
Dans le domaine de l’ingénierie des données, les pipelines modernes comprennent généralement plusieurs étapes interdépendantes : extraction, transformation et chargement des données (ETL). La gestion efficace de ces étapes devient de plus en plus complexe, notamment à cause de la diversité des sources de données et de l'intégration nécessaire avec des outils tiers comme Airbyte pour l'extraction et dbt pour la transformation.
Cet article présente une approche d'automatisation des pipelines en utilisant Dagster, Airbyte et dbt pour organiser le flux de travail de manière séquentielle et coordonnée. Cette méthode permet de réduire les délais d’exécution, d'éliminer les retards de chargement et de résoudre les problèmes de synchronisation liés à l'API Airbyte. Nous aborderons également certaines limitations et proposerons des solutions de contournement pour optimiser davantage le processus.
ERROR
Request to Airbyte API failed: HTTPConnectionPool(host=<airbyte_host>, port=8000): Read timed out. (read timeout=15)
STEP_FAILURE
dagster._core.definitions.events.Failure: Max retries (3) exceeded with url: http://<airbyte_host>/api/v1/jobs/cancel.Erreur de timeout et échec des requêtes API Airbyte depuis Dagster
Contexte et motivation
Les pipelines de données jouent un rôle clé dans la transformation de données brutes en informations exploitables. Cependant, orchestrer ces pipelines, surtout lorsqu'ils impliquent plusieurs outils et doivent répondre à des cas d'utilisation variés, est un défi complexe.
Parmi les principaux problèmes identifiés :
- Dépendances et exécution séquentielle des tâches : les dépendances complexes entre les étapes d’extraction et de transformation exigent que chaque tâche se termine correctement avant que la suivante ne commence. Sans une stricte coordination, des incohérences de données peuvent survenir.
- Optimisation et efficacité du pipeline : une planification inadéquate entraîne des temps d’attente inutiles et une sous-utilisation des ressources, en particulier lors des périodes creuses comme la nuit.
- Gestion des erreurs : les problèmes réseau ou les instabilités d’API lors de l’extraction génèrent fréquemment des échecs, causant des retards et des indisponibilités de données dans les processus en aval.
- Contraintes d’infrastructure : les ressources matérielles limitées (puissance de calcul, performance, stockage) imposent des restrictions. Une surcharge des ressources, notamment lorsqu’elles sont sollicitées simultanément, peut affecter les performances et perturber le pipeline.
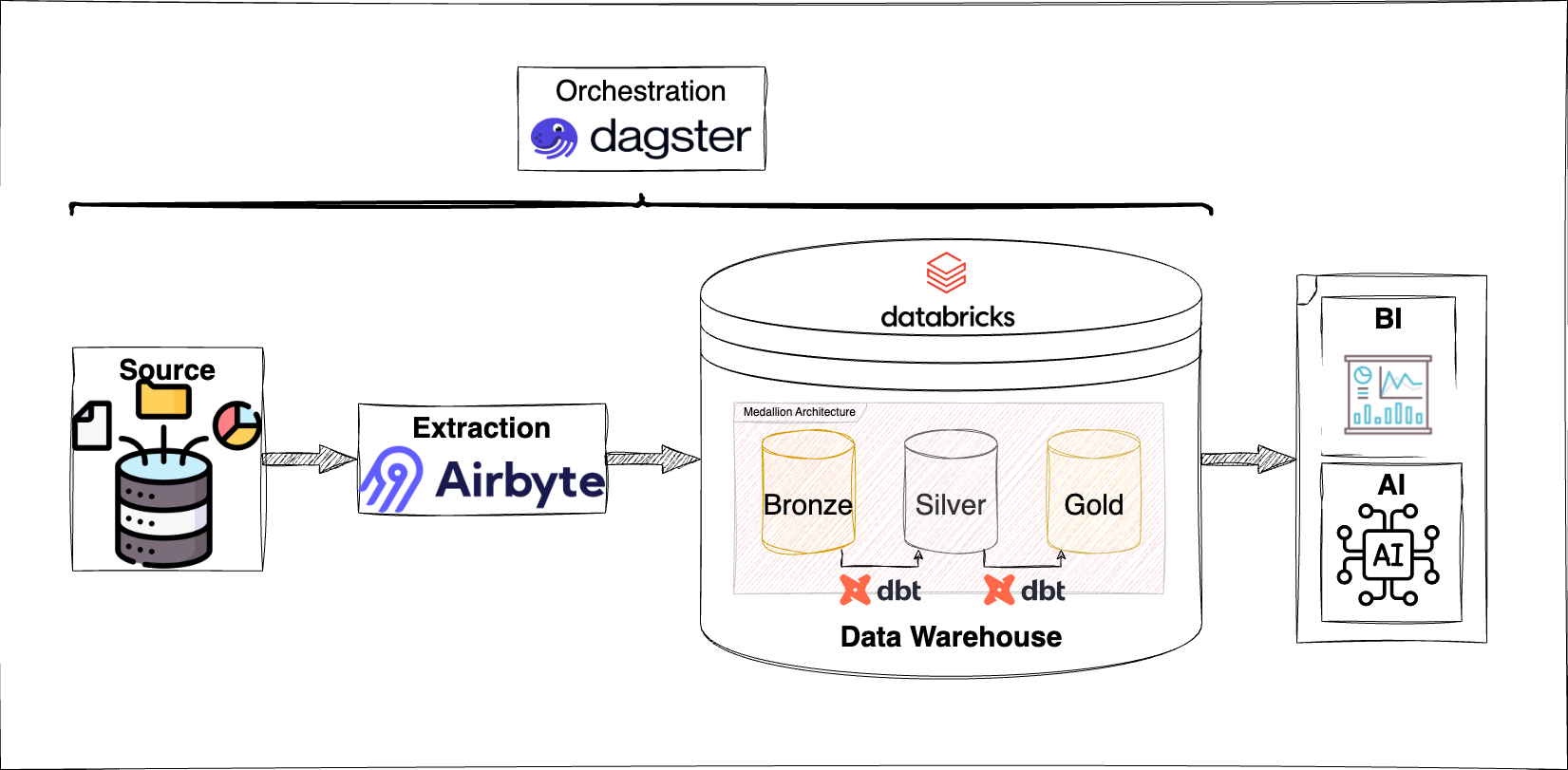
Dans la configuration actuelle, Airbyte est utilisé pour l'extraction des données, dbt pour leur transformation, et Dagster pour l'orchestration du pipeline. Toutefois, plusieurs défis limitent l'efficacité de cette approche :
- Configuration manuelle : chaque nouvelle source de données et chaque étape de transformation doivent être configurées manuellement, ce qui :
- Ajoute de la complexité.
- Augmente les risques d'erreurs.
- Limite la scalabilité.
- Problèmes de temporisation de l'API Airbyte : les retards récurrents de l'API d’Airbyte compliquent l’accès aux données, ce qui rend la maintenance du pipeline plus complexe et diminue la disponibilité des données.
Ainsi, bien que les outils soient fonctionnels, la gestion manuelle et les problèmes de temporisation freinent l’efficacité et la fiabilité du pipeline.
Vue d'ensemble de la solution : automatisation de la création des tâches séquentielles avec Dagster
Pour résoudre ces défis, j'ai mis en place une approche automatisée et mieux structurée en utilisant une configuration paramétrée dans Dagster. L’objectif principal est d’automatiser la création des pipelines, garantissant que chaque tâche d'extraction et de transformation s'exécute de manière séquentielle et sans intervention manuelle. Les principaux éléments de cette solution sont :
- Dictionnaire de configuration : un dictionnaire centralisé qui sert de source unique. Il définit chaque cas d'utilisation avec des paramètres spécifiques, tels que :
- Les besoins en tâches d'extraction et de transformation.
- Les horaires et les dépendances.
- Création automatisée des tâches : les tâches sont générées automatiquement à partir de la configuration, en séparant les tâches d'extraction avec Airbyte et les tâches de transformation avec dbt.
- Capteurs pour l'exécution séquentielle : des capteurs déclenchent chaque tâche en fonction du succès des tâches précédentes, ce qui permet de minimiser les écarts entre les exécutions et d'éviter les erreurs de temporisation de l'API.
Schéma du flux de travail du pipeline
Ci-dessous une description qui illustre le flux de travail du pipeline de données automatisé, montrant comment les tâches d'extraction (Airbyte) et de transformation (dbt) interagissent grâce à la planification et aux capteurs de Dagster. Ce flux de travail inclut les éléments suivants :
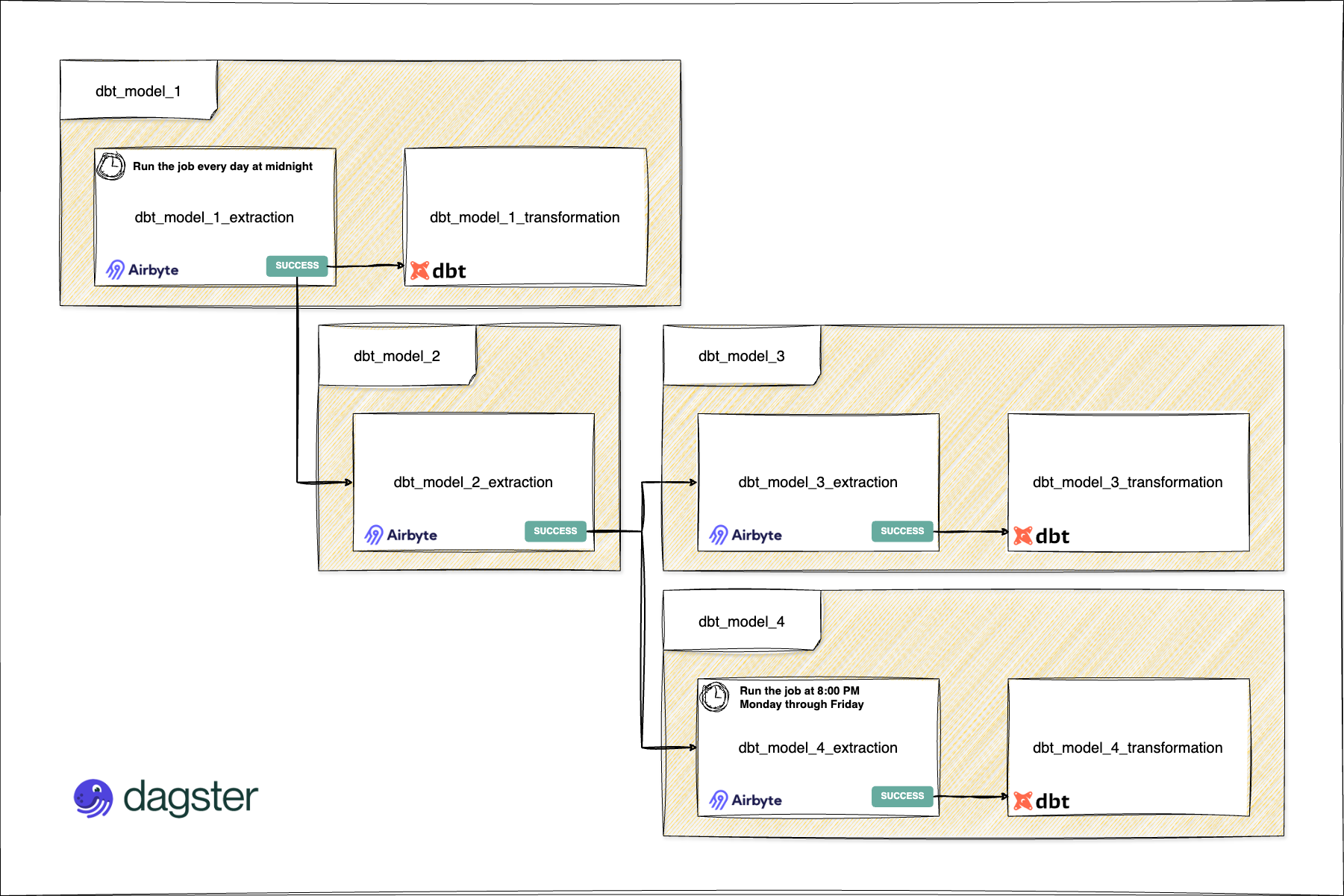
- Tâches d'extraction de données Airbyte : extraction des données brutes depuis les sources vers la couche bronze de l’entrepôt de données (data warehouse).
- Tâches de transformation de données dbt : transformation des données brutes de la couche bronze vers la couche silver, avec la création des tables de faits dans la couche gold.
- Capteurs : les capteurs surveillent la fin de chaque tâche et enchaînent les étapes automatiquement, assurant ainsi un flux continu.
- Horaires : les tâches sont déclenchées selon des horaires cron ou à la complétion des étapes précédentes, garantissant une exécution séquentielle sans temps d'attente inutile.
Cette organisation permet une gestion fluide et automatisée du pipeline, réduisant les erreurs et optimisant l'efficacité.
Détails techniques de l'implémentation
- Dictionnaire de configuration :
| Paramètre | Type | Description |
|---|---|---|
sources_extraction_job |
boolean |
Paramètre booléen pour définir si le job aura un processus d'extraction des données ou non. |
transformation_job |
boolean |
Paramètre booléen pour définir si le job aura un processus de transformation des données ou non. |
request_jobs |
array |
Liste des jobs qui seront déclenchés à la fin du job en cours. |
cron_schedule |
cron |
Permet de définir un horaire de lancement pour le job. |
# pipe_automatic_configuration.py
# Définition des jobs programmés sous forme de dictionnaire
jobs_definition_dict = {
'daily': { # Configuration pour les jobs quotidiens
'dbt_model_1': {
'sources_extraction_job': True, # Indique que le job inclut un processus d'extraction de données
'transformation_job': True, # Indique que le job inclut un processus de transformation des données
'request_jobs': ['dbt_model_2'], # Liste des jobs déclenchés une fois ce job terminé
'cron_schedule': '0 0 * * *' # Horaire CRON pour l'exécution quotidienne à minuit
},
'dbt_model_2': {
'sources_extraction_job': True, # Job d'extraction de données sans transformation
'transformation_job': False,
'request_jobs': ['dbt_model_3', 'dbt_model_4'] # Déclenche les jobs `dbt_model_3` et `dbt_model_4` après achèvement
},
'dbt_model_3': {
'sources_extraction_job': True, # Job complet d'extraction et de transformation
'transformation_job': True,
'request_jobs': [] # Aucun autre job à déclencher
},
'dbt_model_4': {
'sources_extraction_job': True,
'transformation_job': True,
'cron_schedule': '0 20 * * 1-5', # Exécution planifiée les jours de semaine à 20h00
'request_jobs': [] # Aucun autre job à déclencher
}
},
'weekly': {}, # Section pour les jobs hebdomadaires (à configurer si nécessaire)
'monthly': {} # Section pour les jobs mensuels (à configurer si nécessaire)
}Dictionnaire de configuration
- Création automatique des tâches à partir de la configuration :
# jobs.py
from dagster import define_asset_job
from dagster_dbt import build_dbt_asset_selection
from .assets import dbt_project_name_dbt_assets
from .pipe_automatic_configuration import jobs_definition_dict
def create_jobs_from_dict():
"""
Fonction pour créer un dictionnaire de jobs Dagster à partir de la configuration de jobs.
Cette fonction parcourt le dictionnaire de configuration et crée un job d'extraction ou de
transformation selon les détails du modèle.
"""
# Dictionnaire pour stocker les jobs créés
jobs_dict = {}
# Parcours du dictionnaire de configuration
for _, models in jobs_definition_dict.items():
for model_name, model_details in models.items():
# Création d'un job d'extraction des données si spécifié dans la configuration
if model_details.get('sources_extraction_job'):
jobs_dict[f"{model_name}_extraction"] = define_asset_job(
name=f"{model_name}_extraction",
# Sélection des sources dbt associées au modèle
selection=build_dbt_asset_selection([dbt_project_name_dbt_assets], dbt_select=f"source:{model_name}")
)
# Création d'un job de transformation des données si spécifié dans la configuration
if model_details.get('transformation_job'):
jobs_dict[f"{model_name}_transformation"] = define_asset_job(
name=f"{model_name}_transformation",
# Sélection des modèles dbt associés pour le job de transformation
selection=build_dbt_asset_selection([dbt_project_name_dbt_assets], dbt_select=f"{model_name}")
)
# Retourne le dictionnaire des jobs créés
return jobs_dict
# Exécution de la fonction pour générer les jobs et les stocker dans jobs_dict
jobs_dict = create_jobs_from_dict()
Classe job.py de projet Dagster
- Création automatique des horaires à partir de la configuration :
# schedules.py
from dagster import ScheduleDefinition
from .pipe_automatic_configuration import jobs_definition_dict
from .jobs import jobs_dict
def create_schedules_from_dict():
"""
Fonction pour créer des définitions de schedules (horaires) à partir de jobs configurés.
Cette fonction parcourt le dictionnaire de configuration des jobs et crée un schedule
pour chaque job ayant une configuration d'horaire `cron_schedule`.
"""
schedules_dict = {} # Dictionnaire pour stocker les schedules définis
# Parcours des jobs dans le dictionnaire de définition
for _, models in jobs_definition_dict.items():
for model_name, model_details in models.items():
# Vérifie si un horaire CRON est défini pour le job actuel
if 'cron_schedule' in model_details:
# Création d'une définition de schedule pour chaque job avec un horaire
schedules_dict[f"{model_name}_schedule"] = ScheduleDefinition(
job=jobs_dict[f"{model_name}_extraction"], # Associe le job d'extraction au schedule
cron_schedule=model_details['cron_schedule'] # Utilise l'horaire CRON spécifié
)
# Retourne le dictionnaire des schedules créés
return schedules_dict
# Exécution de la fonction pour initialiser schedules_dict avec les schedules définis
schedules_dict = create_schedules_from_dict()Classe schedule.py de projet Dagster
- Création automatique des déclencheurs à partir de la configuration :
# sensors.py
from dagster import run_status_sensor, RunRequest, DagsterRunStatus
from .pipe_automatic_configuration import jobs_definition_dict
def customize_job_sensor(actual_job, request_jobs):
"""
Crée un capteur personnalisé qui déclenche des jobs après l'exécution réussie d'un job spécifique.
Paramètres :
- actual_job : Le nom du job actuel pour lequel le capteur est configuré
- request_jobs : Liste des jobs à déclencher une fois que actual_job est terminé avec succès
"""
# Définition d'un capteur pour surveiller l'achèvement réussi du job actuel
@run_status_sensor(name=f"{actual_job}_sensor", run_status=DagsterRunStatus.SUCCESS)
def sensor_function(context):
# Vérifie que le job surveillé correspond à celui défini dans le capteur
if context.dagster_run.job_name == actual_job:
# Déclenche chaque job dans request_jobs après le succès de actual_job
for rj in request_jobs:
yield RunRequest(job_name=rj) # Génère une demande de lancement pour chaque job requis
return sensor_function
def create_sensors_from_dict():
"""
Fonction pour créer un dictionnaire de capteurs (sensors) à partir de la configuration des jobs.
Pour chaque job configuré avec des dépendances (request_jobs), cette fonction crée un capteur
qui déclenche les jobs spécifiés dans request_jobs.
"""
sensors_dict = {} # Dictionnaire pour stocker les capteurs définis
# Parcours du dictionnaire de configuration des jobs
for _, models in jobs_definition_dict.items():
for model_name, model_details in models.items():
actual_job = f"{model_name}_extraction" # Nom du job d'extraction actuel
# Liste des jobs à lancer après le succès du job actuel
request_jobs = [f"{req}_extraction" for req in model_details.get('request_jobs', [])] + ([f"{model_name}_transformation"] if model_details.get('transformation_job') else [])
# Crée un capteur seulement s'il y a des jobs à déclencher
if request_jobs:
# Associe le capteur personnalisé au modèle actuel dans sensors_dict
sensors_dict[f"{model_name}_sensor"] = customize_job_sensor(actual_job, request_jobs)
# Retourne le dictionnaire des capteurs créés
return sensors_dict
# Exécution de la fonction pour initialiser sensors_dict avec les capteurs définis
sensors_dict = create_sensors_from_dict()Classe sensors.py de projet Dagster
Avantages du pipeline automatisé
- Exécution séquentielle fluide : en déclenchant automatiquement les tâches en fonction de leurs dépendances, cette solution élimine les temps d'inactivité, garantissant que chaque tâche s'exécute le plus tôt possible, évitant l'exhaustivité de la connexion Airbyte.
- Réduction de la configuration manuelle : grâce au dictionnaire de configuration, l'ajout ou la modification de tâches nécessite seulement une mise à jour dans le dictionnaire, sans redéfinir chaque tâche individuellement dans Dagster, réduisant ainsi la nécessité d'interventions manuelles récurrentes.
- Diminution des risques d'erreurs : avec des tâches planifiées et des capteurs qui surveillent leur réussite, les risques de temporisations d'API et de non-exécution sont réduits. Les tâches ne progressent que lorsque les données nécessaires sont disponibles, assurant une exécution plus fiable et limitant les erreurs liées à la surcharge de la connexion Airbyte.
Cette approche garantit une gestion plus efficace et plus fiable des pipelines de données, tout en réduisant les risques et la complexité opérationnelle.
Limitations et travaux futurs
Actuellement, les actifs doivent encore être définis manuellement en raison d'une limitation de l'API de Dagster, ce qui nécessite des mises à jour chaque fois qu'une nouvelle source de données ou transformation est ajoutée. Cela reste un obstacle à l'automatisation complète du pipeline, et des améliorations de l'API seront nécessaires pour éliminer cette contrainte.
Autres aspects à prendre en consideration
- Unification des noms des variables et composants : il est essentiel de garantir une uniformité dans les noms des variables et des composants à travers les différentes technologies utilisées dans le pipeline (par exemple, dans Dagster, dbt et Airbyte). Cela permet de :
- Simplifier la gestion.
- Réduire les erreurs de configuration.
- Assurer une intégration fluide entre les différents systèmes.
- Flexibilité dans le déclenchement des pipelines : il serait avantageux d’avoir la possibilité de modifier le déclenchement des pipelines, même si le prérequis n’a pas abouti à un succès complet. Cela offrirait plus de flexibilité pour :
- Gérer les échecs partiels ou les erreurs temporaires.
- Permettre aux équipes de tester ou d'exécuter certaines tâches indépendamment des dépendances sans attendre un succès complet des étapes précédentes.
- Synchronisation incrémentielle d'Airbyte – Ajout et déduplication : la synchronisation incrémentielle d'Airbyte permet de transférer uniquement les données nouvelles ou mises à jour depuis la dernière exécution, plutôt que de synchroniser l’intégralité de la source de données à chaque fois. Cela permet de :
- Réduire considérablement le temps de traitement.
- Minimiser la consommation des ressources (CPU, mémoire et stockage).
Ces améliorations et considérations permettent d’optimiser encore plus l'efficacité et la flexibilité du pipeline de données.
Conclusion
L'automatisation de l'orchestration des tâches d'extraction et de transformation de données avec Dagster, Airbyte, et dbt a permis d'obtenir un pipeline plus efficace, robuste, et évolutif. En utilisant le dictionnaire de configuration et les déclencheurs basés sur des capteurs de Dagster, le pipeline fonctionne de manière fluide, même face aux erreurs réseau et aux temporisations d'API. Bien que des travaux restent nécessaires pour automatiser entièrement la création des actifs, cette configuration représente une amélioration significative de la gestion des pipelines de données, garantissant une disponibilité fiable et en temps voulu des données.
Si vous gérez des flux de travail ETL complexes sur plusieurs sources de données, cette configuration pourrait simplifier la gestion de votre pipeline et en améliorer la fiabilité, tout en offrant la flexibilité nécessaire pour répondre aux exigences spécifiques de votre environnement de données.








{kind=link}