les développeurs en 2026, conçoivent et améliorent en continu les systèmes qui leur permettent de piloter nos agents.