
Comfy.ui c’est quoi ?
Comfy.ui est un logiciel d’interface graphique (GUI), permettant de d'interagir avec les modèles de données utilisés pour de la génération artistique, ce qui inclut l’image, la vidéo, l’audio, et les modèles 3D.
Il se présente sous la forme de nodes à connecter entre eux, représentant chacun une opération spécifique, comme le chargement des modèles, l’upscaling, la gestion des masques, des LoRAs, etc…
Pourquoi utiliser Comfy.ui, et pas directement microsoft designer, et consorts ?
- Open source et gratuit : Contrairement à de nombreux outils propriétaires, ComfyUI est accessible à tous sans frais.
- Exécution locale : Toutes les opérations peuvent se dérouler sur votre machine, garantissant la confidentialité de vos données.
- Compréhension approfondie : ComfyUI permet de visualiser et de comprendre les étapes de génération d'images par IA, un atout pour les curieux et les techniciens.
- Personnalisation avancée : Vous pouvez adapter vos workflows pour répondre à des besoins spécifiques, comme une direction artistique particulière ou la génération en masse d'images dérivées.
- API personnalisée : Une fois votre workflow configuré, vous pouvez la déployer sur un cloud, puis l'interroger comme une API, ce qui ouvre des possibilités d'intégration dans d'autres projets.
La principale limitation de cette approche est qu’il faut une bonne machine pour faire fonctionner le modèle sans patienter trop longtemps, ou bien vraiment se contenter des modèles les plus simples.
Ce que l’on entend par une bonne machine :
- Une carte graphique de marque nVidia, avec (important), au moins 8 GB de VRAM. En gros ça correspond à une carte graphique RTX 4060, donc de moyenne gamme. Plus la VRAM est importante, mieux c’est !
- Au moins 16GB de ram, idéalement 64 GB
- Un CPU intel i7, i9 recommandé
Cela correspond à une configuration de gamer de moyenne (voire de haute gamme pour certains composants).Cependant, il est possible quand même d’effectuer de la génération d’images sur des petits modèles, (voire sans carte graphique), mais les performances seront vraiment dégradées sur les modèles récents. Et la raison derrière cela, c’est que la technologie utilisée pour optimiser et accélérer la vitesse de traitement des LLMs, se nomme CUDA (Compute Unified Device Architecture) et est une propriété exclusive de nVidia.
Globalement, ce sera plus lent, mais ce ne sera pas impossible d’avoir des images de qualité avec des modèles plus anciens (comme SD.1.5, ou SDXL). Les modèles plus récents (Flux dev/Shnell, SD 3.5…) auront généralement une meilleure compréhension directe et un “talent artistique”, plus prononcé, mais seront bien plus lents à l’exécution.
Comment fonctionne une génération d'images avec une intelligence artificielle au fait ?
Alors en soi, c’est compliqué, voire un peu magique ! Mais au moins, on peut y voir les différents concepts utilisés :
Le principe de Stable Diffusion peut être comparé à un artiste qui dessine une image en partant d’un flou gaussien (pensez neige de TV Cathodique) :
- Gribouillage de départ : Stable Diffusion commence avec une image complètement aléatoire, un peu comme de la neige sur un écran de télévision. C'est ce qu'on appelle le "bruit".
- CLIP (prompts) : Vous donnez à Stable Diffusion des instructions, appelées "prompts", qui décrivent ce que vous voulez voir dans l'image. Par exemple, "un chat qui joue avec une balle de laine". Les instructions textuelles fournies passent dans un modèle (CLIP) qui transforme le texte en représentations mathématiques.
- Le débruitage progressif : L'algorithme de Stable Diffusion (autrement dit l’U-Net) va ensuite, étape par étape, enlever le "bruit" de l'image aléatoire. À chaque étape, il utilise les instructions du prompt pour deviner ce qui devrait se trouver dans l'image. C'est comme si l'artiste, en regardant son gribouillage, se disait : "Ah, ici, il devrait y avoir une patte de chat" et "Là, une balle de laine".
- L'image finale : Après de nombreuses étapes, le "bruit" est presque complètement enlevé, et une image claire et détaillée apparaît, correspondant à ce que vous avez demandé dans le prompt. Elle passe dans un décodeur appelé VAE (Variable Auto Encoder), qui transforme la représentation mathématique latente de l’image, en pixels compréhensibles sous forme d’image.
Stable Diffusion utilise des modèles d'intelligence artificielle qui ont été entraînés sur de considérables quantités d'images. Ces modèles ont appris à reconnaître les formes, les couleurs et les textures, et ils savent comment les assembler pour créer une image cohérente.
En résumé, Stable Diffusion part d'un gribouillage aléatoire, utilise vos instructions pour deviner ce qui devrait se trouver dans l'image, et enlève progressivement le bruit pour révéler l'image finale.
Notre première image générée !
L'installateur est disponible sur le site officiel, le lien est cliquable ici , et une fois l'installation effectuée on arrive sur cette interface.
Explication du workflow
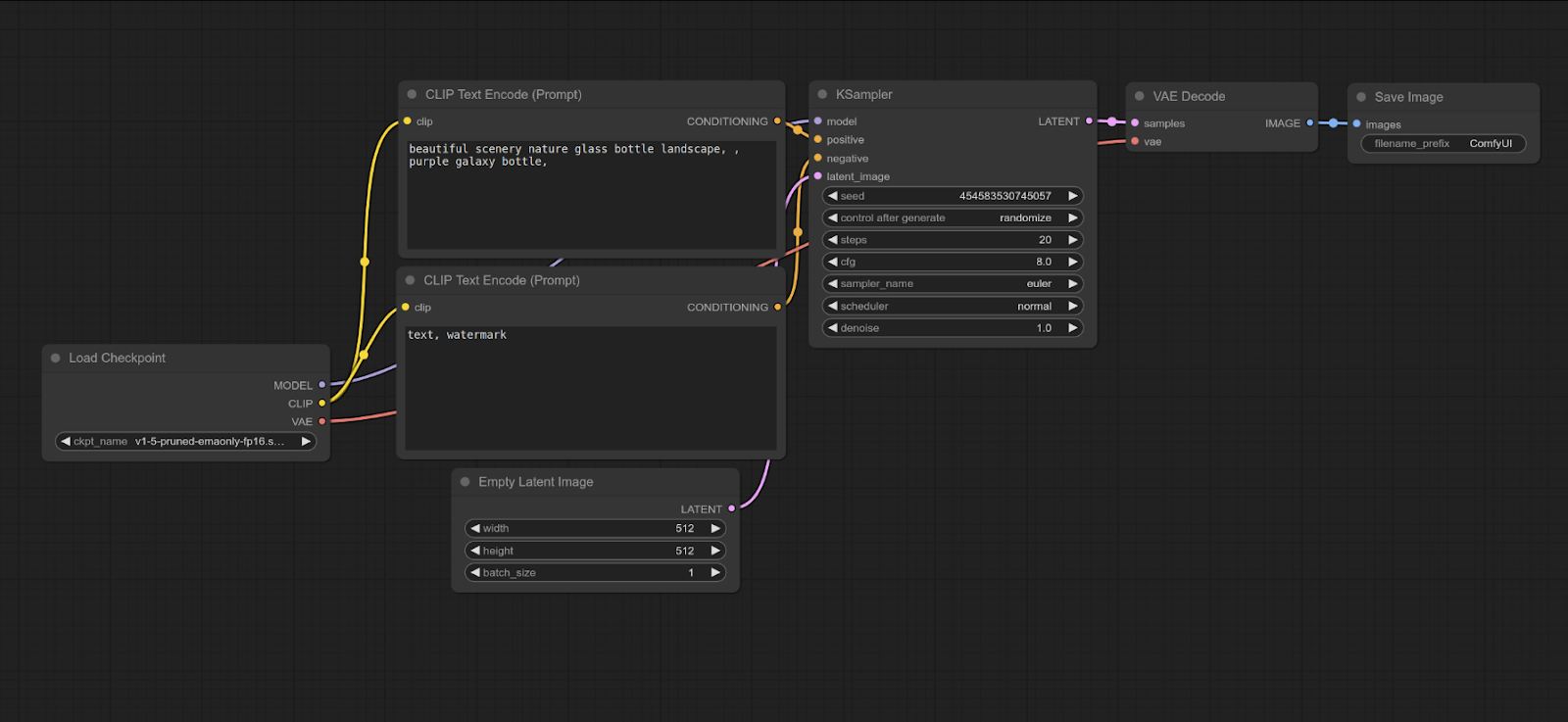
ComfyUi propose une pipeline d'exemple, pour de la génération d'images, voyons un peu quelles sont les nodes utilisées.
Note : Si rien ne s'affiche sur l'interface, vous pouvez aller dans :
Flux de travail => Parcourir les modèles => Basiques => Image generation.
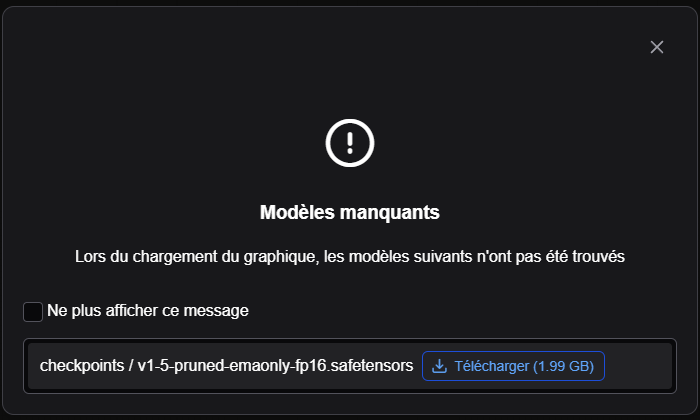
A ce moment là, il vous sera proposé de télécharger le modèle utilisé pour la génération :
Checkpoint :
Le point d'entrée de notre modèle de génération.

Ici c’est le modèle stable diffusion 1.5 qui est chargé, et a 3 sorties :
- Le modèle, qui sera relié à notre KSampler,
- le CLIP, qui correspond à nos prompts,
- Et VAE. Certains modèles ont besoin d’un VAE externe, mais d’autres ont leur VAE directement encodés dans le modèle, donc on peut l’utiliser d’ici :).
CLIP : (positive et negative) :
Permet d'écrire nos prompts, négatives et positives
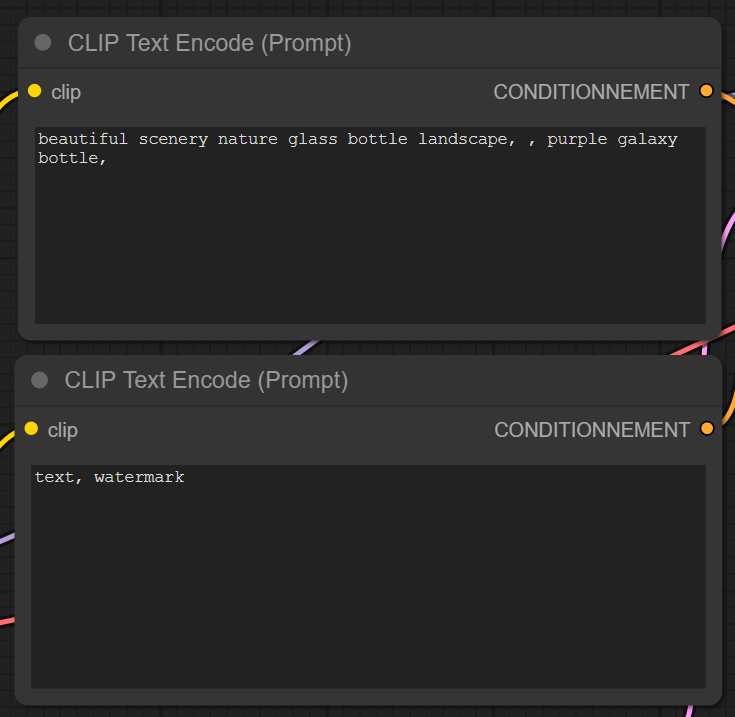
Note utile ici ! On peut utiliser le raccourci ctrl+ et ctrl - en surlignant un mot ou une expression, pour ajuster la prédominance de certains termes dans l'image. Plus celle-ci est haute, plus elle sera considérée importante dans la génération.
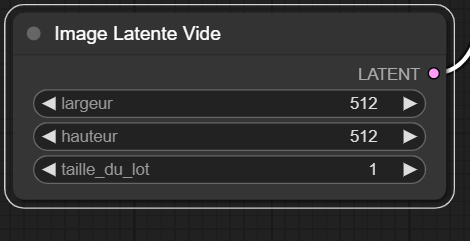
Latent :
Permet de définir une taille d'image, et un nombre d'images
KSampler:
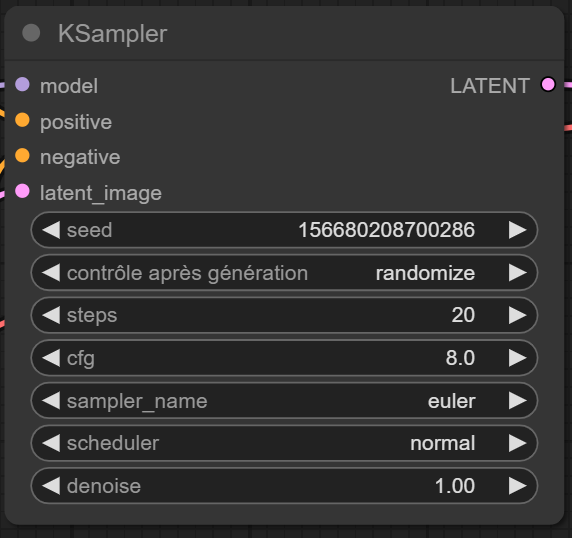
il s'agit de l'échantillonneur, ou bien le cœur du fonctionnement du workflow.
On peut contrôler l'opération de débruitage avec divers paramètres, que voici :
- Seed : Permet de fournir une valeur constante, Si on donne exactement la même prompt, avec la même seed, pour le même modèle utilisé, on obtiendra la même image. C'est plutôt pratique, si on désire avoir des dérivées d'images par exemple, (comme des poses différentes, une couleur de cheveux différente par exemple, etc)... Évidemment on peut choisir de la rendre aléatoire, à chaque génération ou non.
- Steps : Le nombre d'étapes pour le processus de débruitage. Plus on fournit d'étapes, plus l'image pourra être précise, mais plus la génération sera longue, car chaque itération coûte du temps de traitement.
- cfg : Donne un indice de créativité au modèle, plus il est haut, moins l'IA peut s'éloigner de la prompt et laisser de la place à l'aléatoire. Mais des valeurs trop élevées plombent ses performances.
- Sampler name: Permet d'utiliser des planificateurs de débruitage différents,généralement le laisser à Euler suffit. Si nécessaire, les pages de téléchargement de modèles fournissent des instructions à ce sujet.
- Denoise: Taux de débruitage, c’est utilisé surtout pour du image2image, ça sert à définir le taux de “respect” de l’ancienne image par rapport à la nouvelle, si elle est à 1, alors on ignore complètement l’autre image. Evidemment c’est inutile si on a une image latente vide, vu que c'est juste du flou ^^’).
VAE Decode :
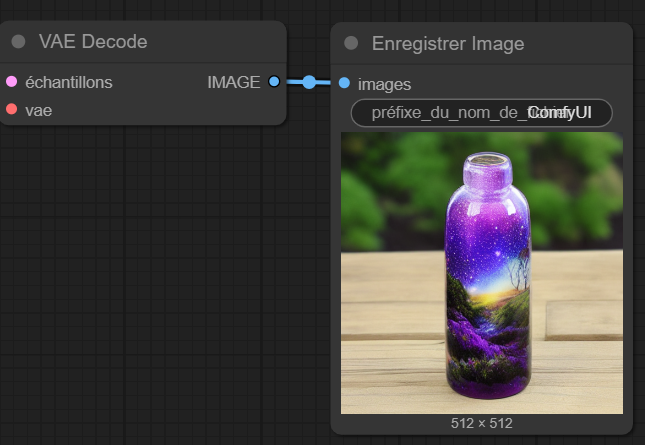
Permet de décoder l'image du latentSpace, en pixelSpace. Certains modèles ont déjà un VAE, d'autres en ont besoin d'un externe. C'est le cas des modèles "quantifiés" (une forme de compression de modèle) par exemple.
Notes utiles :
On peut convertir des valeurs de nodes en inputs, et inversement! ça peut être utile pour partager des informations, comme des modèles, des seeds, des VAE, ou des variables plus simples comme le nombre de steps par exemple ! (suffit de clic droit sur la valeur, pour la convertir dans un sens ou dans l'autre).
On peut aussi changer les couleurs des nodes, pour mieux organiser et visualiser les flows, tout comme on peut rajouter des groupes, via "new Group"
Conclusion :
ComfyUI offre une approche puissante et flexible pour la génération d'images par IA, en permettant un contrôle précis grâce à son interface basée sur des nodes. Bien qu'il nécessite une configuration matérielle adéquate pour des performances optimales, il ouvre un monde de possibilités créatives et techniques. De la compréhension des bases de Stable Diffusion à la manipulation des différents paramètres du KSampler, chaque étape du processus peut être ajustée pour obtenir des résultats personnalisés. Que vous soyez un artiste cherchant à affiner votre direction artistique ou un technicien explorant les subtilités de l'IA, ComfyUI est un outil précieux pour explorer et maîtriser la génération d'images. Avec un peu de patience et d'expérimentation, vous pouvez débloquer son plein potentiel et créer des images uniques et impressionnantes.




{kind=link}