
Si vous avez déjà travaillé sur une application utilisant Hibernate, vous avez probablement déjà rencontré le problème de duplication d’entités. Lorsque que vous récupérez une collection d’entités, vous vous retrouvez avec un ensemble comprenant des doublons de la même instance.
C’est une problématique plutôt connue et il existe plusieurs moyens pour le résoudre, que cela soit par l’utilisation du mot-clé DISTINCT, la collection Set ou encore les EntityGraph de JPA. Cependant, il m’est arrivé d’avoir un comportement étrange avec les EntityGraph, celui-ci retournant des entités dupliquées ! Je vous propose ici de plonger sous les entrailles d’Hibernate 5 pour comprendre tout les tenants et aboutissant de ce comportement.
Une petite application Spring Boot
Pour démontrer ce comportement, prenons un simple projet en exemple, à savoir Spring Boot 2.7 connecté à une base de données : https://github.com/Shaolans/HibernateEntityGraphDeduplicationIssue
Le schéma de la base de données est un modèle simple :
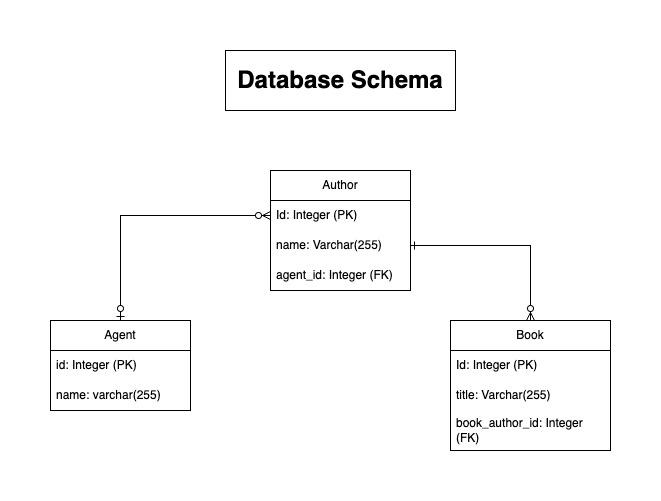
Les entités Hibernate sont définies comme suit :
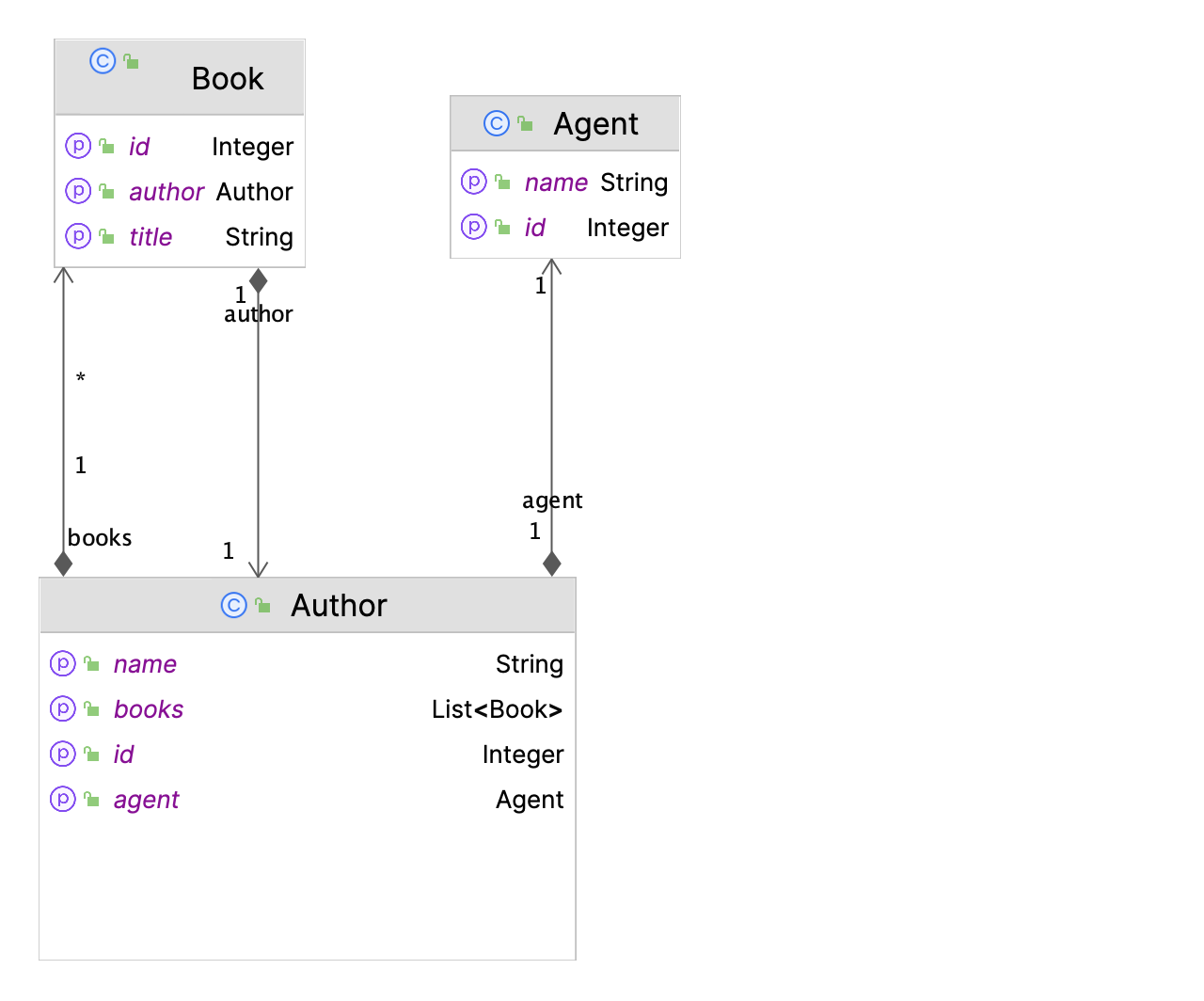
Nous allons nous concentrer sur les requêtes générées par ce référentiel JPA :
@Repository
public interface AuthorRepository extends JpaRepository<Author, Integer> {
@Query("SELECT a FROM Author a LEFT JOIN FETCH a.books")
List<Author> findAuthorsLeftJoinFetchNoEntityGraph();
@EntityGraph(attributePaths = "books")
@Query("FROM Author a LEFT JOIN a.books")
List<Author> findAuthorsLeftJoinWithEntityGraph();
@Query("FROM Author a LEFT JOIN a.books")
List<Author> findAuthorsLeftJoinWithoutEntityGraph();
@EntityGraph(attributePaths = "books")
@Query("FROM Author a INNER JOIN a.agent WHERE a.agent.name like '%John%'")
List<Author> findAuthorsWithJoinNotFetchedAndEntityGraph();
@EntityGraph(attributePaths = "books")
@Query("SELECT a FROM Author a INNER JOIN a.agent WHERE a.agent.name like '%John%'")
List<Author> findAuthorsWithJoinNotFetchedAndEntityGraphAndSelect();
}
Duplication d'entités
Origine
Pour comprendre pourquoi la duplication d'entités se produit, considérons un cas d'utilisation où nous souhaitons récupérer tous les auteurs et leurs livres. Afin d'éviter le problème de requête N+1, ajoutons dans la requête JPQL le mot-clé FETCH. Cela permet la récupération à la fois des auteurs et de leurs livres associés dans une seule requête SQL, éliminant ainsi la nécessité de récupérer individuellement les livres pour chaque auteur.
@Query("SELECT a FROM Author a LEFT JOIN FETCH a.books")
List<Author> findAuthorsLeftJoinFetchNoEntityGraph();L'invocation de cette méthode produit à la compilation d'une requête SQL équivalente à la suivante :
SELECT A, B FROM AUTHOR A LEFT JOIN BOOK B ON A.ID = B.BOOK_AUTHOR_ID;Dans le cas où vous avez 2 auteurs ayant respectivement 2 et 3 livres, le résultat de la requête SQL produira par exemple le tableau suivant :
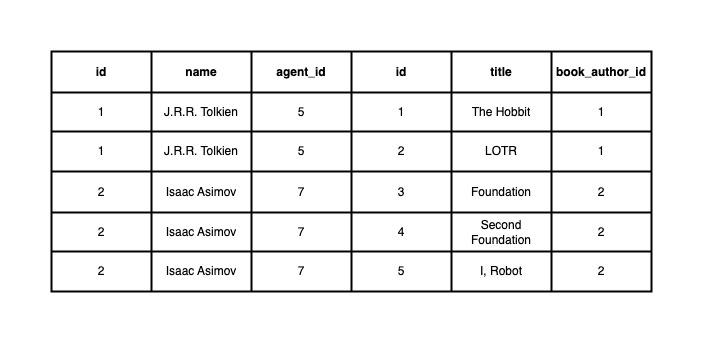
En fonction du type de jointure, l'association entre les tables Author et Book est établie en fonction de la condition spécifiée (ici la clé primaire de Author). Cela produira, pour chaque livre correspondant à un auteur, une nouvelle ligne contenant les colonnes de la table Book ainsi que les colonnes de la table Author.
Hibernate, lorsqu'il récupère cet ensemble de résultats, est assez intelligent pour résoudre l'entité elle-même sans la dupliquer (il n’existe qu’une seule instance pour une entité). Dans notre cas, nous obtenons seulement deux instances de l'entité Author. Cependant, il gère la résolution ligne par ligne et ne dé-duplique pas ces lignes par défaut.
Cela explique pourquoi la liste retournée en appelant findAuthorsLeftJoinFetchNoEntityGraph renvoie ce qui suit :
[Author@5640, Author@5640, Author@5641, Author@5641, Author@5641]Author@5640 étant l'instance représentant l'entité Author de J.R.R Tolkien et Author@5641 représentant l’entité Author Isaac Asimov.
Cette duplication est principalement observée dans les relations @OneToMany et @ManyToMany, car la jointure produite par ces types relations peut correspondre à plusieurs lignes de la table associée. En revanche, les relations @OneToOne et @ManyToOne correspondent au plus à une seule entrée dans la table associée et ne provoquent pas de duplication.
Solutions
Bien que ce problème de duplication soit assez courant et se produit souvent lors du développement d'applications, il existe des moyens de résoudre ce problème.
Set
Une solution simple consiste à utiliser le type de retour Set<Author> au lieu de List<Author> :
@Query("FROM Author a LEFT JOIN FETCH a.books")
Set<Author> findAuthorsLeftJoinFetchNoEntityGraph();Lorsque les résultats sont collectés, les entités dupliquées seront filtrées à travers le Set.
mot-clé DISTINCT
Une autre approche consiste à utiliser le mot-clé DISTINCT :
@Query("SELECT DISTINCT a FROM Author a LEFT JOIN FETCH a.books")
List<Author> findAuthorsLeftJoinFetchNoEntityGraph();Il convient de noter que l'utilisation de DISTINCT a deux significations sémantiques :
- SQL : La signification SQL conventionnelle implique le filtrage des valeurs en double dans les colonnes sélectionnées.
- Hibernate : Cela indique le besoin de filtrer les duplications dans l'entité parente.
Lorsque le mot-clé DISTINCT est utilisé dans une requête JPQL, cela entraîne la génération d'une requête SQL qui inclut le mot-clé DISTINCT et indique également à Hibernate de filtrer les entités dupliquées. Cependant, l'utilisation de DISTINCT en SQL entraîne un certain coût lors de son exécution au niveau de la base de données. Dans certains cas, l'objectif est de filtrer uniquement les entités dupliquées induites par les jointures.
Pour de tels cas, nous pouvons utiliser le paramètre d’Hibernate HINT_PASS_DISTINCT_THROUGH et éviter la génération de DISTINCT dans la requête SQL :
@QueryHints(@QueryHint(name = HINT_PASS_DISTINCT_THROUGH, value = "false"))
@Query("SELECT DISTINCT a FROM Author a LEFT JOIN FETCH a.books")
Set<Author> findDistinctAuthorsLeftJoinFetchNoEntityGraph();EntityGraph
Depuis JPA 2.1, EntityGraph est une fonctionnalité qui a été introduite et permettant aux développeurs de définir les stratégies de chargement des entités. Dans notre cas, nous pouvons spécifier facilement avec l'annotation @EntityGraph le chargement des livres en même temps que les auteurs, comme illustré ci-dessous :
@EntityGraph(attributePaths = "books")
@Query("FROM Author a LEFT JOIN a.books WHERE a.books.size > 2")
List<Author> findAuthorsLeftJoinWithEntityGraph();Cette requête JPQL est conçue pour récupérer tous les auteurs (ainsi que leurs livres respectifs) qui ont plus de 2 livres. Même si nous n'avons pas ajouté explicitement le mot-clé FETCH dans la requête SQL, grâce à l'EntityGraph, les livres seront chargés et l'entité parente Author ne sera pas dupliquée.
Note : Ceci est un exemple simple d'utilisation d'EntityGraph. Il existe des façons plus complètes et sophistiquées de l'utiliser, mais ce n'est pas le but de cet article.
EntityGraph et la duplication d’entités
Bien qu'il soit établi que les EntityGraph gère la déduplication des entités, examinons un scénario plus complexe.
Considérons l'entité Author, qui a une relation ManyToOne avec l’entité Agent. Supposons que nous voulons récupérer tous les auteurs et leurs livres dont leur agent a un nom contenant "John", mais que pour une raison arbitraire nous n’avons pas besoin d’exploiter dans notre code l’entité Agent, il est donc inutile de le récupérer. Dans ce cas, nous pouvons accomplir cela avec le code suivant :
@EntityGraph(attributePaths = "books")
@Query("FROM Author a INNER JOIN a.agent WHERE a.agent.name like '%John%'")
List<Author> findAuthorsWithJoinNotFetchedAndEntityGraph();Étant donné l’utilisation d'EntityGraph, nous ne devrions pas avoir d’entités dupliquées, mais lors de l'exécution de la méthode, le résultat est inattendu :

Des entités dupliquées sont récupérées de manière inattendue malgré l'utilisation d'EntityGraph. Pour comprendre les raisons de ce comportement, explorons un peu le code d'Hibernate.
Comment Hibernate déduplique les entités
Hibernate est un ORM assez complet et complexe, il peut être difficile de comprendre entièrement tous ses mécanismes sous-jacents dans les moindre détails. Cependant dans notre cas, puisque nous voulons comprendre les mécanismes de déduplication, nous nous concentrerons sur la méthode list de la classe QueryTranslatorImpl.
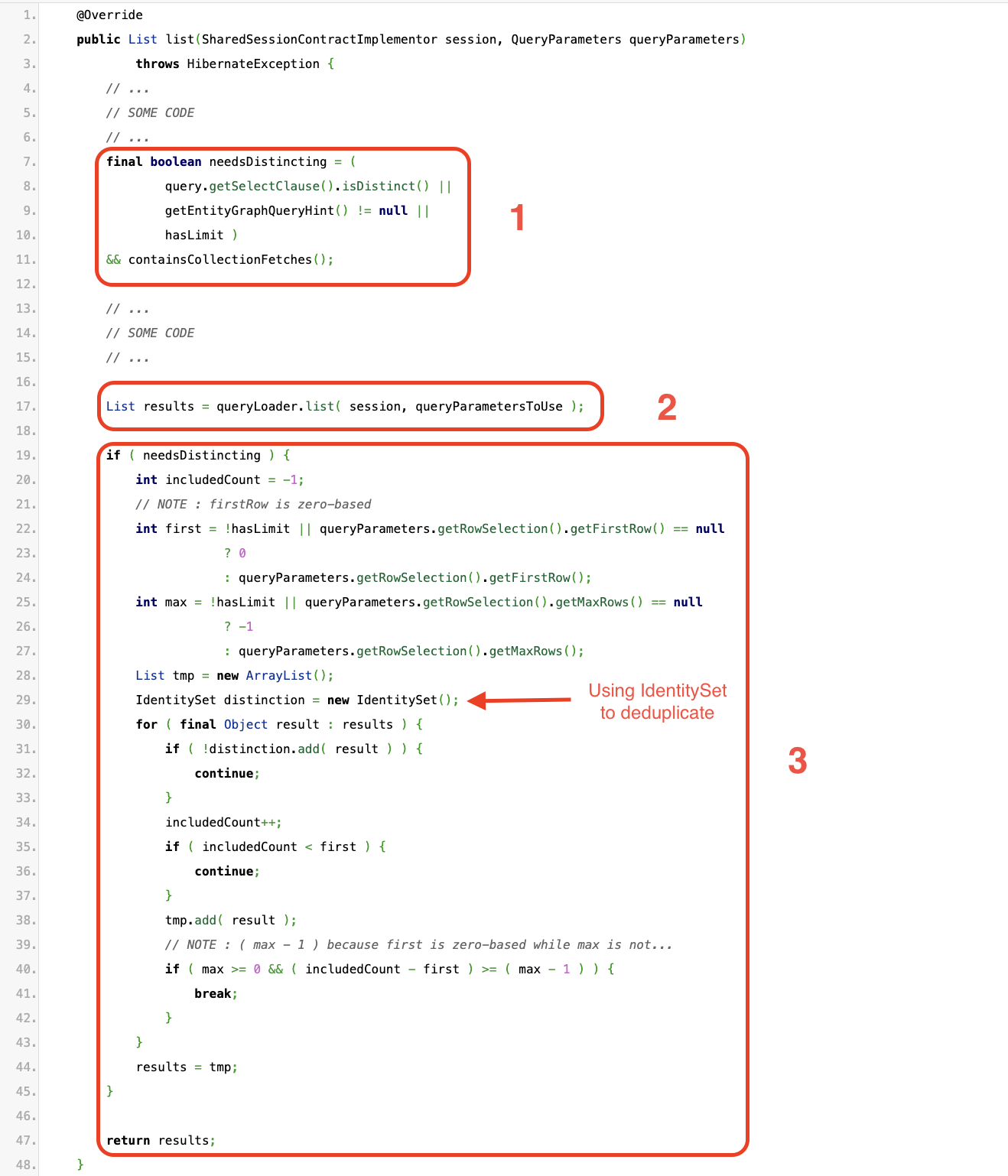
Pour des raisons de clarté, certaines parties du code ont été omises afin de se concentrer sur les points les plus importants.
Lors de l'invocation d'une méthode de la classe AuthorRepository, l'exécution finira éventuellement par arriver à cet extrait de code, et voici une analyse de la fonctionnalité :
- Ce snippet calcule un booléen appelé
needsDistinctinget comme son nom l'indique, il identifiera si l'ensemble de résultats doit être dédupliqué.
Lorsque nous utilisons le mot-cléDISTINCT, un EntityGraph ou limitons la taille de la récupération ET qu'il y a une opérationFETCHdans la requête JPQL, la distinction (déduplication) doit être appliquée.
Nous pouvons observer que chaque fois qu’EntityGraph est utilisé, la distinction doit être appliquée, car celui-ci modifie la requête source pour récupérer (FETCH) les entités qui ont été fournies dans@EntityGraph. - L'invocation de cette méthode exécutera la requête dans la base de données, récupérera l'ensemble de résultats et résoudra les entités. Cette liste pourrait renvoyer des entités dupliquées.
- C'est la partie la plus intéressante : lorsque Hibernate doit distinguer/dédupliquer les entités, celui-ci utilise un
IdentitySetpour filtrer les entités. Il s'agit d'une implémentation deSetqui utilise l'égalité référentielle (==) plutôt queequals.
À ce stade, nous avons établi que l'utilisation d'EntityGraph devrait filtrer les entités dupliquées, mais que s'est-il passé pour causer le comportement précédemment démontré ?
Comment EntityGraph peut-il retourner duplicats d’entités ?
Comparons
Afin de mieux comprendre la situation, comparons les résultats de l'appel de queryLoader.list( session, queryParametersToUse ) (2) lors de l'invocation des méthodes suivantes :
@EntityGraph(attributePaths = "books")
@Query("FROM Author a LEFT JOIN a.books")
List<Author> findAuthorsLeftJoinWithEntityGraph();et
@EntityGraph(attributePaths = "books")
@Query("FROM Author a INNER JOIN a.agent WHERE a.agent.name like '%John%'")
List<Author> findAuthorsWithJoinNotFetchedAndEntityGraph();Lors de l’appel à la méthode findAuthorsLeftJoinWithEntityGraph, les résultats retournés contiennent :
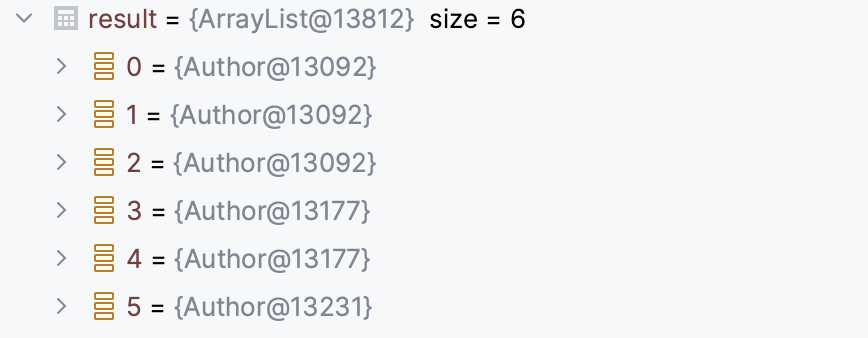
Étant donné que l'EntityGraph est utilisé, la duplication sera résolue grâce à l'IdentitySet. Dans une finalité la méthode renverra une liste List<Author> composée de 3 auteurs/instances.
Cependant, lors de l'appel à findAuthorsWithJoinNotFetchedAndEntityGraph, les résultats retournés contiennent ce qui suit :
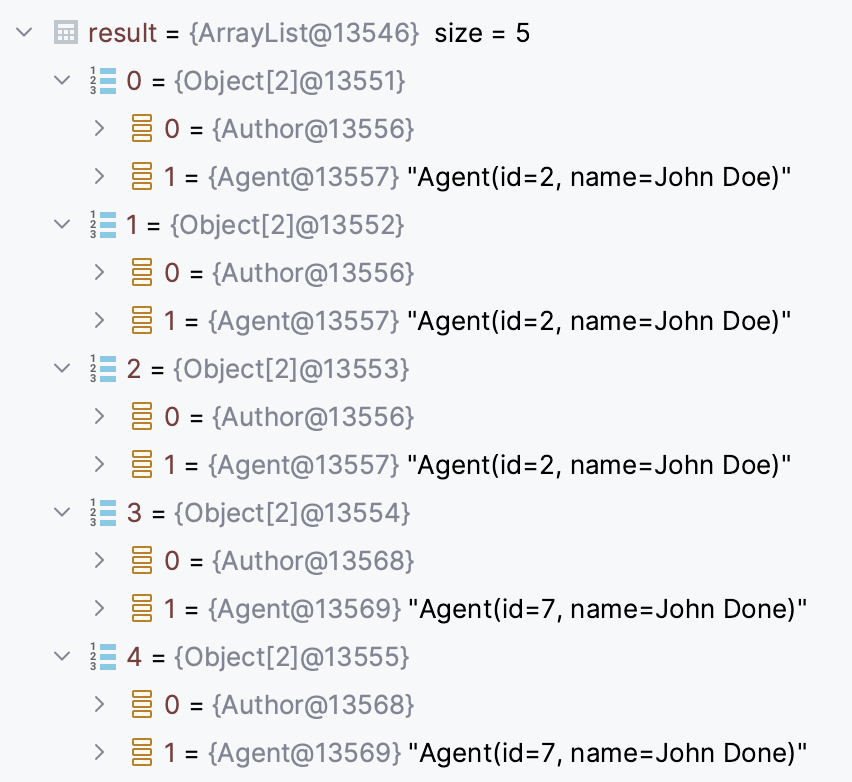
Dans ce scénario, le résultat n'est pas une liste d'instances Author, mais plutôt une liste d'instances distinctes de tableaux d'objets, chacune encapsulant des instances Author et Agent dupliquées. La raison de la présence d'entités dupliquées devient évidente. Chaque tableau (Object[2]@13551, Object[2]@135512, ..., Object[2]@13555), en tant qu'instance distincte, n'est pas filtré lors du processus de déduplication avec l'IdentitySet. Par conséquent, tous les tableaux sont considérés comme unique dans le Set, conduisant à la duplication observée.
La raison de cette différence
Afin de comprendre la différence entre l'obtention d'une liste d'instances Author dans le premier cas et d'une liste de tableaux d'instances Author et Agent dans le deuxième cas, nous devons explorer plus en profondeur. Jetons un coup d'œil à la classe QueryLoader et en particulier à la méthode initialize.
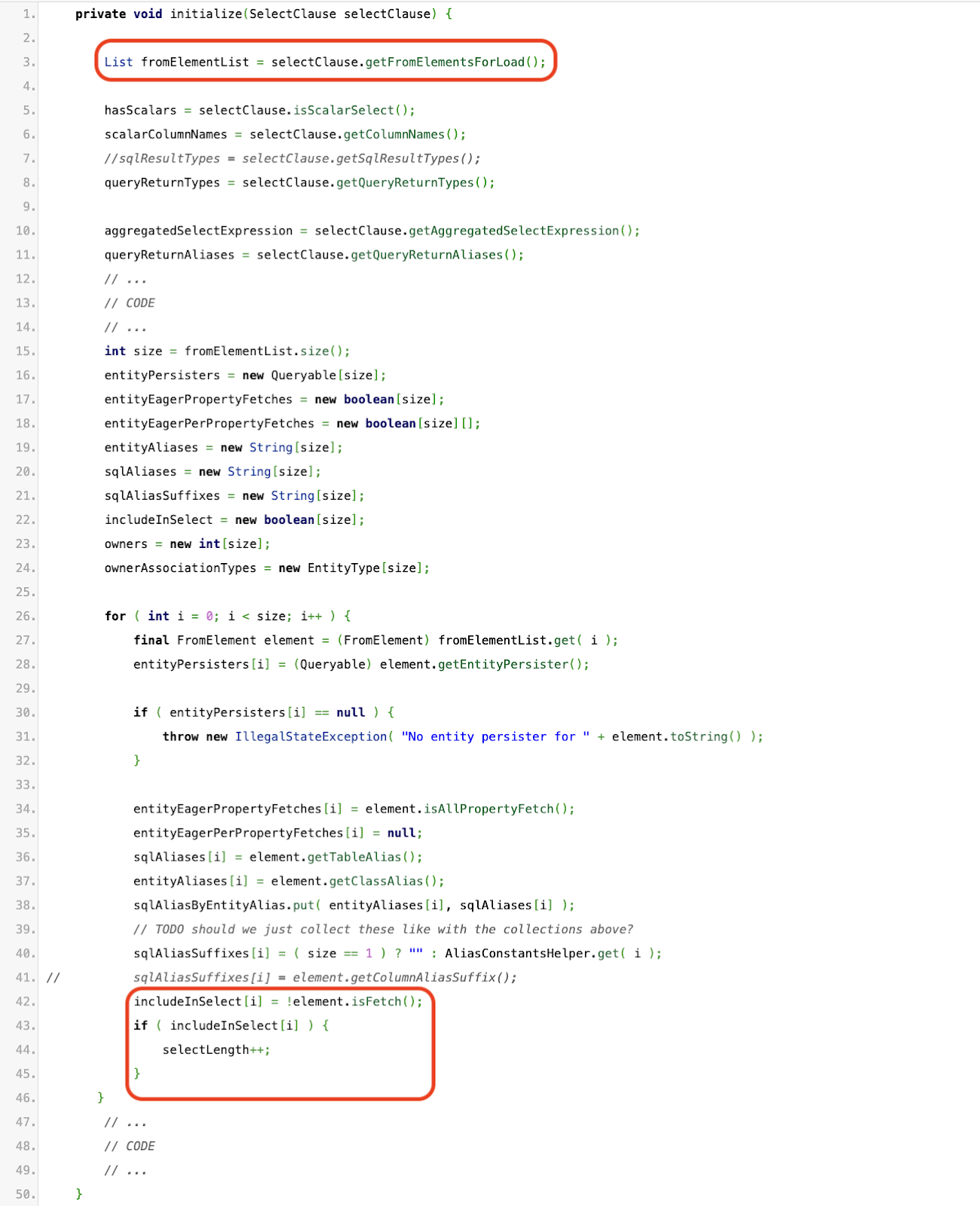
Ce code d'initialisation comporte des parties intéressantes, en particulier celle mise en surbrillance en rouge. Celui-ci crée un tableau de booléens includeInSelect où elle vérifie quelles entités doivent être sélectionnées et retournées.
Prenons l’exemple suivant :
@Query("SELECT a, b FROM Author a LEFT JOIN FETCH a.books b")Le code d’initialisation vérifie le contenu du SELECT un par un, qui est a et b dans cet exemple. Si l'entité sélectionnée provient d'une opération de FETCH dans la clause FROM, elle sera omise (false), car ce FETCH est utilisé pour charger les entités enfants (mais pas dans le cas de l'entité parente). Sinon, l'entité doit être sélectionnée et retournée.
Dans cet exemple le tableau includeInSelect retourne [true (Author), false (Book)].
Dans notre cas de duplication d'entités avec EntityGraph :
@EntityGraph(attributePaths = "books")
@Query("FROM Author a INNER JOIN a.agent WHERE a.agent.name like 'John'")
List<Author> findAuthorsWithJoinNotFetchedAndEntityGraph();Nous n'avons pas spécifié la clause SELECT, donc par défaut, elle sélectionne toutes les entités de toutes les tables spécifiées dans la clause FROM.

A la fin de l’initialisation, le tableau includeInSelect retourne un tableau [true (Author), false (Book), true (Agent)] où Author et Agent (2 éléments) devraient être sélectionnés, car seulement l’entité Book est soumise à une opération FETCH en raison de l'utilisation d'EntityGraph.
Cela explique la différence entre findAuthorsLeftJoinWithEntityGraph et findAuthorsWithJoinNotFetchedAndEntityGraph.
Le premier ne retourne qu'une valeur par ligne car la clause SELECT ne contenait que les entités Author et Book (le SELECT de Book a été intégré dans la même requête SQL par EntityGraph). Cependant, comme Book est soumis à une opération FETCH, il n'a pas été pris en compte dans le tableau includeInSelect et n'a donc pas été retourné dans la liste des résultats.
Le second retourne un tableau par ligne car Author et Agent étaient dans la clause SELECT et ne sont pas soumis à une opération FETCH. Ainsi, il retourne un tableau composé de 2 éléments par ligne.
En résumé, Hibernate retourne de manière consistante un tableau, et le contenu de ce tableau est déterminé par les entités spécifiées dans la clause SELECT qui ne sont pas associées à des opérations FETCH.
Cependant, si nous suivons la logique précédente, findAuthorsLeftJoinWithEntityGraph devrait également renvoyer un tableau, mais un tableau contenant un seul élément (Author). C'est exact, c'est le cas, cependant, en examinant l'implémentation à la ligne 476 et 620 de QueryLoader, lorsque le tableau ne contient qu'un seul élément, cet élément est simplement extrait du tableau et retourné.
Comment y remédier
Pour garantir le filtrage des entités dupliquées lors de l'application de la distinction, l'ensemble de résultats devrait être une liste d'entités plutôt qu'une liste de tableaux d'entités. Ce comportement est déterminé par les entités sélectionnées. Une solution simple consiste à inclure l’entité souhaitée explicitement dans la clause SELECT :
@EntityGraph(attributePaths = "books")
@Query("SELECT a FROM Author a INNER JOIN a.agent WHERE a.agent.name like '%John%'")
List<Author> findAuthorsWithJoinNotFetchedAndEntityGraph();La clause SELECT ne contiendra que les entités Author et Book (le SELECT de Book étant générée par l'EntityGraph) car Agent n'est plus une entité incluse dans le SELECT :
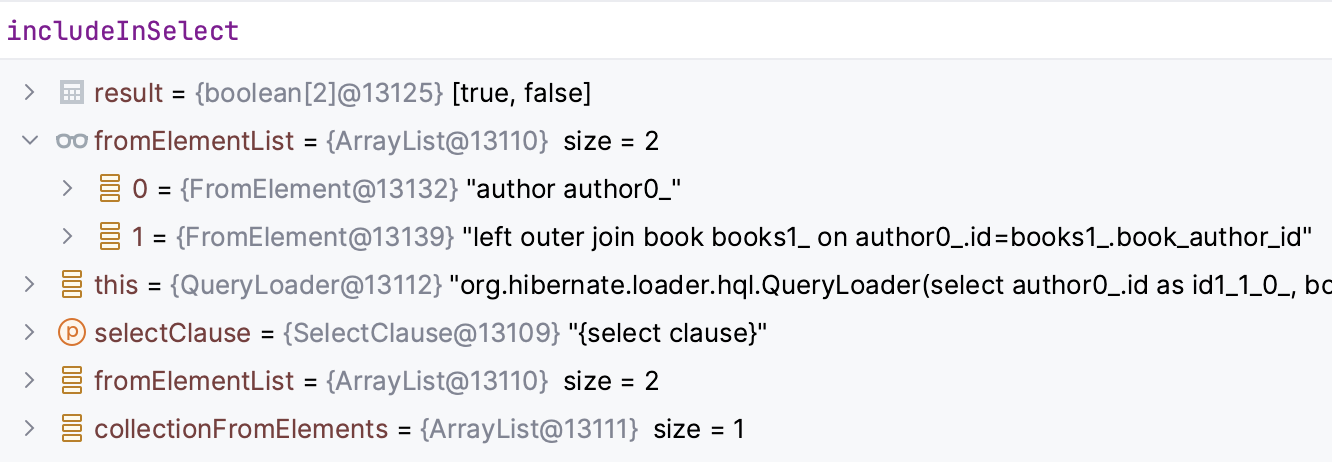
Etant donnée que Book est une opération FETCH, le tableau includeInSelect ne sélectionne qu'un élément (Author) et au lieu de renvoyer un tableau, il renverra directement l'instance Author qui passera ensuite par l'IdentitySet pour être dédupliquée.
Conclusion
La duplication d'entités se produit lorsque des tables sont jointes et que plusieurs lignes correspondent. Il existe plusieurs méthodes pour résoudre ce problème, notamment l'utilisation de Set, du mot-clé DISTINCT ou de l’EntityGraph pour dédupliquer les entités. Dans les deux derniers cas, la déduplication est réalisée grâce à un indicateur Hibernate qui accumule les résultats dans un IdentitySet.
Cependant, cette solution n’est pas infaillible en raison du fait qu’en fonction de la clause SELECT, cela pourrait renvoyer pour chaque ligne une nouvelle instance de tableau des entités sélectionnées. Cela pourrait compromettre la déduplication par le biais de l'IdentitySet.
Il est donc conseillé, lors de l'écriture de requêtes JPQL, de toujours spécifier la clause SELECT. Si elle n'est pas fournie, toutes les entités de la clause FROM qui ne sont pas soumises à une opération FETCH seront sélectionnées par défaut provoquant de potentiel duplication.
Le problème des entités dupliquées est résolu dans Hibernate 6 (livré dans Spring Boot 3), car celui-ci introduit une meilleure gestion et automatique des entités dupliquées. Cependant, la sortie d’Hibernate 6 est relativement récente, de nombreuses applications fonctionnent toujours avec Hibernate 5 ou des versions antérieures. Concernant la migration d’Hibernate 5 à 6, celle-ci peut s'avérer périlleuse et complexe. Ainsi, la compréhension de la manière dont Hibernate 5 gère ces situations reste pertinente pour le nombre considérable d'applications qui l'exploitent toujours.








{kind=link}