
Le context engineering
Introduction
Claude Code, c'est l'outil qui a changé ma façon de coder. J'ai commencé avec un abonnement Pro... et j'ai très vite été limité ! Quand j'ai fait le calcul de la projection de ma consommation, j'ai réalisé que même avec un abonnement max x5 ou x10 ça ne suffirait peut-être pas.
Le coût moyen rapporté par Anthropic, c'est 6 $ par développeur par jour avec Sonnet 4.6, et 90% des utilisateurs restent sous les 12 $/jour. En usage équipe, ça représente 100 à 200 $ par développeur par mois. Et avec Opus ? On monte encore plus vite.
Le problème, ce n'est pas le prix du token en soi. C'est qu'on en gaspille une bonne partie sans s'en rendre compte. Un CLAUDE.md trop long, des serveurs MCP inutilisés, des sessions qui traînent, des prompts vagues qui déclenchent des explorations infinies... Chaque token gaspillé, c'est du budget en moins pour les tâches qui comptent.
Ce qu'on appelle aujourd'hui le context engineering — l'art de contrôler ce qui entre dans la fenêtre de contexte d'un LLM — est un enjeu universel. Cursor a ses règles conditionnelles .mdc, Aider propose 3 niveaux de configuration et un repo map, Codex CLI a son AGENTS.md, Gemini CLI son GEMINI.md avec hooks, GitHub Copilot ses multipliers de requêtes premium, Kiro CLI ses specs. Les mécanismes diffèrent, mais le problème est le même : maîtriser ce que l'agent voit pour maîtriser ce qu'il coûte.
Cet article se concentre sur Claude Code, mais les stratégies sont transposables à n'importe quel outil de coding assisté par IA. Voici ce qu'on va couvrir :
- Comprendre ce qui consomme des tokens (et où se cachent les coûts)
- Optimiser votre CLAUDE.md et vos skills
- Organiser vos configurations par projet et maîtriser vos MCP
- Automatiser avec les hooks notamment pour éviter les gaspillages récurrents
- Adopter les bons réflexes au quotidien
Étape 1 : Comprendre
Comment Claude Code consomme vos tokens
Avant d'optimiser, il faut comprendre la mécanique. Chaque message que vous envoyez à Claude Code ne se limite pas à votre question : il embarque tout un contexte.
Anatomie d'une requête
À chaque tour de conversation, voici ce qui est envoyé à l'API :
- Le system prompt : les instructions internes de Claude Code (~quelques milliers de tokens)
- Votre CLAUDE.md : chargé intégralement, à chaque message
- Les descriptions de skills : noms + descriptions de toutes les skills disponibles
- Les définitions d'outils MCP : chaque serveur MCP actif injecte ses outils dans le contexte
- L'historique de conversation : tout ce qui a été dit depuis le début de la session
- Les outputs des outils : le contenu des fichiers lus, les résultats de commandes, les réponses MCP
Le coût ne vient pas d'un seul de ces éléments, mais de leur accumulation. Et surtout : ces tokens sont envoyés à chaque message. Un CLAUDE.md de 1 000 lignes, c'est ~4 000 tokens facturés à chaque interaction, pas une seule fois !
Le contexte qui grossit
Le piège classique : vous démarrez une session, vous explorez le code, vous lisez des fichiers, vous lancez des commandes... et sans vous en rendre compte, votre fenêtre de contexte se remplit.
Prenons un scénario courant :
- Vous posez une question → Claude lit 5 fichiers pour comprendre le code → ~10 000 tokens d'outputs de lecture
- Vous demandez un fix → Claude lance les tests → ~5 000 tokens d'output de tests
- Vous demandez une amélioration → Claude lit 3 fichiers supplémentaires → ~6 000 tokens
En 3 échanges, vous avez accumulé ~21 000 tokens de contexte qui seront renvoyés intégralement au prochain message. Le coût par message augmente au fil de la conversation.
Les coûts cachés
Certains postes de consommation sont moins visibles :
- Extended thinking : activé par défaut avec un budget de 31 999 tokens. Ces tokens de "réflexion" sont facturés au tarif des tokens de sortie (le plus cher). Pour une tâche simple comme renommer une variable, c'est du gaspillage pur
- Auto-compaction : quand le contexte atteint ~95% de la fenêtre, Claude résume automatiquement la conversation. Ce résumé consomme des tokens (entrée et sortie), mais c'est un mal nécessaire
- Résumés de sessions : Claude génère des résumés en arrière-plan pour la fonctionnalité
--resume, coûtant environ 0,04 $ par session
/cost (en mode API) ou /usage en mode abonnement pour le suivi d'usage, et /stats pour vos habitudes d'utilisation (streaks, modèles favoris). Vous pouvez aussi configurer votre status bar pour afficher le contexte utilisé en continu.Les prix en un coup d’œil
| Modèle | Input (par M tokens) | Output (par M tokens) | Usage type |
|---|---|---|---|
| Haiku 4.5 | 1 $ | 5 $ | Sous-agents, tâches simples |
| Sonnet 4.6 | 3 $ | 15 $ | Usage quotidien |
| Sonnet 4.6 (>200K ctx) | 6 $ | 22,50 $ | Long context |
| Opus 4.6 | 5 $ | 25 $ | Raisonnement complexe |
| Opus 4.6 (>200K ctx) | 10 $ | 37,50 $ | Grosses codebases |
Maintenant que vous avez une idée de la mécanique des tokens et des prix, intéressons-nous à un poste de consommation souvent sous-estimé : les serveurs MCP.
MCP : le mangeur de contexte silencieux
Les serveurs MCP (Model Context Protocol) connectent Claude Code à des services externes : Notion, GitHub, Slack, bases de données... Chaque serveur actif injecte ses définitions d'outils dans le contexte. Et ça chiffre vite.
Le coût réel
Chaque serveur MCP ajoute entre 3 000 et 15 000 tokens de définitions d'outils au contexte, selon le nombre d'outils qu'il expose. Avec 10 serveurs actifs, vous pouvez facilement atteindre 60 000 à 100 000 tokens de contexte occupé avant même d'avoir tapé un mot.
Sur une fenêtre de 200K tokens (ou 1M en bêta avec Sonnet 4.6), c'est 30 à 50% de votre contexte consommé par des descriptions d'outils que vous n'utilisez peut-être même pas dans cette session.
Diagnostiquer avec /context
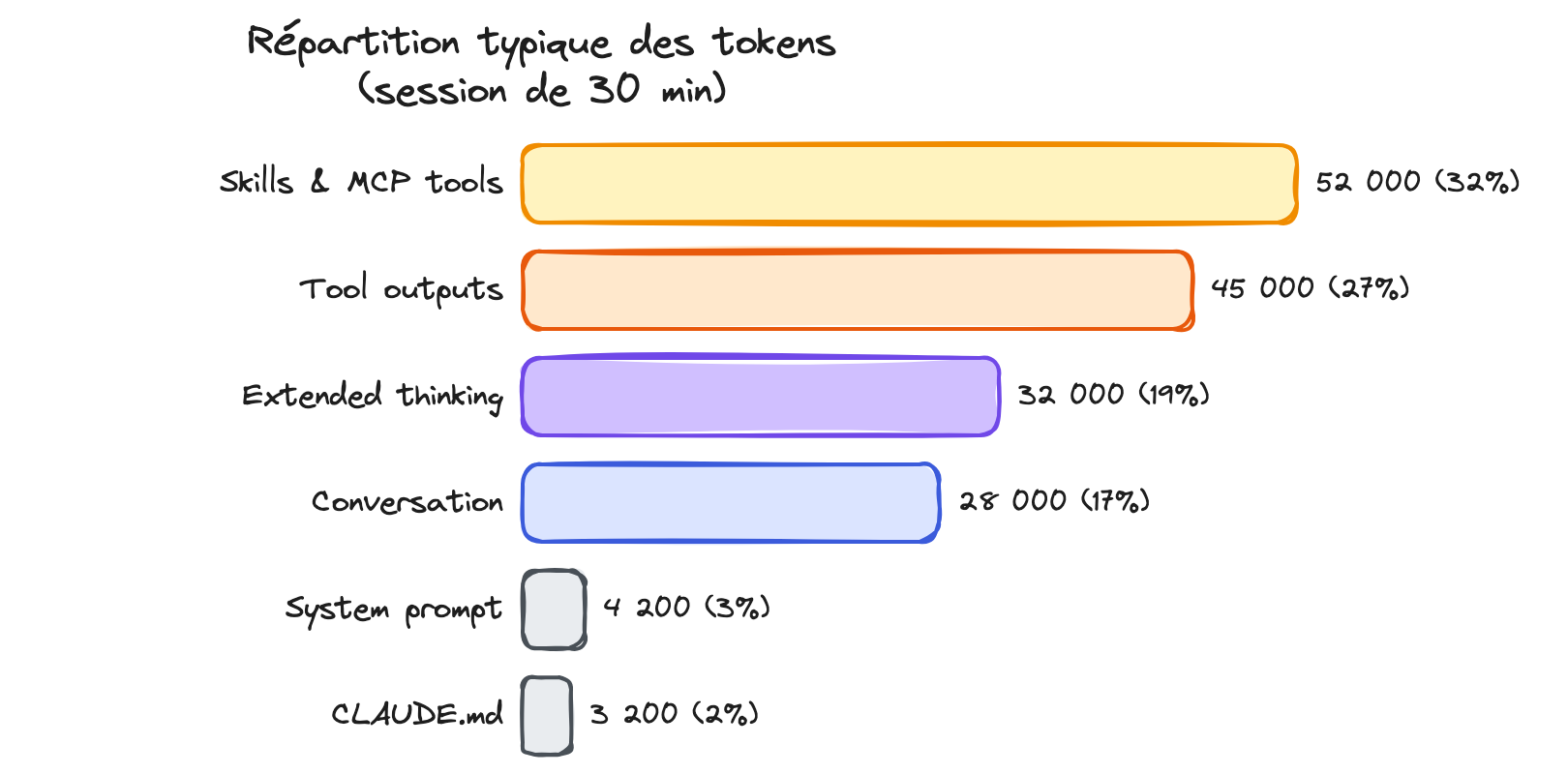
La commande /context affiche ce qui consomme votre contexte. Lancez-la et regardez la section MCP :
> /context
System prompt: 4,200 tokens
CLAUDE.md: 480 tokens
Skill descriptions: 320 tokens
MCP tools: 52,400 tokens ← le problème est là
Conversation: 8,300 tokens
---
Total: 65,700 tokens
Étape 2 : Optimiser
Votre CLAUDE.md vous coûte cher (et vous ne le savez pas)
Le CLAUDE.md, c'est le fichier de mémoire de Claude Code. Il est chargé intégralement au début de chaque session, et son contenu est inclus dans chaque message envoyé à l'API.
Un CLAUDE.md de 100 lignes bien ciblées ? Pas de problème. Un CLAUDE.md de 800 lignes avec des instructions pour chaque workflow possible ? Vous payez ces 800 lignes à chaque interaction, même quand vous ne faites qu'un simple git status.
Le calcul
Prenons un exemple concret :
- CLAUDE.md de 200 lignes (~800 tokens) : sur 50 messages dans la journée = 40 000 tokens d'input
- CLAUDE.md de 800 lignes (~3 200 tokens) : sur 50 messages = 160 000 tokens d'input
La différence : 120 000 tokens par jour, soit environ 0,36 $ de plus par jour avec Sonnet 4.6. Ça paraît peu, mais sur un mois de travail (20 jours), c'est 7,20 $ de gaspillage. Et avec Opus, on double.
Ce qui doit rester dans le CLAUDE.md
La règle d'or d'Anthropic : gardez votre CLAUDE.md sous ~500 lignes. Pour chaque ligne, posez-vous la question : "Est-ce que Claude ferait une erreur sans cette instruction ?" Si la réponse est non, supprimez-la.
Ce qui doit rester :
- Les commandes bash que Claude ne peut pas deviner (
bun testau lieu denpm test) - Les conventions de code qui diffèrent des standards du langage
- Les instructions de test et le runner préféré
- Les conventions Git (nommage de branches, format des commits)
- Les décisions d'architecture spécifiques au projet
- Les variables d'environnement et quirks du setup dev
Ce qui doit partir :
- Les instructions détaillées pour des workflows spécifiques (PR reviews, migrations DB, déploiements)
- La documentation d'API (mettez un lien plutôt)
- Les descriptions fichier par fichier de la codebase
- Les conventions standard que Claude connaît déjà
- Les tutoriels et explications longues
Avant / Après
Avant (780 lignes, ~3 100 tokens) :
# Projet MonApp
## Architecture
Le projet est structuré en modules...
[200 lignes de description de l'architecture]
## Conventions de code
[100 lignes de conventions]
## Workflow PR
1. Créer une branche feature/xxx
2. Faire les changements
3. Lancer les tests avec bun test
4. Créer la PR avec gh pr create
[80 lignes de détails sur le workflow PR]
## Workflow de déploiement
[120 lignes]
## Workflow de migration DB
[100 lignes]
## Guide de debug
[80 lignes]
## API Reference
[100 lignes]CLAUDE.md
Après (120 lignes, ~480 tokens) :
# Projet MonApp
## Commandes
- Tests : `bun test`
- Lint : `bun lint`
- Build : `bun run build`
- DB migrations : `bun db:migrate`
## Conventions
- ES modules (import/export), pas de CommonJS
- Nommage de branches : feature/xxx, fix/xxx, refacto/xxx
- Commits conventionnels : feat:, fix:, refacto:, docs:
## Architecture
- Monorepo avec packages/ (api, web, shared)
- API : Hono + Drizzle ORM + PostgreSQL
- Web : Next.js 15 + Tailwind
## Important
- Toujours lancer les tests après une série de changements
- Préférer les tests unitaires isolés pour le dev (pas la suite complète)CLAUDE.md
Les 660 lignes supprimées ? Elles deviennent des skills chargées à la demande dans ce que l'on va voir juste après.
Skills : le chargement à la demande qui change tout
Les skills sont le mécanisme clé pour garder un CLAUDE.md léger sans perdre en fonctionnalités. Le principe : progressive disclosure.
Comment ça marche
Au démarrage d'une session, Claude Code charge uniquement le nom et la description de chaque skill (le frontmatter YAML). Chaque skill consomme environ 30 à 50 tokens dans le contexte initial. Le contenu complet de la skill n'est chargé que lorsque Claude décide qu'elle est pertinente, ou quand vous l'invoquez avec /skill-name.
Comparaison directe :
| Approche | Tokens au démarrage | Tokens quand utilisé |
|---|---|---|
| Instructions dans CLAUDE.md | ~3 000 (toujours) | ~3 000 (toujours) |
| Skill dédiée | ~50-100 (description) | ~3 000 (à la demande) |
Sur 50 messages où vous n'utilisez pas ce workflow : ~150 000 tokens économisés avec l'approche skill.
Refactoring concret : du CLAUDE.md vers une skill
Prenons les 80 lignes de workflow PR qui étaient dans le CLAUDE.md. On les déplace dans une skill :
mkdir -p .claude/skills/create-pr.claude/skills/create-pr/SKILL.md :
---
name: create-pr
description: Crée une PR avec les conventions du projet (branch naming, tests, review checklist)
disable-model-invocation: true
---
## Workflow PR
1. Vérifier que les tests passent : `bun test`
2. Vérifier le lint : `bun lint`
3. Créer la branche si pas encore fait : `feature/xxx` ou `fix/xxx`
4. Commit avec message conventionnel
5. Push et créer la PR avec `gh pr create`
## Checklist PR
- [ ] Tests passent
- [ ] Pas de TODO laissé dans le code
- [ ] Types à jour
- [ ] Documentation mise à jour si API publique modifiéeRésultat :
- Au démarrage : la skill coûte ~40 tokens (juste le frontmatter)
- Quand invoquée (
/create-pr) : le contenu complet est chargé - Quand non utilisée : zéro impact sur le contexte
disable-model-invocation: trueLe flag disable-model-invocation
Par défaut, Claude peut décider seul de charger une skill s'il juge qu'elle est pertinente. C'est pratique pour les skills de type "conventions" ou "référence", mais pour les workflows avec des effets de bord (déploiement, envoi de messages, création de PR), vous voulez garder le contrôle.
disable-model-invocation: true empêche Claude de l'invoquer automatiquement et retire sa description du contexte. Zéro token consommé tant que vous ne l'invoquez pas vous-même avec /skill-name.
| Flag | Tokens au démarrage | Chargement |
|---|---|---|
| Par défaut | ~50-100 (description) | Auto par Claude ou /skill-name |
disable-model-invocation: true |
0 | /skill-name uniquement |
disable-model-invocation: true pour tous vos workflows d'action (deploy, PR, release). Gardez le comportement par défaut pour les skills de type référence (conventions, patterns, architecture).Rules conditionnelles : le juste milieu
Entre le CLAUDE.md (toujours chargé) et les skills (invoquées à la demande), il existe un mécanisme intermédiaire : les rules (.claude/rules/*.md). Elles permettent de découper vos instructions en fichiers modulaires.
Sans frontmatter paths:, une rule est chargée à chaque message, comme le CLAUDE.md. L'intérêt est purement organisationnel. Mais avec paths:, elle ne se charge que quand Claude travaille sur des fichiers qui matchent le pattern glob : 0 token le reste du temps.
Exemple : des conventions React chargées uniquement sur les fichiers concernés :
---
paths:
- "src/components/**/*.tsx"
- "src/hooks/**/*.ts"
---
# Conventions React
- Composants fonctionnels uniquement
- Custom hooks dans src/hooks/
- Tests colocalisés : Component.test.tsx
Voici le spectre complet des mécanismes de chargement :
| Mécanisme | Tokens au démarrage | Quand chargé |
|---|---|---|
| CLAUDE.md | ~800+ (toujours) | Chaque message |
Rule sans paths |
Idem CLAUDE.md | Chaque message |
Rule avec paths |
0 | Quand fichier matche |
| Skill (auto) | ~50-100 (description) | Quand Claude juge pertinent |
Skill (disable-model-invocation) |
0 | /skill-name uniquement |
💡 Les rules conditionnelles sont idéales pour les conventions spécifiques à un sous-dossier ou une techno (frontend vs backend, Terraform vs Python). Pour les workflows avec effets de bord, préférez les skills.
Fichiers de support : charger encore moins
Le CLAUDE.md, les skills ou les rules peuvent inclure des fichiers additionnels. Claude ne les charge que quand il en a besoin. Par exemple :
create-pr/
├── SKILL.md # Instructions principales (~500 tokens)
├── pr-template.md # Template de body PR (~200 tokens)
└── examples/
└── good-pr.md # Exemple de bonne PR (~300 tokens)
dans le .claude/skills
Référencez-les dans le SKILL.md pour que Claude sache qu'ils existent :
## Ressources
- Template de PR : [pr-template.md](pr-template.md)
- Exemple de bonne PR : [examples/good-pr.md](examples/good-pr.md)Claude chargera le template uniquement quand il crée effectivement une PR. Les 300 tokens de l'exemple ne seront lus que si Claude estime en avoir besoin.
Tool Search : l'optimisation automatique
Claude Code détecte automatiquement quand les descriptions d'outils MCP dépassent 10% de la fenêtre de contexte. Quand ce seuil est franchi, il active le Tool Search : les outils sont mis en mode "deferred" et ne sont chargés que quand Claude en a réellement besoin.
D'après les retours d'expérience, le Tool Search peut faire passer la consommation de contexte MCP de ~134 000 tokens à ~5 000 tokens, soit une réduction de 85 à 96% selon le nombre d'outils.
Par défaut, le Tool Search s'active quand les outils dépassent 10% du contexte. Vous pouvez abaisser ce seuil pour un déclenchement plus agressif par exemple :
# Abaisser le seuil de 10% (défaut) à 5% du contexte
ENABLE_TOOL_SEARCH=auto:5
Les bons réflexes MCP
- Désactivez les serveurs inutilisés :
/mcp→ désactivez ceux dont vous n'avez pas besoin pour la tâche en cours - Préférez les CLI quand c'est possible :
ghau lieu d'un MCP GitHub,awsau lieu d'un MCP AWS,gcloudau lieu d'un MCP GCP. Les CLI n'ajoutent aucun token de définition au contexte - Gardez moins de 80 outils actifs au total pour maintenir un contexte sain
Avoir 20+ serveurs MCP configurés globalement alors que chaque projet n'en utilise que 3-4, c'est le scénario classique de gaspillage
Étape 3 : Organiser
Organiser ses configurations par projet
Vous avez allégé votre CLAUDE.md, créé des skills... mais où vivent ces configurations ? Claude Code propose plusieurs niveaux de réglages, et les confondre peut ruiner vos efforts d'optimisation.
La hiérarchie
Deux mécanismes coexistent, et ils ne fonctionnent pas pareil :
Les settings (JSON) suivent une logique de priorité : le plus spécifique gagne. De la priorité la plus haute à la plus basse : Managed Policy → CLI flags → .claude/settings.local.json (projet, non versionné) → .claude/settings.json (projet, versionné) → ~/.claude/settings.json (user). Si vous définissez model: "opus-4-6" au niveau projet et model: "sonnet-4-6" au niveau user, c'est Opus qui s'applique.
Les CLAUDE.md suivent une logique d'accumulation : tous les niveaux sont concaténés et envoyés à chaque message. Votre ~/.claude/CLAUDE.md personnel + le CLAUDE.md du projet + celui du sous-dossier, tout s'additionne.
L'implication FinOps est directe : un ~/.claude/CLAUDE.md user de 300 lignes, c'est ~1 200 tokens ajoutés dans tous vos projets, même ceux qui n'en ont pas besoin. Les settings, eux, s'overrident sans accumulation.
Les MCP, les agents, les skills, les hooks existent aussi à deux niveaux : ~/.claude.json (global) et .mcp.json (projet). Les serveurs MCP définis globalement sont chargés partout. Ceux définis au niveau projet ne le sont que dans ce projet.
L'impact des plugins sur le contexte
Les plugins Claude Code sont des packages qui peuvent embarquer des MCP servers, des skills, des agents et des hooks. Côté contexte, ce sont les MCP servers des plugins qui pèsent le plus. Par exemple : Playwright injecte ~20 outils, Notion ~10 outils, chacun avec sa description. C'est une super feature pour partager plus largement des configurations qui sont liées entre-elles (skill, agent, mcp) mais elles amplifient également le problème !
Le piège : si vous activez des plugins au niveau user (enabledPlugins dans le ~/.claude/settings.json), ils se chargent dans tous vos projets. Vous faites du Terraform ? Notion, ses skills et ses 20 outils sont quand même là...
enabledPlugins dans le .claude/settings.json de chaque projet. Chaque projet n'active que ce dont il a besoin.La stratégie du "projet par thème"
Un pattern que j'utilise au quotidien : créer un dossier projet dédié par activité, même quand il n'y a pas de "vrai" code. On a souvent besoin d'un peu de markdown de toute façon (notes, références, drafts), et ça donne un point d'ancrage pour des configurations ciblées.
L'idée : quand vous changez de thème, vous changez de dossier. Chaque dossier a son propre CLAUDE.md, ses propres plugins activés, ses propres MCP, ses propres skills, ses propres agents. Zéro pollution croisée.
| Projet | CLAUDE.md | Plugins actifs | Ce qu'on évite |
|---|---|---|---|
api-backend/ |
Conventions Hono + Drizzle | GitHub | Playwright, Notion |
articles/ |
Style guide, workflow rédaction | context7, Notion | GitHub, Playwright |
infra-gcp/ |
Conventions Terraform | GCP, GitHub | Notion, Playwright |
documentation/ |
Style doc interne | Notion, Wiki.js | GitHub, Playwright |
Un exemple de .claude/settings.json pour un projet infra :
{
"enabledPlugins": ["github"],
"disabledMcpServers": ["notion", "playwright"]
}Combiné avec un CLAUDE.md léger et ciblé, chaque projet ne charge que le strict nécessaire. Le switch d'un projet à l'autre se fait naturellement en changeant de répertoire, et Claude Code adapte automatiquement son contexte.
Étape 4 : Automatiser
Deux types de hooks peuvent réduire votre consommation et le premier que je vais aborder n'a même rien à voir avec Claude !
- les hooks git : qui empêchent Claude de faire du travail inutile
- les hooks Claude Code : qui contrôlent ce que Claude voit
Les hooks git : éviter à Claude de le faire
Avant même de parler de Claude Code, il y a les hooks git. Le framework pre-commit, par exemple, permet d'exécuter des formateurs et linters automatiquement à chaque commit.
L'avantage FinOps : si terraform fmt passe à chaque commit, Claude n'a jamais besoin de formater lui-même. Pas d'instruction dans le CLAUDE.md (tokens à chaque message), pas de demande manuelle (tokens par action). Le formatage est garanti par git, zéro token.
# .pre-commit-config.yaml
repos:
- repo: https://github.com/antonbabenko/pre-commit-terraform
rev: v1.105.0
hooks:
- id: terraform_fmt
pre-commit install
Le même principe s'applique à Prettier, Black, gofmt, rustfmt...
Les hooks Claude Code : intercepter et filtrer
Claude Code a son propre système de hooks : des scripts shell déclenchés à des moments précis du cycle de vie (PreToolUse, PostToolUse, Notification...). Contrairement aux instructions CLAUDE.md, ils sont déterministes : exécution garantie, zéro token consommé pour la décision.
Un use case FinOps : tronquer les outputs volumineux. Un brew install, un npm install, un build Docker — ces commandes produisent des centaines de lignes que Claude n'a pas besoin de voir intégralement. Un hook PreToolUse sur Bash peut wrapper la commande avant exécution grâce à updatedInput :
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "truncate-output.sh"
}
]
}
]
}
}
Le hook reçoit sur stdin un JSON contenant tool_input.command (la commande que Claude veut exécuter). Le script peut alors la wrapper — par exemple transformer npm install en npm install 2>&1 | tail -n 20 — et retourner la commande modifiée via updatedInput. Claude ne voit que la sortie tronquée.
PostToolUse intervient après l'exécution. Il peut ajouter du contexte supplémentaire (additionalContext) ou signaler un problème (decision: "block"), mais il ne peut pas remplacer l'output que Claude a déjà reçu. Le champ updatedMCPToolOutput qui permet de substituer une réponse ne fonctionne que pour les outils MCP, pas pour les outils natifs comme Bash. Pour réellement réduire les tokens d'output, il faut agir avant avec un PreToolUse qui wrappe la commande.Hooks vs CLAUDE.md & Skills
| Besoin | CLAUDE.md & Skills | Hook git | Hook Claude Code |
|---|---|---|---|
| Formater les éditions | ✅ | ||
| Linter les fichiers | ✅ | ||
| Filtrer les outputs volumineux | ✅ | ||
| Bloquer l'écriture dans certains fichiers | ✅ | ||
| Convention de code, framework utilisé | ✅ | ||
| Notification quand Claude attend | ✅ |
La règle : si ça doit arriver à chaque fois sans exception, c'est un hook. Si c'est une information que Claude doit garder en tête, c'est le CLAUDE.md & Skills.
Étape 5 : Adopter les bons réflexes
Les réflexes qui sauvent la mise
Au-delà de l'architecture (CLAUDE.md, skills, hooks), ce sont vos habitudes quotidiennes qui font la différence.
/clear entre les tâches
C'est le réflexe le plus rentable. Quand vous passez d'une tâche à une autre, le contexte de la tâche précédente n'a plus aucune valeur. Pire : il occupe de la place et peut induire Claude en erreur.
# Vous venez de finir un bugfix
> /rename fix-pagination
> /clear
# Nouvelle tâche, contexte propre
> Ajoute un système de tags sur les tâches...
/rename avant /clear pour retrouver facilement la session avec --resume si vous en avez besoin plus tard./compact avec des instructions ciblées
Quand vous êtes en pleine session et que le contexte gonfle, /compact résume la conversation. Par défaut, Claude résume ce qu'il juge pertinent. Mais vous pouvez guider la compaction :
/compact Garde uniquement les modifications de fichiers et les résultats de tests
Ou configurez-le directement dans votre CLAUDE.md :
# Instructions de compaction
Lors d'une compaction, conserve la liste complète des fichiers modifiés,
les commandes de test utilisées, et les décisions d'architecture prises.Choisir le bon modèle et ajuster l'effort
Avec Sonnet 4.6, le conseil a changé. Les benchmarks parlent d'eux-mêmes :
| Benchmark | Sonnet 4.6 | Opus 4.6 | Écart |
|---|---|---|---|
| SWE-bench Verified (coding) | 79.6% | 80.8% | 1.2 pts |
| OSWorld (computer use) | 72.5% | 72.7% | 0.2 pts |
Pour presque 2x moins cher (3 $/15 $ vs 5 $/25 $), Sonnet 4.6 est quasi au niveau Opus sur les tâches de coding. Le bon réflexe FinOps : Sonnet 4.6 par défaut, Opus uniquement pour les tâches où il fait encore la différence — architecture complexe multi-fichiers, debug de problèmes subtils, raisonnement sur de très gros contextes. Changez en cours de session avec /model.
Les deux modèles intègrent l'Adaptive Thinking : ils décident dynamiquement quand et combien réfléchir. Pour un simple rename, pas de budget thinking gaspillé. Vous pouvez aller plus loin en ajustant le reasoning effort :
- low : réflexion minimale, moins de tool calls, réponses plus courtes — idéal pour les tâches simples en série
- medium : équilibre par défaut
- high : réflexion approfondie — pour l'architecture et le debug complexe
Configuration : slider dans /model, variable d'environnement CLAUDE_CODE_EFFORT_LEVEL, ou effortLevel dans settings.json. L'impact du low est multiplicatif : moins de thinking et moins de tool calls et des réponses plus courtes.
MAX_THINKING_TOKENS=8000. Attention : cette variable force le thinking sur toutes les requêtes, même celles qui n'en auraient pas eu besoin naturellement. À utiliser avec précaution.Écrire des prompts précis
Un prompt vague comme "améliore ce code" déclenche une exploration large : Claude va lire de nombreux fichiers, analyser la structure, chercher des patterns... Beaucoup de tokens pour un résultat... incertain.
Un prompt précis comme "ajoute la validation des inputs sur la fonction loginUser dans @src/auth/login.ts" permet à Claude de cibler directement le bon fichier, faire le changement, et passer à la suite.
| Prompt vague | Prompt précis |
|---|---|
| "Corrige le bug de login" | "Le login échoue après expiration du token. Vérifie le refresh dans src/auth/. Écris un test de régression." |
| "Ajoute des tests" | "Écris un test pour la fonction validateEmail dans @src/utils/validation.ts, couvrant les cas : email valide, chaîne vide, email sans @" |
| "Refactorise ce fichier" | "Extrais la logique de parsing de @src/api/handler.ts dans un module séparé src/utils/parser.ts" |
Plan mode pour les tâches complexes
Avant d'implémenter une feature conséquente, passez en Plan Mode (Shift+Tab). Claude explore la codebase et propose un plan sans modifier de fichiers. Vous validez le plan, puis passez en mode normal pour l'implémentation.
L'avantage pour les tokens : un plan mal orienté détecté tôt coûte quelques milliers de tokens. Une implémentation mal orientée qu'on doit refaire, c'est des dizaines de milliers de tokens jetés.
Les sous-agents : isoler le contexte
Chaque sous-agent tourne dans sa propre fenêtre de contexte, isolée du parent. Il ne hérite pas de l'historique de votre conversation. Seul le résumé ou le résultat final remonte dans le contexte principal.
Quand les utiliser :
- Tâche qui produit du verbose output (audit, analyse de couverture, rapport de dépendances)
- Travail autonome qui ne dépend pas du contexte courant
- Tâches indépendantes et parallélisables
Le coût : chaque sous-agent a son propre overhead (system prompt, outils). Si le sous-agent doit relire des fichiers que le parent connaît déjà pour comprendre le contexte, c'est du travail dupliqué. Le surcoût est réel quand la tâche déléguée dépend fortement du contexte courant.
En revanche, pour des tâches indépendantes, les sous-agents sont souvent plus économes au total. En séquentiel dans votre conversation, chaque étape ajoute ses fichiers au contexte, et tout est renvoyé à chaque message suivant — le coût croît à chaque tour. Avec des sous-agents parallèles, chacun travaille dans son coin et seul le résumé remonte.
Exemple concret : vous voulez auditer la couverture de tests de 5 modules. En séquentiel, Claude lit ~15 fichiers par module et le contexte grossit à chaque étape : au 5e module, il traîne les 4 précédents. Avec 5 sous-agents en parallèle, chacun ne lit que ses 15 fichiers et remonte un résumé de ~500 tokens. Résultat : 2 500 tokens dans votre contexte principal, un contexte propre pour la suite — et c'est plus rapide.
Récapitulatif : les leviers d'optimisation
Conclusion
Optimiser sa consommation de tokens sur Claude Code, ce n'est pas être radin. C'est du FinOps appliqué : chaque token doit servir à produire de la valeur.
Plusieurs leviers ont été abordés dans cet article :
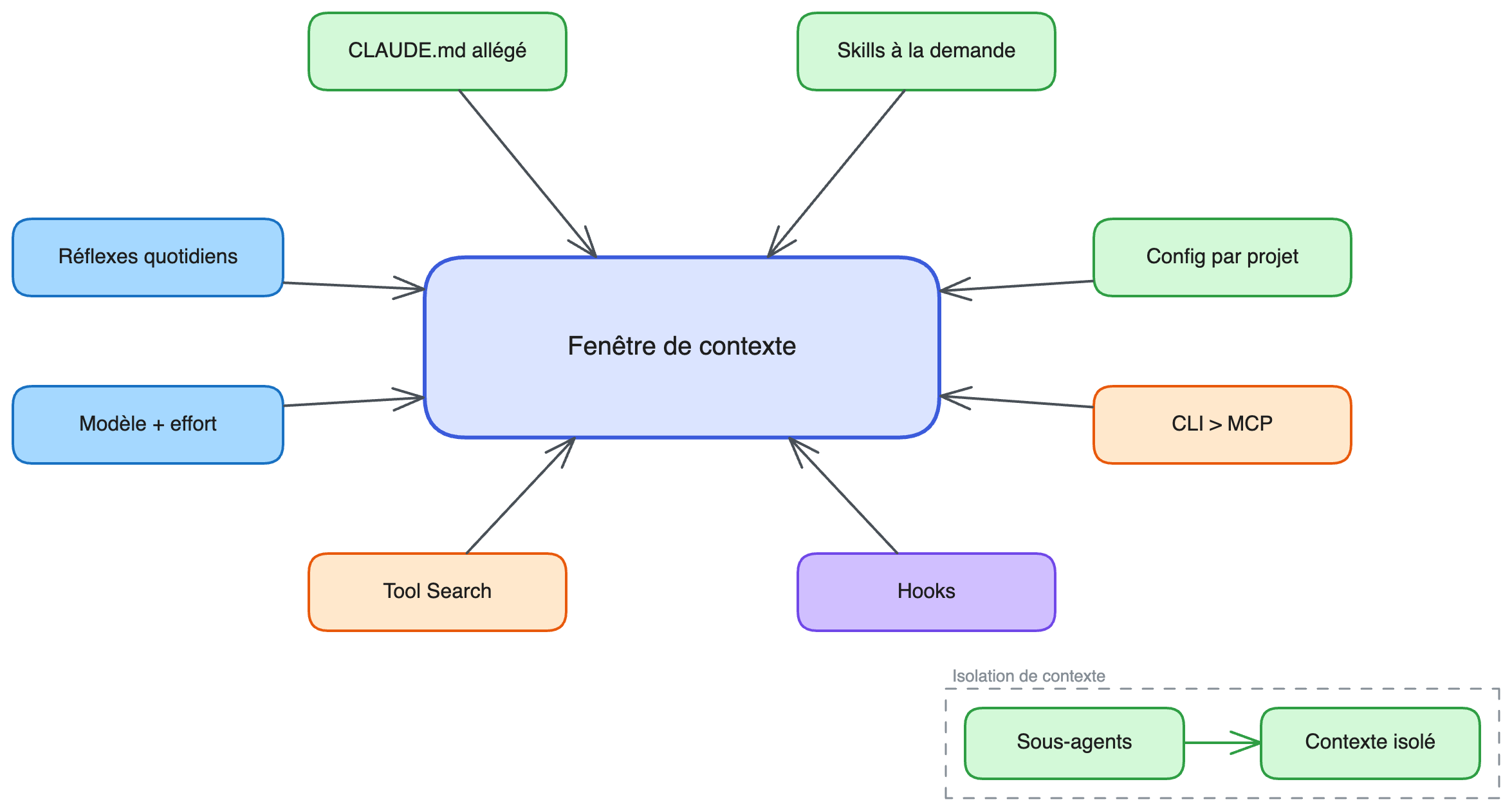
- Structurel (à faire une fois, fort impact) : alléger le CLAUDE.md, utiliser des rules conditionnelles, créer des skills à la demande, organiser les configurations par projet
- MCP (à revoir régulièrement) : ajuster le Tool Search, remplacer les MCP par des CLI quand c'est possible, désactiver l'inutile par projet
- Automatisation (hooks) : formateurs automatiques, hooks git pre-commit, filtres d'output sur les commandes répétitives éventuellement
- Quotidien (réflexes) :
/clearentre les tâches,/compactavec instructions ciblées, prompts précis, bon modèle + effort adapté, sous-agents pour isoler le contexte
Le setup initial prend une heure ou deux. Le retour sur investissement, c'est la première semaine. Et au-delà de l'économie financière, un contexte propre, c'est aussi un Claude qui performe mieux : moins de contexte inutile = des réponses plus pertinentes.
Commencez par lancer /context dans votre prochaine session. Regardez ce qui consomme. Agissez en conséquence.
Sources :
- Manage costs effectively - Claude Code Docs
- Extend Claude with skills - Claude Code Docs
- Automate workflows with hooks - Claude Code Docs
- Best Practices for Claude Code - Claude Code Docs
- Configuration hierarchy - Claude Code Docs
- Manage Claude's memory - Claude Code Docs
- Plugins - Claude Code Docs
- Sub-agents - Claude Code Docs
- Model configuration - Claude Code Docs
- Pricing - Claude API Docs
- Stop Wasting Tokens: How to Optimize Claude Code Context by 60% - Jpranav (Medium)
- Token Optimization Techniques - claude-code-ultimate-guide (DeepWiki)
- Optimising MCP Server Context Usage - Scott Spence






{kind=link}