
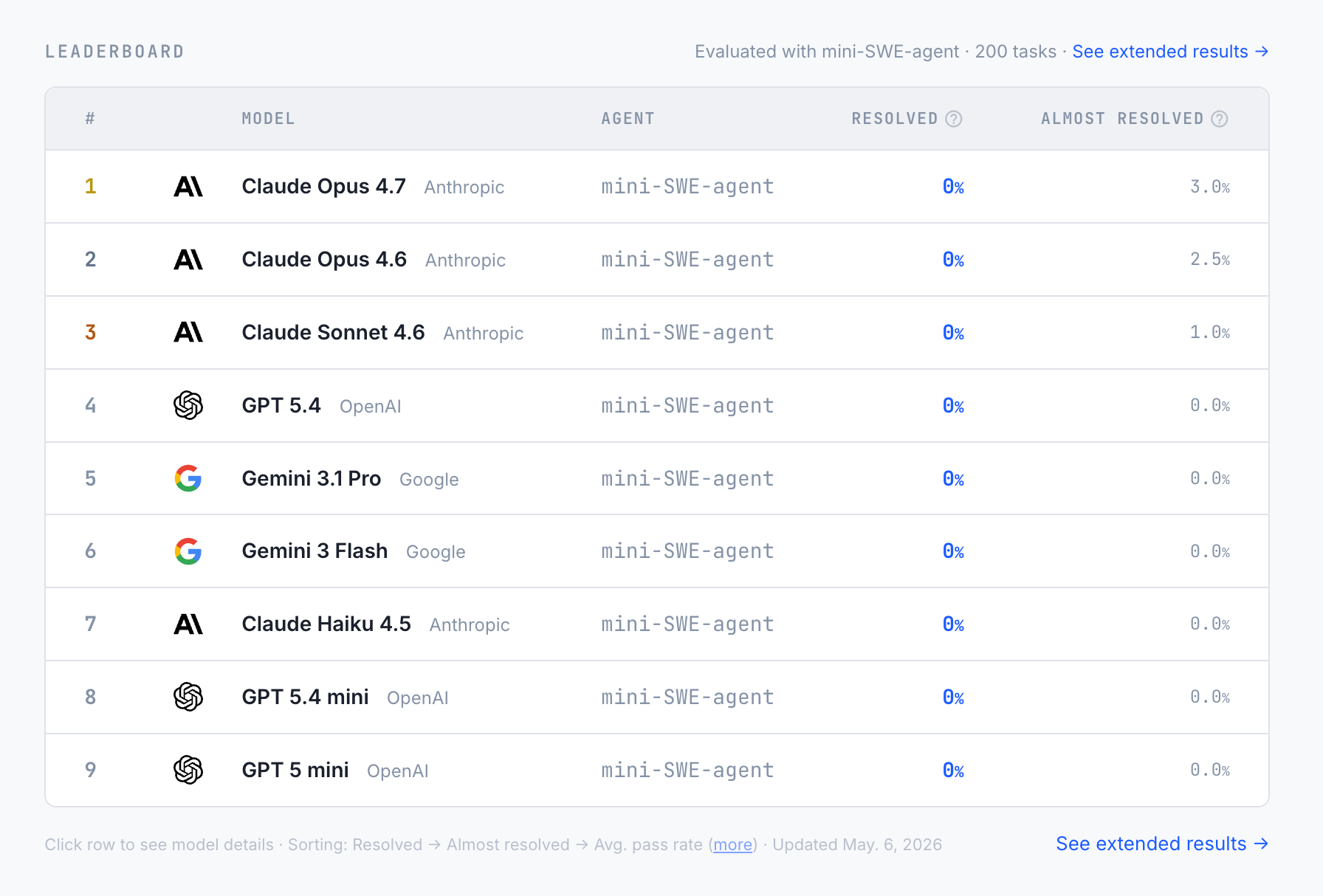
ProgramBench est le nouveau benchmark sorti le 5 mai 2026 par les équipes de Meta Superintelligence Labs, Stanford et Harvard (les mêmes auteurs que SWE-bench et SWE-agent). Sa proposition tient en une phrase : à partir du seul binaire et de sa documentation, reconstruire une codebase complète qui en reproduit le comportement. Pas de code source, pas de squelette, pas de signature à compléter, pas d'accès internet. Et le résultat fait du bruit : aucun modèle 2026 ne résout entièrement une seule des 200 tâches.
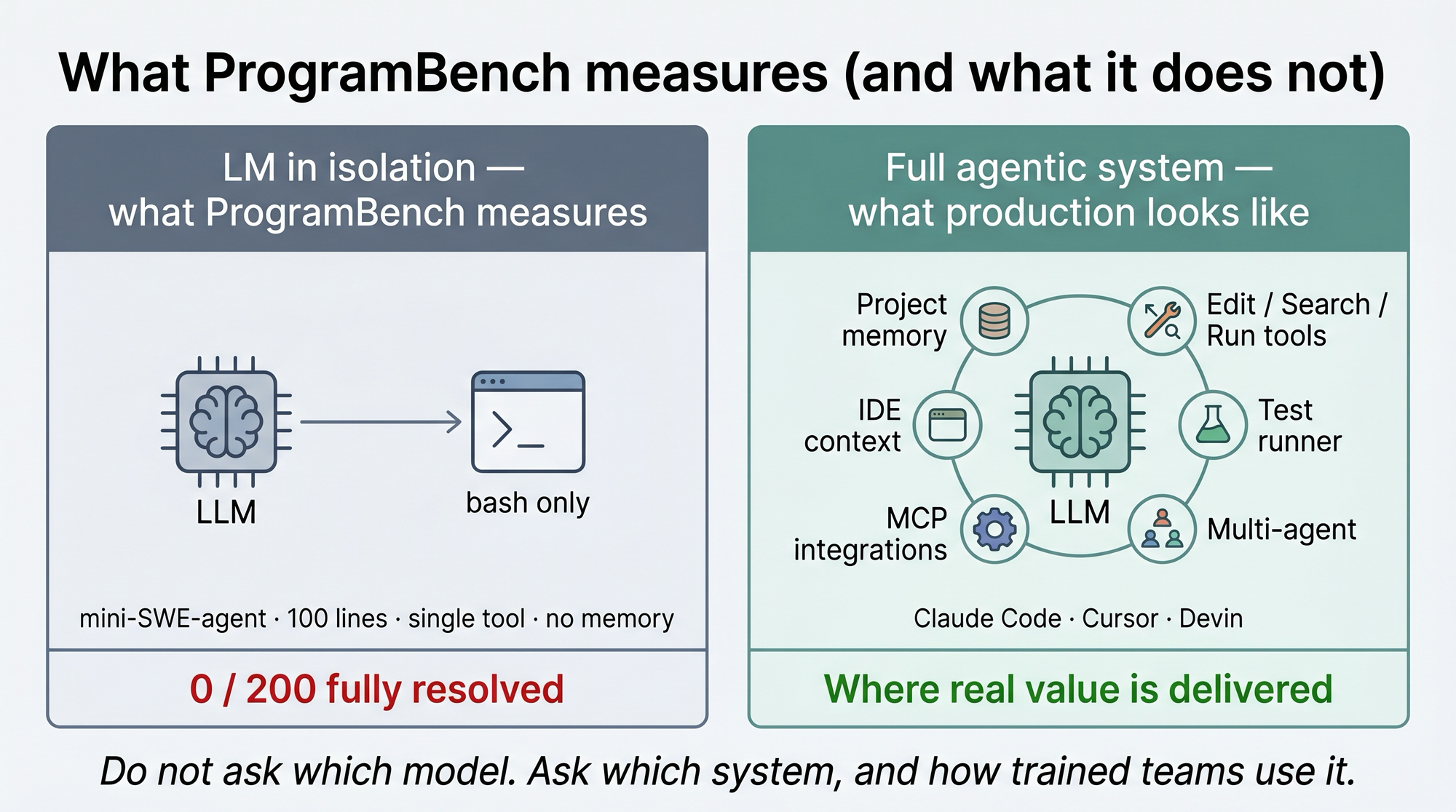
Avant de tirer la conclusion « les agents codeurs sont morts », il faut comprendre ce que ce 0 sur 200 mesure réellement : les modèles de langage en isolation, pas les systèmes complets type Claude Code, Cursor ou Devin que vous utilisez au quotidien. La nuance change tout.
Ce que ProgramBench mesure (et pourquoi c'est nouveau)
Les benchmarks de génie logiciel actuels (SWE-bench, HumanEval, MBPP, LiveCodeBench) mesurent tous des tâches focales et bornées : un bug à corriger, une fonction à compléter, un squelette à remplir. Cela reflète une partie réelle du travail d'un développeur, mais pas la plus exigeante : architecter un système de zéro.
ProgramBench inverse le cadre. L'agent reçoit :
- un binaire exécutable (permissions execute-only, pas de lecture, donc exit
objdump,strings,hexdump, décompilateurs) - la documentation du programme
- une sandbox sans accès internet (pas de clonage du repo source, pas de download via package manager)
Et doit produire un codebase complet, dans le langage de son choix, dont les sorties correspondent au binaire de référence sur 248 000 tests comportementaux générés par fuzzing (médiane : 770 tests par tâche).
Les 200 instances couvrent un spectre large : ripgrep, fzf, jq, FFmpeg, SQLite, DuckDB, PHP, LuaJIT, QuickJS, samtools, GROMACS… De l'utilitaire CLI de 200 lignes au compilateur monumental.
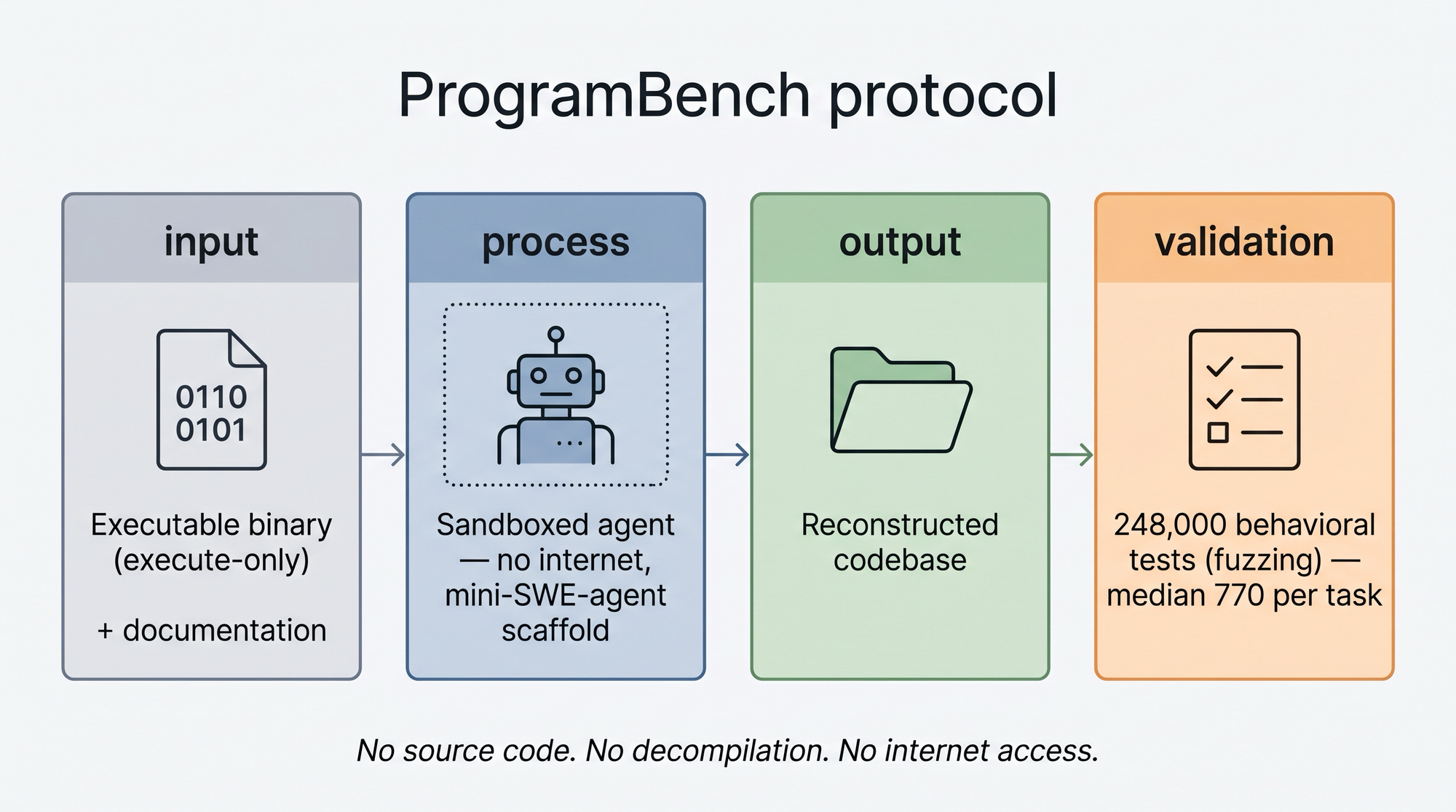
Point méthodologique important : le constat execute-only implique que ProgramBench teste uniquement des programmes exécutables. Les vraies bibliothèques API-only (style libcurl, libpng, un crate Rust sans CLI) sont absentes. Ce qui se mesure ici, c'est la synthèse de programmes, pas la synthèse de SDK.
Le scaffold imposé : la variable cachée du benchmarking d'agents
Avant les chiffres, il faut comprendre une mécanique cruciale et trop souvent passée sous silence : le scaffold.
Un scaffold, c'est toute la tuyauterie qui transforme un LLM en agent : boucle de contrôle, inventaire d'outils, parseur de réponse, exécuteur, gestion du contexte, prompts système, mémoire, politique d'arrêt. Le modèle pense, le scaffold agit.
Le spectre est immense :
- Minimal :
mini-SWE-agent, ~100 lignes Python, un seul outilbash. - Outillé classique : SWE-agent v1, OpenHands, Aider, avec outils dédiés, prompts spécialisés, milliers de lignes.
- Production lourde : Claude Code, Cursor, Devin, avec centaines de milliers de lignes, multi-agent, mémoires vectorielles, MCP, télémétrie.
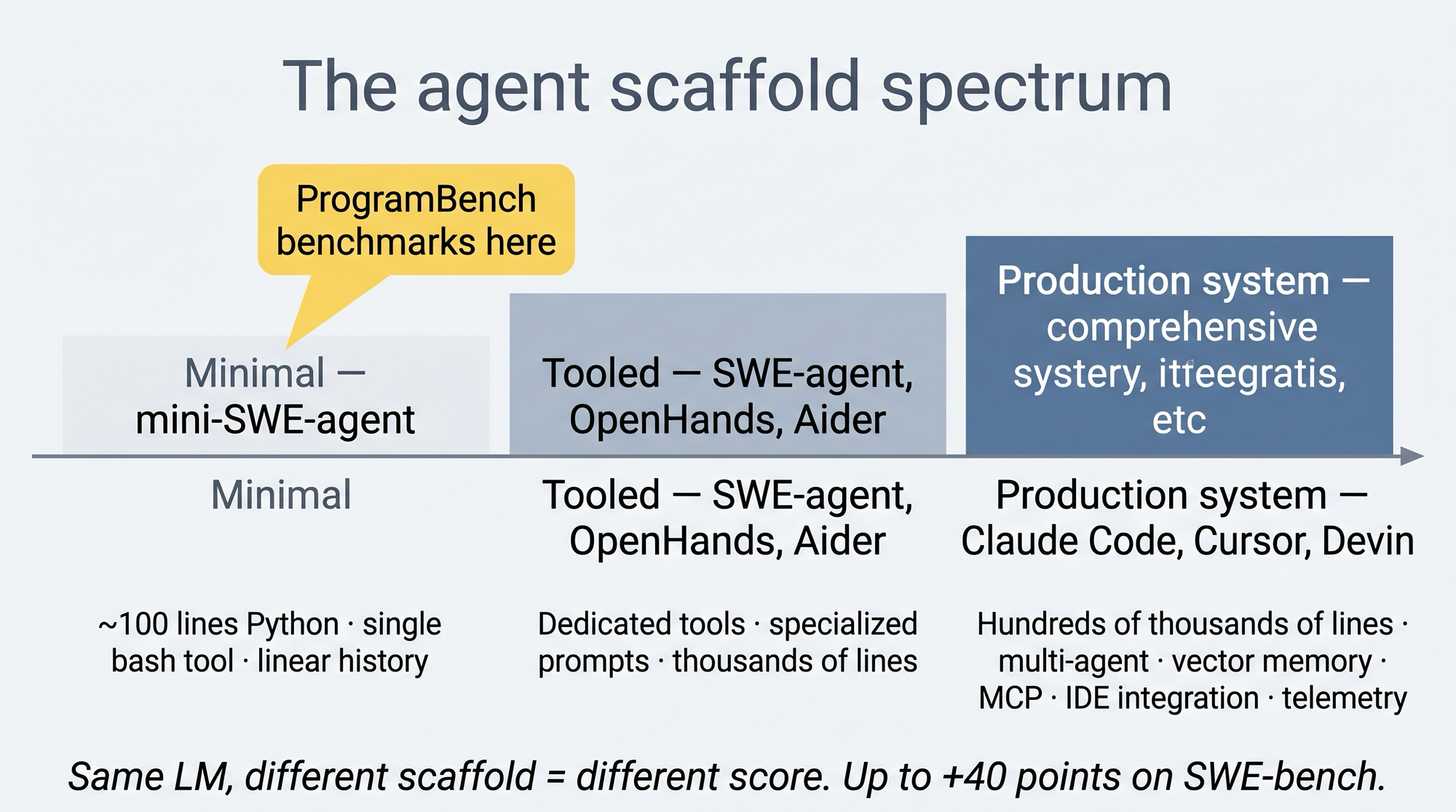
Pourquoi c'est critique ? Un même modèle peut passer de 30 % à 70 % sur SWE-bench selon le scaffold. Sans scaffold figé, comparer « Opus 4.7 + Claude Code » à « GPT 5.4 + mini-SWE-agent » ne compare pas deux modèles, mais deux systèmes.
ProgramBench impose donc mini-SWE-agent comme scaffold unique pour tous les modèles évalués. Choix radical et défendable :
- Apples-to-apples : impossible de cacher la performance d'un modèle derrière un scaffold sur-tuné.
- Sandboxing trivial :
subprocess.rundevientdocker exec, le harnais est reproductible. - Stabilité :
mini-SWE-agentne change pas tous les mois, contrairement aux IDE agentiques. - Anti-course aux scaffolds : empêche les éditeurs de gonfler leurs scores par du harness tuning.
Conséquence directe : ProgramBench est un benchmark de modèles de langage, pas de systèmes agentiques complets. Le 0 sur 200 décrit ce que Claude Opus 4.7 sait faire avec un agent à 100 lignes de Python autour, pas ce que vous obtenez avec Claude Code, Cursor ou un harnais maison sur-tuné.
Les trois insights majeurs sur les LM
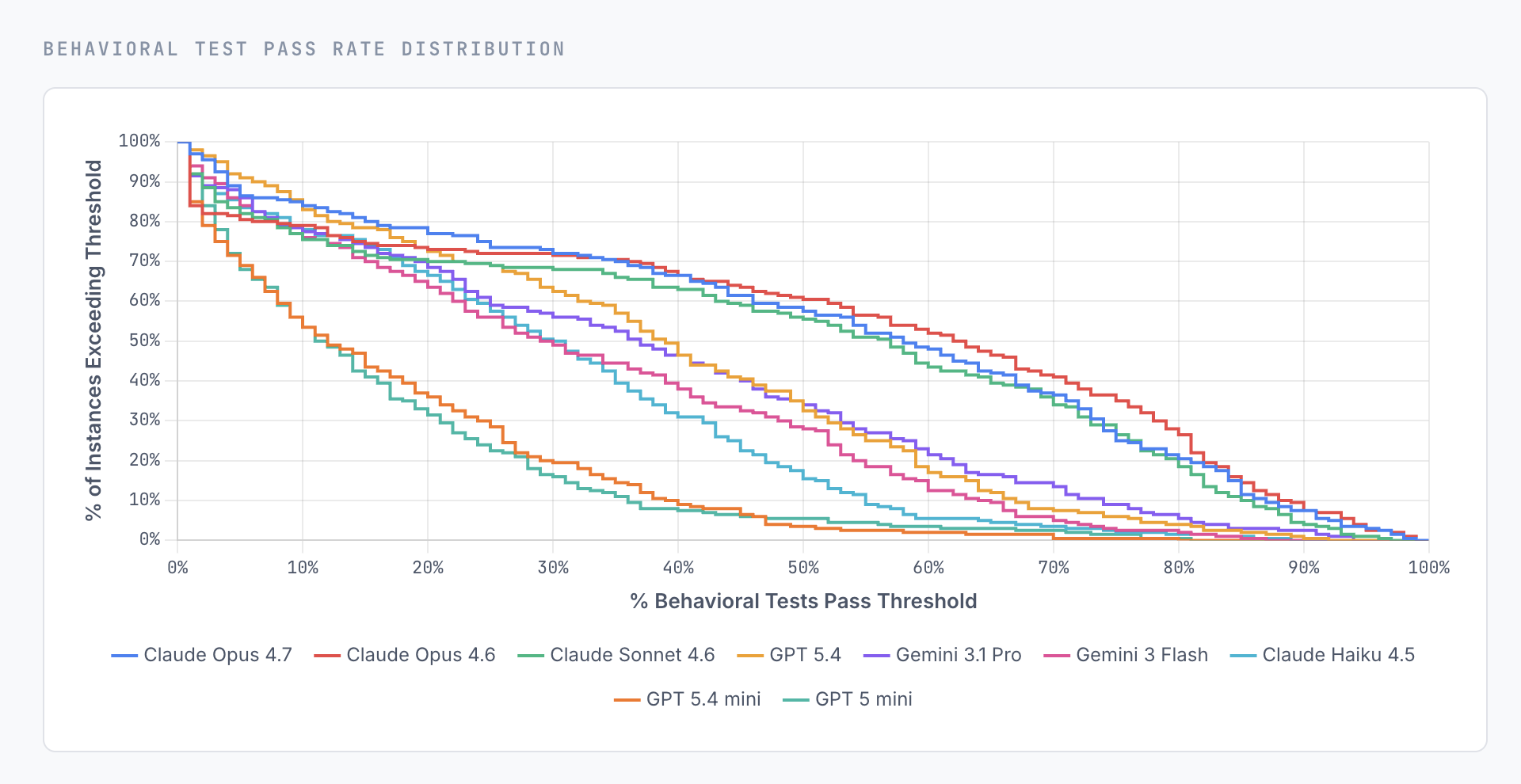
1. Le benchmark n'est pas saturé, pas du tout
- 0 % des tâches sont totalement résolues par le meilleur modèle (Claude Opus 4.7).
- 3 % des tâches atteignent ≥ 95 % de tests passés pour Opus 4.7, 2,5 % pour Opus 4.6, 1 % pour Sonnet 4.6, 0 % pour tous les modèles OpenAI et Google évalués.
- Pas d'effet de budget : les runs Sonnet 4.5 atteignent jusqu'à 5 000 $ d'inférence, sans cap. Les modèles ne saturent ni le contexte ni les step-limits.
La limite est donc cognitive, pas opérationnelle.
2. Le pattern dominant est le monolithique single-file
C'est le déficit central pointé par les auteurs. Les agents produisent du code monolithique, dans un fichier unique, structurellement très éloigné des implémentations humaines. Ils savent écrire des fonctions, mais pas décomposer un système : séparer les concerns, exposer des interfaces propres, organiser un build, modulariser.
C'est précisément la compétence que le benchmark visait à isoler, et c'est exactement celle qui manque au niveau du LM brut.
3. La mémorisation n'explique pas les scores
Les 200 tâches sont issues de dépôts open-source visibles dans les corpus d'entraînement. Soupçon évident : les modèles régurgitent-ils du code mémorisé ?
L'ablation « langage différent » répond : forcer une réimplémentation dans un langage autre que celui d'origine laisse les scores quasi inchangés. La mémorisation littérale n'est donc pas le moteur des résultats. Ce que les scores reflètent est bien une capacité d'ingénierie.
Ce que ProgramBench ne dit pas
Trois choses que ce benchmark ne mesure pas, et qu'il faut garder en tête avant d'en faire un argument anti-agent :
1. La performance réelle d'un système complet. Claude Code, Cursor ou Devin ajoutent au LM une mémoire de projet, un graphe de fichiers, des outils spécialisés (edit, search, run, test, refacto), des prompts système éprouvés, du multi-agent, des intégrations IDE. Sur des tâches de bug fix ou de refacto, les scores grimpent significativement par rapport à un scaffold minimal. ProgramBench ne mesure pas cette amélioration : c'est volontaire, pour isoler le LM.
2. La capacité à itérer avec un humain dans la boucle. Le protocole est one-shot agentique : l'agent travaille seul jusqu'à soumettre. Or l'usage réel d'un agent codeur en 2026, c'est une collaboration courte boucle avec un développeur qui cadre l'architecture, valide les choix, recadre les dérives. Ce mode-là n'est pas testé.
3. La valeur produite sur les tâches assistance. Les agents codeurs créent aujourd'hui une valeur démontrable sur la génération de tests, la documentation, la migration, le refacto local, l'explication de code, la review. ProgramBench ne mesure rien de tout cela.
Ce qu'on en retient pour la production
Trois enseignements actionnables.
Le LM brut a un vrai déficit d'architecture. Le 0 sur 200 est réel et il faut le prendre au sérieux. Pour les tâches « build-from-scratch holistique », aucun modèle 2026 ne livre un codebase exploitable sans intervention humaine de design. La promesse « l'IA va générer votre plateforme » reste prématurée.
Le système complet est le bon niveau de débat. Quand un fournisseur ou un client vous parle d'agents codeurs, la question pertinente n'est pas « quel LM ? » mais « quel système, avec quel scaffold, et utilisé comment ? ». Le même modèle dans deux systèmes différents produit deux résultats différents.
La formation au bon usage est le multiplicateur. Le vrai levier de valeur 2026 n'est pas de basculer d'un LM à un autre, c'est de former les équipes à utiliser la puissance complète du système agentique : maîtrise des outils, structuration de la mémoire projet, écriture de skills et de prompts système, découpage des tâches, posture de pair-programming. La compétence à acquérir est celle d'architecte de workflows agentiques, pas de simple consommateur de LLM.
Pour aller plus loin
- Paper arXiv, ProgramBench: Can Language Models Rebuild Programs From Scratch?
- Leaderboard officiel, programbench.com
- Repository GitHub, facebookresearch/ProgramBench
- mini-SWE-agent, le scaffold de référence
ProgramBench n'est pas un gotcha contre les agents. C'est une mesure honnête de la capacité d'un LM seul à architecter, distincte de sa capacité à coder. La distinction compte. Elle ne disqualifie pas les agents codeurs en production : elle indique simplement où porter l'investissement (système complet, formation, méthode) plutôt que de courir après le prochain modèle.






){kind=link}