
En ce moment, il y a un mot qu’on entend partout : OpenClaw.
Mais au fond, c’est quoi ? Et pourquoi faut-il faire très attention en l’utilisant ?
OpenClaw promet des agents IA capables d’agir à votre place : lire vos mails, créer des tickets, ouvrir des PR. Puissant, oui. Mais derrière l’automatisation se cache une nouvelle surface d’attaque : prompt injection, fuite de secrets, mémoire persistante. Voici pourquoi il faut rester vigilant.
“Je veux un assistant qui fait.”
On a tous eu ce moment :
“J’aimerais un assistant qui ne se contente pas de répondre, mais qui agit.”
Trier mes messages.
Réserver un restaurant.
Déplacer un rendez-vous.
Résumer des fichiers.
Et si possible… depuis la messagerie que j’utilise déjà.
C’est pour ça qu’un mot revient partout ces derniers temps : OpenClaw.
Si tu as l’impression de voir aussi passer Clawdbot ou Moltbot, ce n’est pas une illusion : le projet a changé de nom à plusieurs reprises, notamment après une demande liée à une marque “Clawd”.
OpenClaw s’inscrit exactement dans cette logique : un assistant IA self-hosted, pilotable par chat, capable d’enchaîner des actions via des “skills” et de conserver du contexte dans le temps.
Le piège ?
La frontière entre “pratique” et “dangereux” devient très fine dès qu’on connecte des outils (shell, fichiers, navigateur, email) à un modèle qui peut être influencé.

L’évolution, du chatbot à l’agent en passant par les MCP
Pour comprendre la différence entre un chatbot, un MCP et un agent, prenons un exemple simple : préparer un plat.
Un chatbot, c’est comme demander une recette.
Tu lui dis ce que tu as dans le frigo. Il te propose des idées, détaille les étapes, donne des conseils.
Mais il ne touche à rien. Il ne démarre pas le four. Il ne lance pas de minuteur.
Un MCP (Model Context Protocol), c’est comme ajouter une prise standard entre le “cerveau” et les ustensiles.
Tu connectes des outils : lire une liste d’ingrédients dans ton Drive, créer une liste de courses, lancer un minuteur, récupérer une température de cuisson.
Le MCP ne rend pas le système autonome : il standardise l’accès aux outils et aux données.
Un agent, c’est autre chose.
Tu dis : “Je veux un curry pour 19h.”
Et le système s’organise.
Il planifie.
Il choisit une recette adaptée.
Il vérifie ce que tu as déjà.
Il identifie ce qu’il manque.
Il lance les actions au bon moment.
Il demande validation si une étape est sensible.
C’est ce changement d’échelle qu’apportent les agents “always-on” comme OpenClaw : moins d’exécution manuelle, plus d’orchestration.

Le détail qui change tout : l’agent peut déléguer à des sous-agents
OpenClaw peut créer des sous-agents pour paralléliser le travail.
Un sous-agent peut explorer un repository, analyser des logs, préparer un patch ou produire un résumé pendant que l’agent principal continue à discuter avec toi.
C’est puissant.
Mais c’est aussi une surface de risque.
Car plus il y a d’autonomie, plus il devient difficile de savoir précisément qui fait quoi — surtout si ces sous-agents ont accès à des outils sensibles.
La vraie force d’OpenClaw : les “skills”
La puissance d’OpenClaw ne vient pas seulement du modèle.
Elle vient des outils qu’il peut appeler : les skills.
Lire et écrire sur le disque.
Lancer une commande.
Appeler une API.
Piloter un navigateur.
Envoyer un message sur un canal.
OpenClaw se présente comme une gateway que tu exécutes chez toi ou sur un serveur.
Tu la connectes à des canaux comme WhatsApp, Telegram, Discord ou Microsoft Teams.
Tu envoies une demande depuis un chat.
La gateway la rattache à une session.
L’agent choisit les outils nécessaires.
Il exécute.
Il te renvoie le résultat.
Avec un agent always-on, on change de régime :
- On ne fait plus du one-shot. On reprend des conversations.
- On introduit de l’état : sessions, traces, parfois mémoire persistante.
- On délègue des actions, pas seulement des réponses.
- On active des capacités à la demande, via des skills spécialisés.
Cas pratique : du mail à la PR
Un client envoie un mail avec un bug report : contexte, étapes pour reproduire, logs en pièce jointe, et une question simple : “Pouvez-vous corriger ?”
Ce que peut faire l’agent :
- Lire le mail et comprendre la demande.
- Produire un résumé actionnable : impact, conditions de reproduction, composants concernés.
- Chercher si une issue similaire existe déjà.
- Créer une issue GitHub si nécessaire :
- titre clair,
- étapes pour reproduire,
- logs nettoyés des secrets,
- labels et assignation.
- Préparer une branche et une PR :
- correction minimale,
- mise à jour des tests,
- description courte,
- référence à l’issue.
- Demander validation avant toute action irréversible.
Le gain n’est pas dans la rédaction d’un ticket.
Il est dans la chaîne complète.
Et c’est précisément là que commencent les risques.
Risques concrets observés sur l’écosystème
Le problème n’est pas “l’IA”.
Le problème, c’est l’intégration sans garde-fous.
L’attaque la plus simple : le faux “pré-requis” en copy/paste
Un pattern revient dans les analyses : beaucoup de skills malveillants ne ressemblent pas à du code suspect dans le SKILL.md. Le piège est ailleurs.
Elles demandent souvent d’installer un “pré-requis” via une commande copiée-collée. Cette commande récupère un script ou un binaire externe, parfois obfusqué, puis l’exécute. Autrement dit : la skill sert de prétexte crédible pour te faire exécuter un installateur.

https://www.esecurityplanet.com/threats/hundreds-of-malicious-skills-found-in-openclaws-clawhub/
Retrait ≠ disparition : forks, miroirs, dépôts annexes
Même quand une skill est retirée d’un registre, elle peut continuer à circuler. Il suffit qu’elle ait été forkée, miroirée, republiée ailleurs, ou déjà installée dans un workspace. Résultat : tu peux croire que “c’est réglé” parce que la fiche officielle n’existe plus, alors que le contenu reste installable par des chemins alternatifs.
Dans un écosystème d’agents, ça complique la réponse à incident : retirer un élément du catalogue ne garantit pas qu’il a disparu des environnements déjà contaminés.
“Agents entre eux” : quand une plateforme devient une surface d’injection
L’incident Moltbook est un bon exemple du risque “agents entre eux”. Moltbook se présentait comme un espace de type forum pour agents. Des chercheurs ont identifié une exposition massive de données, liée à une configuration backend trop permissive, ce qui a entraîné la fuite de messages privés et d’identifiants.
Ce cas a aussi marqué pour une raison culturelle : selon Reuters, le fondateur a déclaré n’avoir écrit aucune ligne de code, l’application ayant été construite via une approche de “vibe coding”. Ce contexte compte, car il illustre un mélange explosif : une mise en production rapide, peu de contrôles, et une surface d’attaque énorme.
Pourquoi c’est un amplificateur : si ton agent lit des posts, des commentaires, des messages générés par d’autres agents, chaque contenu devient une entrée non fiable. Et si l’agent a des outils connectés, une entrée non fiable peut influencer une action réelle.
https://www.esecurityplanet.com/threats/hundreds-of-malicious-skills-found-in-openclaws-clawhub/
“C’est en local, donc c’est safe” : faux confort
Self-hosted ne veut pas dire “sans risque”. Ça veut dire “le risque se déplace”.
On a déjà vu apparaître des cas où des info stealers exfiltrent des fichiers de configuration liés à OpenClaw, avec des tokens et clés d’API. TechRadar rapporte par exemple des observations attribuées à Hudson Rock : l’agent n’est pas forcément ciblé spécifiquement, il est ciblé parce qu’il stocke des secrets attractifs.
Traduction : une compromission “poste classique” peut devenir une compromission “identité d’agent”, avec accès à tes intégrations.

Si on reprend notre exemple ci dessus le risque est simple : prompt injection via un mail client
Si on prend l’exemple que nous avons vu avant alors on se rend compte d’un défaut majeur: il ouvre une porte directe entre un contenu non fiable (le mail client) et des actions réelles.
Un attaquant n’a pas besoin d’accéder à ton système. Il lui suffit d’envoyer un mail qui ressemble à un bug report. Dans le corps du mail, dans une pièce jointe, ou même dans un patch “proposé”, il peut glisser des instructions destinées à influencer l’agent.
Ce que ça peut provoquer :
- Exfiltration : l’agent copie dans une issue ou une PR des informations sensibles récupérées ailleurs pendant sa chaîne de travail.
- Action non voulue : l’agent ouvre une PR qui “corrige” le bug, mais ajoute au passage une modification discrète, par exemple un appel réseau, un téléchargement, ou une collecte de logs trop large.
- Auto-contamination : si l’agent conserve des notes, des résumés, ou des décisions, une consigne malveillante peut se retrouver répétée plus tard.
C’est la définition même d’une prompt injection : une entrée modifie le comportement du modèle d’une manière non prévue, parce qu’elle a été intégrée au contexte de décision.
C’est exactement la zone décrite par Simon Willison avec la “lethal trifecta” : données privées + contenu non fiable + capacité d’action/communication. Et c’est renforcé par l’idée de mémoire persistante discutée par Palo Alto Networks : une attaque peut être “à retardement” si un agent conserve du contexte exploitable.
La “Lethal Trifecta”… et la mémoire en plus
Le concept de “Lethal Trifecta” popularisé par Simon Willison explique que dès qu’un agent a :
- accès à des données privées,
- exposition à du contenu non fiable,
- capacité de communiquer/exécuter, il devient structurellement vulnérable à des attaques de type prompt injection.
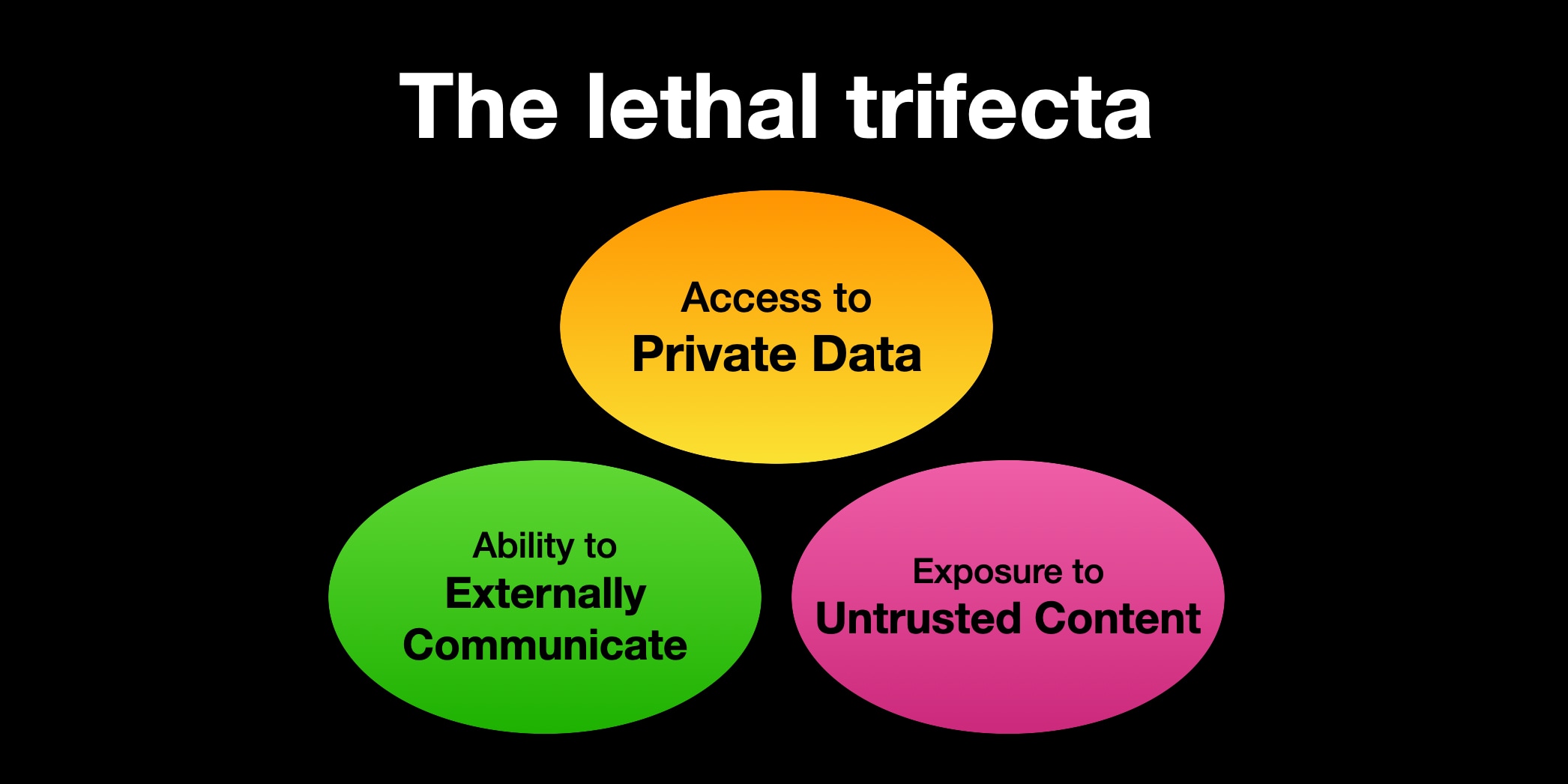
L’article Palo Alto Networks ajoute un “accélérant” : la mémoire persistante. Une attaque peut être “plantée” dans la mémoire et se déclencher plus tard (“time-shifted”, “memory poisoning”).

Prompt injection : directe, indirecte, et surtout… banale
L’OWASP décrit la prompt injection comme un cas où des entrées modifient le comportement du modèle de manière non voulue.

Dans OpenClaw, les sources d’entrées sont nombreuses : messages, web, sorties de skills, emails. Et la doc sécurité rappelle un point important : l’injection ne nécessite pas forcément un bot “public”. Il suffit d’une entrée non fiable qui passe dans le contexte de raisonnement.
De l’API Gateway à l’AI Gateway : l’enforcement point des agents
OpenClaw est puissant parce qu’il relie une conversation à des actions réelles : lire un mail, créer un ticket, ouvrir une PR, exécuter un outil. Et c’est exactement pour ça qu’il faut le traiter comme une surface d’attaque. Dans un monde agentique, l’attaque la plus simple n’est pas “d’entrer” : c’est d’influencer — via un mail, un document, un log, un commentaire. Une entrée non fiable peut se glisser dans le contexte, orienter la décision, puis se matérialiser en action.
La bonne nouvelle, c’est qu’un nouveau “layer” de sécurité est en train d’émerger : l’équivalent, pour les agents, de ce que l’API Gateway et le WAF ont été pour les APIs et le web. On le voit apparaître sous plusieurs noms — AI Gateway, LLM firewall, ou plus largement runtime security
Concrètement, ce layer ne “corrige pas le modèle” : il gouverne l’exécution. Il impose des politiques sur les tool calls (allowlist, scopes, moindre privilège), protège les secrets, détecte et bloque certaines classes de prompt injection, force une validation humaine sur les actions irréversibles (merge, déploiement, envoi), et produit de la traçabilité exploitable (logs, preuves, audit).
Le futur, ce n’est pas “pas d’agents”. C’est des agents gouvernés : profiter de la puissance d’OpenClaw, tout en mettant des garde-fous là où ça compte — au moment où le texte devient pouvoir.







{kind=link}