
Si le titre de cet article évoque une chronologie technique des plateformes de données, le véritable sujet est ailleurs. Derrière l'évolution des serveurs et des pipelines se cache une histoire de friction organisationnelle constante. Depuis 40 ans, les entreprises tentent de résoudre une équation complexe : comment aligner la rigidité nécessaire de la technologie avec la volatilité des besoins business ?
Ce voyage n'est pas linéaire. C'est une succession de corrections entre l'ordre et le chaos, la centralisation et la fédération. Pour illustrer ces changements de paradigme, j'utiliserai des analogies familières – de la friterie traditionnelle à la franchise mondiale – afin de comprendre comment nous en sommes arrivés à l'ère de l'IA générative.
Acte 1 : L'ère de l'ordre
Dans les années 90, l'informatique décisionnelle (BI) émerge en réaction à un chaos informationnel grandissant. Le problème n'est pas technique, mais sémantique : le marketing et la finance ne s'accordent pas sur les chiffres, faute de définitions partagées. Pour le management, la priorité absolue devient la construction d'une "Single Source of Truth".
La réponse architecturale à ce besoin est le Data Warehouse. Sa philosophie est comparable à celle d'une friterie traditionnelle : un menu strict, affiché au mur, où l'on ne sert que ce qui a été prévu à l'avance. C'est le principe du Scheme-on-Write. Avant même d'ingérer la moindre donnée, sa structure (tables, types, relations) doit être rigoureusement définie et modélisées.
Le processus dominant est l'ETL (Extract - Transform - Load). La donnée est extraite des systèmes opérationnels (ERP, CRM), nettoyée et transformée en dehors de l'entrepôt de données, puis chargée dans une structure finale, optimisée pour la lecture.
Les bases de données relationnelles massivement parallèles comme Teradata ou Oracle Exadata dominent le marché "on-premise", avant d'être progressivement remplacéees par les premières itérations cloud comme Amazon Redshift ou Google BigQuery. Le SQL est l'unique interface d'accès
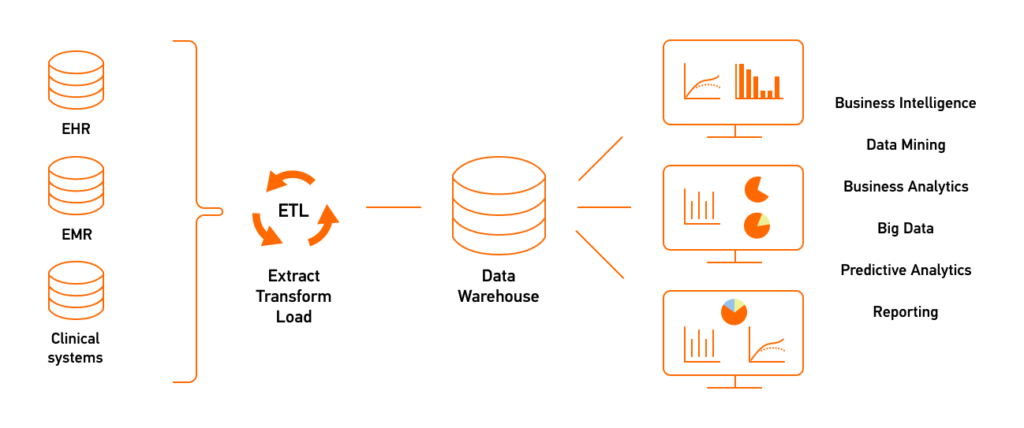
Si ce modèle excelle pour le reporting financier grâce à ses propriétés ACID et sa cohérence, sa rigidité devient son talon d'Achille. Modifier un schéma pour intégrer une nouvelle source peut prendre des semaines, créant une frustration croissante côté business : impossible de commander un "plat hors menu" sans perturber toute la cuisine.
Acte 2 : le challenge du Big Data
L'arrivée du Web, du mobile et de l'IoT dans les année 2010 fait exploser les volumes et la variété des données (logs, images, JSON). La rigidité du Warehouse devient un frein insupportable. Le pendule oscille alors vers l'extrême inverse : la liberté totale de stockage.
C'est l'avènement du Data Lake, que l'on pourrait comparer à une festival comme le Main Square. C'est immense, foisonnant, et la règle d'or change radicalement : "Stockez tout maintenant, on structurera plus tard". On passe au Schema-on-Read.
L'architecture bascule de l'ETL vers l'ELT (Extract - Load - Transform). La donnée atterrit brute dans le Lake, et la transformation n'est appliquée qu'au moment de la consommation.
Le système de fichiers distribué HDFS (Hadoop) puis le stockage objet (Amazon S3, Google Cloud Storage) permettent de stocker des pétaoctets à moindre coût. Le traitement massivement distribué avec Apache Spark devient la norme pour traiter ces volumes, tandis que Kafka gère les flux en temps réel. Enfin, des formats de fichiers colonnes comme Parquet ou Avro optimisent les performances de lecture.
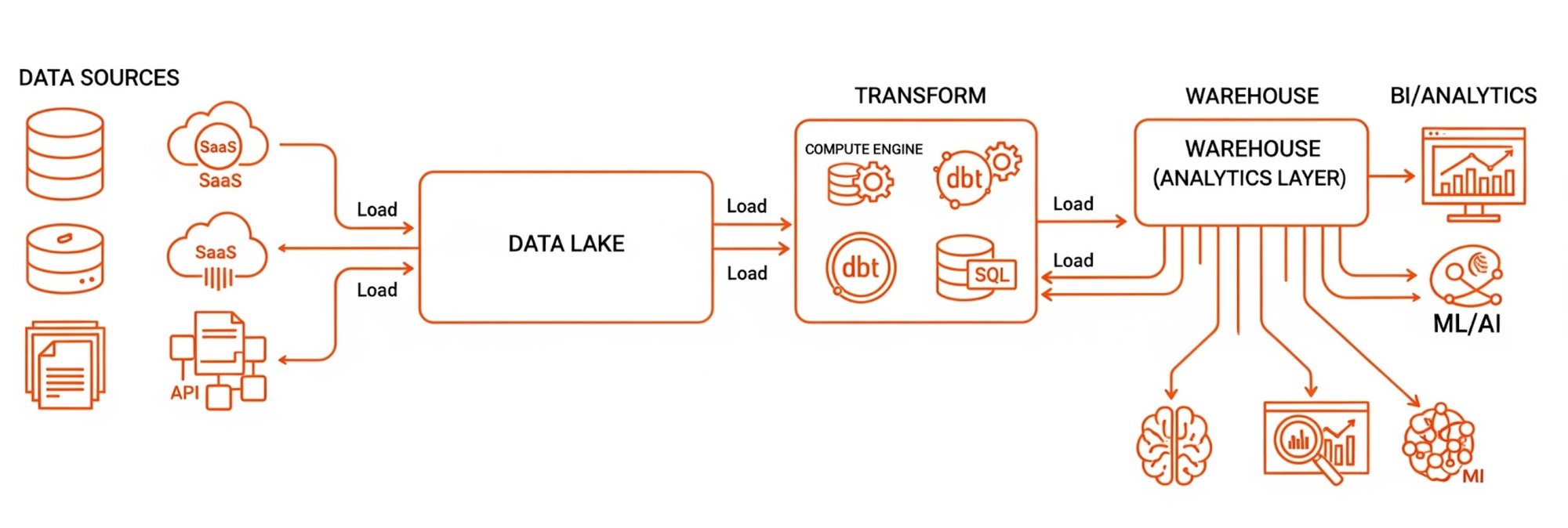
Cependant, cette liberté a un coût. Sans gouvernance stricte, le Data Lake se transforme en Data Swamp (marécage de données). Les fichiers s'accumulent sans documentation, la qualité se dégrade, et la confiance des utilisateurs s'effondre. On a résolu le problème du volume, mais on a créé un problème de confiance.
Acte 3 : La réconciliation
Vers 2020, l'industrie réalise qu'elle ne peut plus choisir entre la fiabilité du Warehouse et la flexibilité du Lake. La convergence de ces deux mondes donne naissance au Lakehouse.
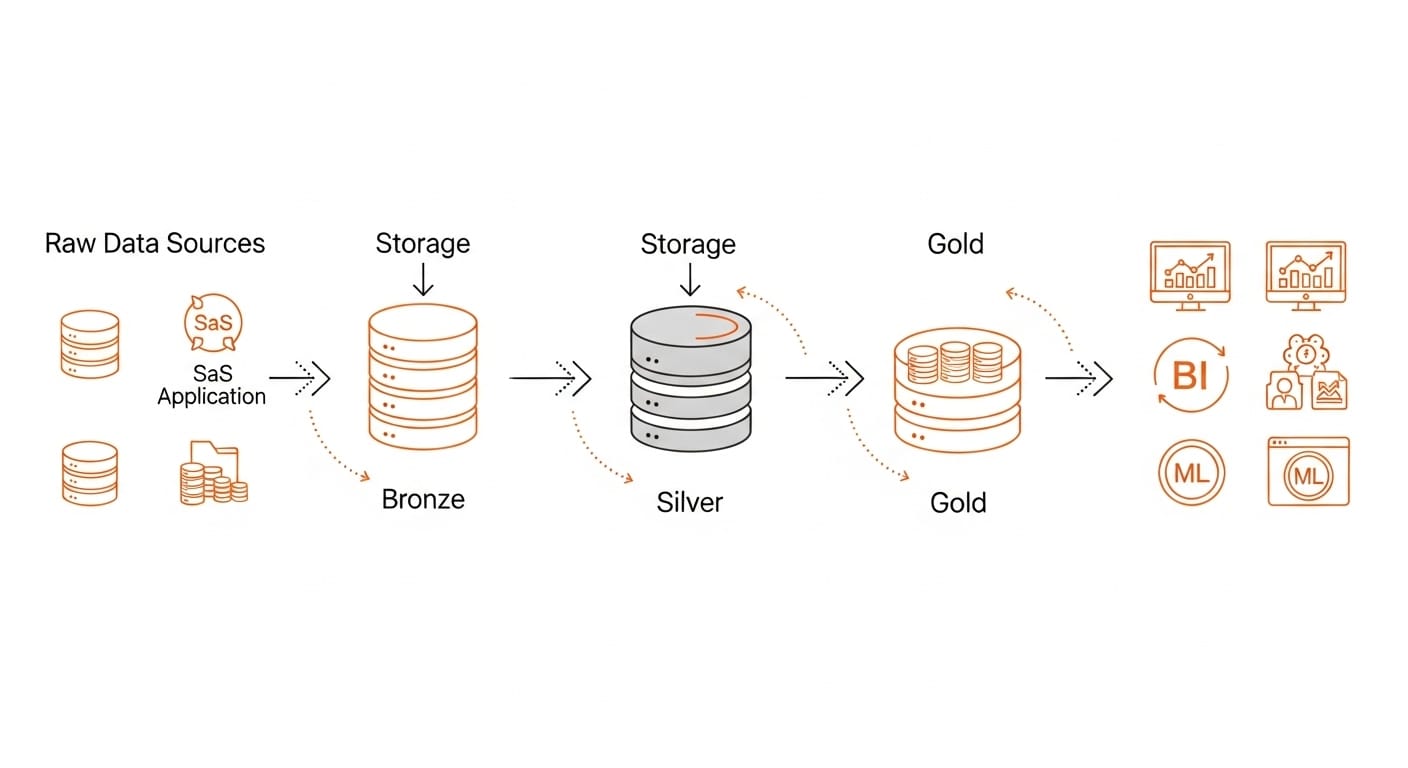
Imaginez une Brasserie moderne capable d'envoyer des plats simples très rapidement tout en proposant une carte gastronomique complexe, le tout avec la même rigueur sanitaire. Techniquement, le Lakehouse réussit ce tour de force en séparant physiquement le Compute (la puissance de calcul) du Storage (le stockage objet), tout en réintroduisant une couche de gestion transactionnelle.
La standardisation de l'Architecture Médaillon permet d'organiser selon son cycle de vie et sa qualité :
- Bronze (Raw) : L'historique brut et immutable.
- Silver (Clean) : La donnée dédupliquée, typée et structurée.
- Gold (Curated) : Les agrégats métiers prêts pour la consommation BI et IA.
Cette architecture est rendue possible par la Modern Data Stack :
- L'outil dbt (data build tool) s'impose comme le standard, permettant d'appliquer les bonnes pratiques du software engineering (versioning Git, tests unitaires, CI/CD) aux pipelines SQL.
- Des formats de fichiers comme Delta Lake ou Apache Iceberg apportent les transactions ACID et le "Time Travel" sur le stockage objet du Lake.
- Snowflake, Databricks et Google BigQuery incarnent cette fusion.
Pourtant, malgré cette maturité technologique, un goulot d'étranglement persiste : l'humain. L'équipe Data centrale, aussi outillée soit-elle, ne peut pas scaler indéfiniment face aux demandes exponentielles de toute l'entreprise. Elle devient le point de blocage unique.
Acte 4 : scaler par la fédération
Pour briser ce goulot d'étranglement centralisé, il faut changer de paradigme organisationnel. Si une seule cuisine ne suffit pas, il faut ouvrir des franchises. C'est l'essence du Data Mesh, théorisé par Zhamak Dehghani.
Le modèle ressemble à celui d'une grande chaîne de franchise comme McDonald's. Chaque restaurant (domaine métier) est autonome, possède son équipe et ses objectifs, mais tous respectent des standards globaux (hygiène, packaging, recettes) imposés par la marque.
Le Mesh n'est pas une technologie, mais une architecture socio-technique reposant sur 4 piliers :
- Data Ownership : La responsabilité de la donnée est déplacée vers ceux qui la comprennent. La logistique gère et expose les données logistiques.
- Data as a Product : La donnée n'est plus un sous-produit technique, mais un véritable produit avec des consommateurs, une documentation, un SLA et un cycle de vie géré.
- Self-Serve Platform : Pour éviter que chaque domaine ne réinvente la roue, une équipe transverse fournit une infrastructure "clé en main" (provisioning, sécurité, orchestration).
- Federated Governance : Des politiques globales sont définies collégialement pour assurer l'interopérabilité et la sécurité entre les domaines.
Côté stack, le Mesh s'appuie sur des outils de Data Catalog (comme DataHub ou Collibra) pour la découverte, et sur des protocoles de partage sécurisés (Delta Sharing) ou des Data Contracts pour garantir la stabilité des interfaces entre producteurs et consommateurs.
Acte 5 : le nouvel horizon
Alors que nous pensions avoir atteint un équilibre avec le Data Mesh, l'arrivée massive de l'IA générative rebat les cartes.
Considérez l'IA comme un stagiaire surdoué, capable d'apprendre et de produire à une vitesse phénoménale, mais souffrant d'un défaut majeur : l'hallucination. Si vous nourrissez ce stagiaire avec des documents obsolètes ou contradictoires, il vous répondra avec une confiance absolue, mais totalement erronée.
C'est ici que l'histoire prend tout son sens. Les architectures que nous avons construites (Lakehouse, Mesh) ne servent pas uniquement à alimenter des tableaux de bord. Elles sont la condition sine qua non pour déployer de l'IA à l'échelle.
Pour une architecture RAG (Retrieval-Augmented Generation) ou qu'un agent IA soit pertinent, il doit puiser dans des Data Products fiables.
- Le Data Product fournit la donnée propre et fraîche.
- La Gouvernance assure que l'IA ne révèle pas de données sensibles.
- La Sémantique (portée par le catalogue) donne le contexte nécessaire au modèle pour "comprendre" et non juste "prédire".
En somme, nous avons passé quarante ans à structurer nos données pour les humains; nous découvrons aujourd'hui que nous avons, sans le savoir, préparé le terrain pour les machines.
De la friterie locale à la gouvernance fédérée, l'objectif de la plateforme de données n'a jamais varié : abstraire la complexité technique pour permettre au business de prendre de meilleures décisions.
Aucune de ces ères n'efface totalement la précédente; elles se sédimentent. Le Warehouse vit toujours au coeur du Lakehouse, qui lui-même sert de noeud dans le Data Mesh. Aujourd'hui, le défi n'est plus de savoir stocker la donnée, mais de savoir l'exposer avec un niveau de confiance suffisant pour qu'elle devienne le carburant de votre IA.
La question n'est donc plus "quelle est votre stack ?", mais bien : "quel est votre niveau de maturité organisationnelle ?"








{kind=link}