
En tant que développeur travaillant sur des projets Spring Boot complexes, j’ai souvent été confronté à la nécessité de naviguer rapidement entre la base de données et le code. Entre les requêtes SQL pour explorer les données, la création d’entités JPA et la génération de DTOs, le processus de développement pouvait devenir fastidieux et répétitif.
C’est pourquoi j’ai décidé de configurer un serveur MCP (Model Context Protocol) permettant une communication directe avec ma base de données PostgreSQL, transformant ainsi mon workflow de développement.
Le travail qui suit a été réalisé avec les GitHub Agents sous VSCode. Il vous faudra également avoir Node.js installé au préalable, car le serveur MCP s’exécute dessus.
Piqûre de rappel : Qu'est-ce que MCP ?
Le Model Context Protocol (MCP) est un protocole qui permet aux assistants IA d’interagir avec des services externes de manière sécurisée et standardisée. Dans notre cas, il nous permet de créer une interface directe entre notre environnement de développement et notre base de données PostgreSQL.
Comment ajouter ce serveur et le configurer
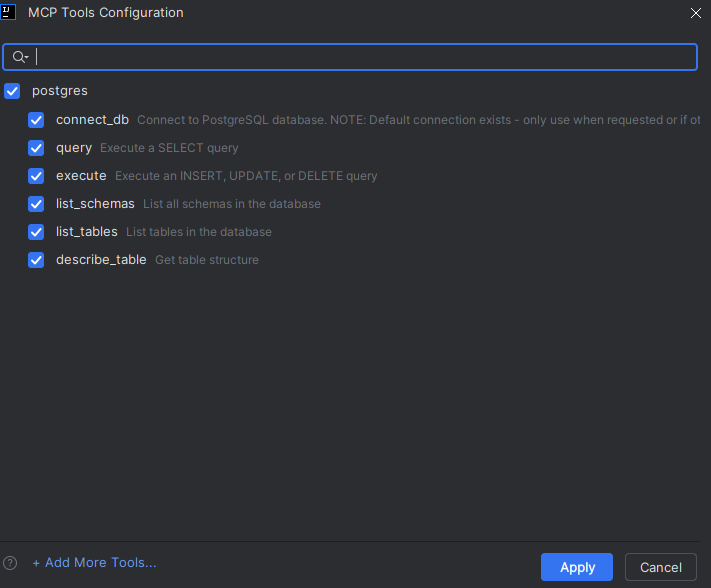
Sur VSCode + Copilot , il suffit de passer en mode Agent et de cliquer sur la clé à gauche, où l’on ajoute un serveur.

Une interface s’ouvre alors, vous proposant d’ajouter plus d’outils. Si c’est la première fois que vous accédez à cette section, vous verrez directement le texte “+ Add More Tools…” affiché au centre de l’écran.
Le fichier de configuration mcp.json s’ouvre ensuite (sa localisation dépend de votre installation). Vous pouvez alors y placer la configuration suivante, en remplaçant bien sûr les données de connexion par les vôtres. Ici, nous utilisons le serveur mcp-postgres-server, mais si vous en connaissez d’autres, n’hésitez pas à les intégrer.
{
"servers": {
"postgres": {
"command": "npx",
"args": ["mcp-postgres-server"],
"env": {
"POSTGRES_HOST": "localhost",
"POSTGRES_PORT": "5433",
"POSTGRES_USER": "user",
"POSTGRES_PASSWORD": "password",
"POSTGRES_DB": "defaultdb",
"POSTGRES_SSL": "false"
}
}
}
}
Bravo ! L’outil est prêt à être utilisé.
Vous devriez voir apparaître une petite clé avec les six outils ajoutés, confirmant la bonne installation.
Fonctionnalités du serveur MCP
Tout d’abord, demandez à l’agent de se connecter à la base avec une phrase simple, par exemple : « Connecte-toi à la base ». Vous pouvez vérifier la bonne connexion en demandant des informations sur une table : « Donne-moi plus d’informations sur la table mySchema.Employee ».
Tester le serveur
Pour le test, prenons un exercice simple : créer une table dans la BDD, puis générer automatiquement tout le nécessaire côté back-end (entité, DTO, convertisseur, repository).
Voici le prompt utilisé :
Désormais on garde en tête que ça sera mySchema le schema qu'on utilisera. Créé une table testing, avec 3 colonnes :
un id auto-genere type uuid
info_une type text
info_deux type nombre
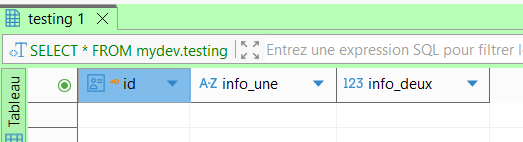
La table est alors créée et vous pouvez vérifier sa présence.
Ensuite, demandons à l’agent de générer les éléments back nécessaires :
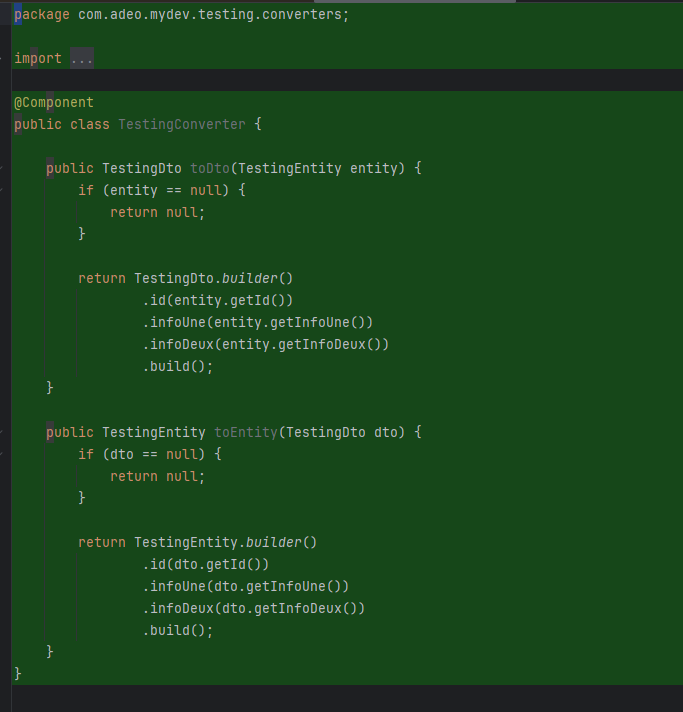
Sur mon projet springboot, j'ai besoin maintenant que tu créé l'entité, le dto, le repository et le converteur pour cette table. Tu peux t'inspirer de ce qui est déjà fait
Et voila le travail !
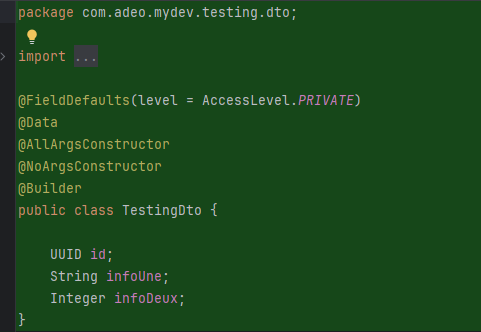
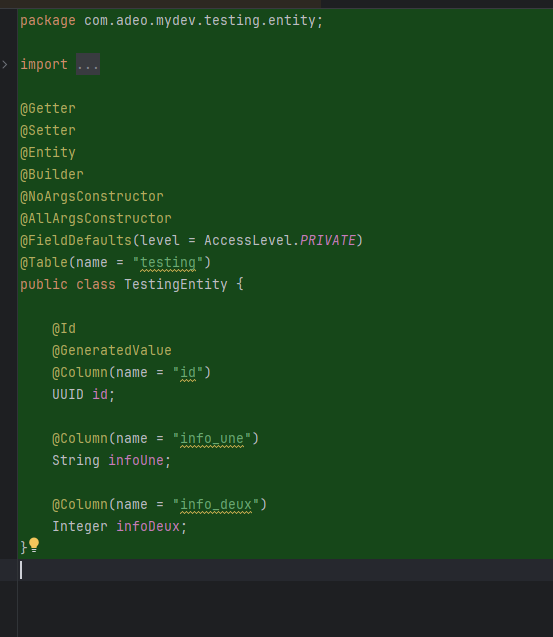
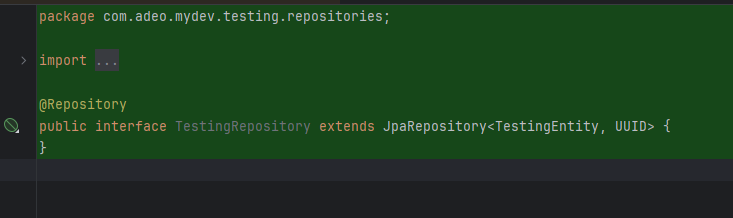
Avantages observés
Gain de temps considérable
Avant MCP :
- ⏱️ 30–45 minutes pour créer une entité complète
- 🔍 Allers-retours constants entre IDE et base de données
- 📝 Création manuelle de chaque classe, avec risques d’erreurs
Après MCP :
- ⚡ 2–3 minutes pour générer toute la couche de données
- 🎯 Code généré automatiquement selon les conventions du projet
- ✅ Cohérence garantie avec l’architecture existante
Réduction des erreurs
- Typos éliminées : les noms de colonnes sont extraits directement de la base
- Types cohérents : mapping automatique PostgreSQL ↔ Java
- Annotations correctes : respect des conventions JPA et Lombok
Exploration facilitée
Il est possible d’écrire une phrase simple et d’obtenir la requête SQL correspondante pour une opération complexe.
Exemple :
Donne moi la requête me permettant de voir le nombre de personnes qui sont dans la table mySchema.employee avec une date de fin de contrat > maintenant , mais qui ne se trouve pas dans la table mySchema.worker
L’agent remarque immédiatement le manque de lien direct entre les deux tables, analyse les descriptions disponibles et finit par produire la requête correspondante :
SELECT COUNT(*) as nombre_personnes
FROM mySchema.employee e
WHERE e.contract_end_date > CURRENT_DATE
AND NOT EXISTS (
SELECT 1
FROM mySchema.worker_employee we
WHERE we.ldap = e.ldap
)
On peut même lui demander d’optimiser la requête : il proposera alors d’autres jointures, la création d’index, etc.
Recommandations pour l’implémentation
Sécurité
- Utiliser des connexions chiffrées
- Limiter les permissions de l’utilisateur de base
- Mettre en place une authentification robuste
Performance
- Utiliser des pools de connexions
- Mettre en cache les métadonnées fréquemment utilisées
- Définir des timeouts appropriés
Conventions de code
- Définir des templates pour garantir la cohérence
- Ou bien prévenir l’agent en amont afin qu’il étudie vos structures actuelles et s’y adapte
Conclusion
La mise en place d'un serveur MCP pour la communication avec PostgreSQL a véritablement révolutionné mon workflow de développement. Cette approche permet de :
- accélérer significativement le développement de nouvelles fonctionnalités,
- garantir la cohérence du code avec les conventions du projet,
- réduire les erreurs liées à la saisie manuelle,
- faciliter l’exploration et le debugging de la base de données.
L’investissement initial dans la configuration du serveur MCP est rapidement amorti par les gains de productivité quotidiens. Pour des projets avec de nombreuses tables et entités complexes, cette approche devient tout simplement indispensable.
Pour aller plus loin...
Si cela vous inspire et que vous souhaitez créer vos propres MCP, voici un petit template qui pourrait vous aider.
Voici les fichiers :
Après avoir placé les fichiers (index.js, package.json, etc.) dans un dossier, ouvrez le terminal et lancez un petit npm install pour télécharger les dépendances nécessaires. Vous pourrez ensuite déclarer ce serveur dans votre mcp.json et le démarrer.
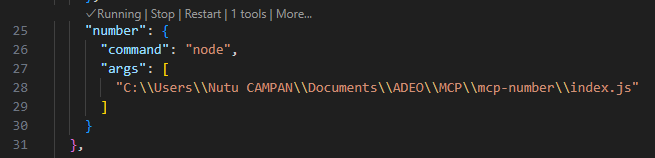
Vous aurez alors votre serveur MCP opérationnel, prêt à être utilisé en toute tranquillité.





{kind=link}