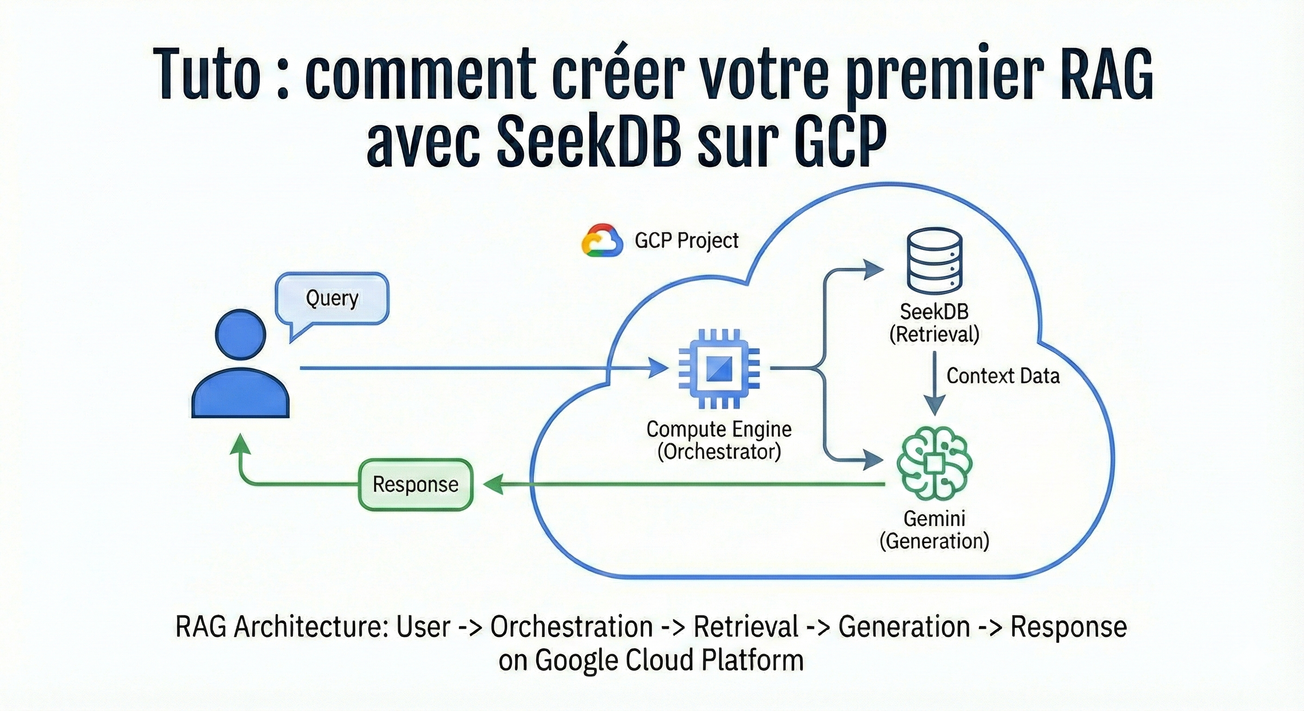
Le RAG, c'est quoi ?
Les LLM sont puissants, mais ils ont deux limites majeures : leurs connaissances s'arrêtent à leur date d'entraînement, et ils ne connaissent pas vos données. Le RAG (Retrieval-Augmented Generation) résout ce problème en ajoutant une étape de recherche avant la génération.
Prenons un exemple concret : Air France dispose de milliers de pages de documentation technique pour la maintenance de ses moteurs d'avion. Un technicien a besoin de trouver rapidement la procédure de remplacement d'une turbine. Plutôt que de chercher dans des PDF, il pose sa question en langage naturel et obtient une réponse précise, sourcée depuis la doc interne (pdf, numéro de page, section, etc.).
Le principe d'un RAG basique :
- Le technicien pose sa question
- L'outil recherche les passages pertinents dans la documentation technique
- On injecte ces passages dans le prompt du LLM
- Le LLM synthétise une réponse en s'appuyant sur ce contexte
Pour que cette recherche soit efficace, on utilise des embeddings (représentations vectorielles du texte) et une base capable de faire des recherches par similarité. C'est là qu'intervient SeekDB.
SeekDB : du SQL avec des vecteurs
SeekDB est une base de données toute nouvelle, sortie le 14 novembre 2025, développée par OceanBase.
Elle combine le meilleur des deux mondes : la puissance du SQL relationnel et le support natif des vecteurs.
Concrètement, on peut stocker des embeddings dans une colonne VECTOR, créer des index optimisés, et lancer des recherches de similarité — le tout avec une syntaxe SQL familière.
Pour notre cas Air France, ça signifie qu'on peut stocker les chunks de documentation avec leurs métadonnées (type de moteur, catégorie de maintenance, date de révision, pdf, numéro de page) et filtrer les résultats avec du SQL classique tout en cherchant par similarité sémantique.
Installation de l'environnement sur GCP
On crée une VM Ubuntu sur un e2-medium pour avoir minimum de 2 Go de mémoire pour SeekDB, avec Docker préinstallé.
PROJECT_ID="VOTRE_PROJET_ID"
ZONE="europe-west9-b"
VM_NAME="vm-seek-db-demo"
MACHINE_TYPE="e2-medium"
gcloud compute instances create $VM_NAME \
--project=$PROJECT_ID \
--zone=$ZONE \
--machine-type=$MACHINE_TYPE \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--boot-disk-size=30GB \
--boot-disk-type=pd-balanced \
--tags=db-server \
--metadata=startup-script='#!/bin/bash
apt update && apt install -y ca-certificates curl gnupg
mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" > /etc/apt/sources.list.d/docker.list
apt update && apt install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin
usermod -aG docker $(ls /home | head -1)
'
script de création d'une VM sur GCP
Vous pourrez à la fin de ce tutoriel, faire vos tests directement en ligne de commande depuis le Cloud Shell de GCP. Si vous souhaitez pouvoir accéder à SeekDB depuis l'extérieur (n8n par exemple), il faut ajouter deux règles de pare-feu pour exposer les ports MySQL (3306) et SeekDB (2881) uniquement sur le réseau interne GCP
gcloud compute firewall-rules create allow-mysql-internal \
--project=$VOTRE_PROJET_ID \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=10.0.0.0/8 \
--target-tags=db-server \
--description="Autorise MySQL depuis le réseau interne"
gcloud compute firewall-rules create allow-seekdb-internal \
--project=$VOTRE_PROJET_ID \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:2881 \
--source-ranges=10.0.0.0/8 \
--target-tags=db-server \
--description="Autorise SeekDB depuis le réseau interne"script de création des règles de pare-feu pour MySQL et SeekDB
Une fois connecté en SSH sur la VM créée, on lance ce script pour installer SeekDB + MySQL
#!/bin/bash
# =============================================================================
# Setup VM GCP : SeekDB + MySQL
# =============================================================================
set -e
echo "=========================================="
echo " Installation SeekDB + MySQL"
echo "=========================================="
# --- 1. Mise à jour système ---
echo "[1/5] Mise à jour du système..."
sudo apt update && sudo apt upgrade -y
# --- 2. Installation Docker ---
echo "[2/5] Installation de Docker..."
sudo apt install -y ca-certificates curl gnupg lsb-release
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin
sudo usermod -aG docker $USER
# --- 3. Installation MySQL client ---
echo "[3/5] Installation de MySQL client..."
sudo apt install -y mysql-client
# --- 4. Création des répertoires ---
echo "[4/5] Création des répertoires..."
mkdir -p ~/databases/mysql-data
cd ~/databases
# --- 5. Docker Compose ---
echo "[5/5] Création du docker-compose.yml..."
cat > docker-compose.yml << 'EOF'
services:
mysql:
image: mysql:8.0
container_name: mysql
restart: unless-stopped
environment:
MYSQL_ALLOW_EMPTY_PASSWORD: "yes"
MYSQL_DATABASE: testdb
ports:
- "3306:3306"
volumes:
- ./mysql-data:/var/lib/mysql
seekdb:
image: oceanbase/seekdb:latest
container_name: seekdb
restart: unless-stopped
ports:
- "2881:2881"
networks:
default:
name: db-network
EOF
echo ""
echo "=========================================="
echo " Installation terminée !"
echo "=========================================="script d'installation de SeekDB + MySQL
A cette étape on doit se déconnecter et se reconnecter à la VM pour avoir les droits sur docker. Puis on exécute docker compose :
cd ~/databases && docker compose up -dcommande pour démarrer les services définis dans le docker-compose.yml en arrière-plan
Vous pouvez vérifier que tout est OK dans les logs de SeekDB :
docker compose logs -f seekdbaffiche les logs du service SeekDB en continu
Et enfin pour pouvez vous connecter à la base SeekDB (sans mot de passe pour les tests) :
docker exec -it seekdb mysql -h127.0.0.1 -P2881 -urootcommande pour se connecter au shell SQL de SeekDB depuis l'intérieur du conteneur, en tant que root
On va créer une table pour nos tests :
create DATABASE seek_db_test;
use seek_db_test;script de création d'une table
La recherche par similarité
On va à présent créer une table similarite qui va contenir un texte et son vecteur. Ensuite, à partir d'une question, on va demander à SeekDB de nous remonter les phrases les plus proches et qui sont les plus en lien avec le contexte.
SeekDB propose de gérer automatiquement l'embedding en utilisant une clé API de Gemini (ou autres provider). Dans le cadre de cet article nous n'entrerons pas dans les détails au sujet des tailles de chunk et stratégies d'embedding.
Voici la configuration simplifiée pour nos tests :
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
'gemini_embed',
'{
"type": "dense_embedding",
"model_name": "text-embedding-004"
}'
);
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT(
'gemini_embed_endpoint',
'{
"ai_model_name": "gemini_embed",
"url": "https://generativelanguage.googleapis.com/v1beta/openai/embeddings",
"access_key": "votre_key_api_gemini",
"provider": "openai"
}'
);
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
'gemini_llm',
'{
"type": "completion",
"model_name": "gemini-2.5-flash"
}'
);
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT(
'gemini_llm_endpoint',
'{
"ai_model_name": "gemini_llm",
"url": "https://generativelanguage.googleapis.com/v1beta/openai/chat/completions",
"access_key": "votre_key_api_gemini",
"provider": "openai"
}'
);
CREATE TABLE similarite (
id INT AUTO_INCREMENT PRIMARY KEY,
phrase VARCHAR(500),
embedding VECTOR(768)
);création des call LLM et script de création de la table similarite
Nous insérons maintenant les phrases en utilisant l'outils d'embedding AI_EMBED :
INSERT INTO similarite (phrase, embedding) VALUES
('Le moteur de l avion a besoin d une revision', AI_EMBED('gemini_embed', 'Le moteur de l avion a besoin d une revision')),
('Il faut reparer le reacteur de l appareil', AI_EMBED('gemini_embed', 'Il faut reparer le reacteur de l appareil')),
('La turbine necessite une maintenance', AI_EMBED('gemini_embed', 'La turbine necessite une maintenance')),
('Je voudrais reserver un billet pour Paris', AI_EMBED('gemini_embed', 'Je voudrais reserver un billet pour Paris')),
('Le chat dort sur le canape', AI_EMBED('gemini_embed', 'Le chat dort sur le canape'));
ajout de données dans la table similarite
À présent voici la question :
SET @query_vec = AI_EMBED('gemini_embed', 'reparation moteur avion');stockage d'un vecteur dans une variable
On lance la recherche :
SELECT
phrase,
ROUND(L2_DISTANCE(embedding, @query_vec), 3) AS distance
FROM similarite
ORDER BY L2_DISTANCE(embedding, @query_vec)
LIMIT 5;requête de recherche de similarité
Et enfin les résultats de similarité :
+---------------------------------------------+----------+
| phrase | distance |
+---------------------------------------------+----------+
| Le moteur de l'avion a besoin d'une revision| 0.657 | ← très proche
| La turbine necessite une maintenance | 0.850 | ← proche (synonymes!)
| Il faut reparer le reacteur de l'appareil | 0.990 | ← assez proche
| Je voudrais reserver un billet pour Paris | 1.109 | ← hors sujet
| Le chat dort sur le canape | 1.145 | ← hors sujet
+---------------------------------------------+----------+
5 rows in set (0.01 sec)réponse de la requête de similarité
C'est magique : SeekDB comprend que "réacteur", "turbine" et "moteur" sont sémantiquement proches !
Si on compare avec une recherche SQL classique, on aura :
SELECT phrase FROM similarite WHERE phrase LIKE '%moteur%'; ← résultat une seule ligne : "Le moteur de l'avion a besoin d'une revision"requête SQL classique
On pourra à partir des résultats avec SeekDB, optimiser les chunks pour affiner la vectorisation et filtrer par distance :
SELECT phrase FROM similarite
WHERE L2_DISTANCE(embedding, @query_vec) < 1.000;
+---------------------------------------------+----------+
| phrase | distance |
+---------------------------------------------+----------+
| Le moteur de l'avion a besoin d'une revision| 0.657 |
| La turbine necessite une maintenance | 0.850 |
| Il faut reparer le reacteur de l'appareil | 0.990 |
+---------------------------------------------+----------+requête avec filtrage par distance
Pensez à optimiser les performances de votre RAG tout en maîtrisant vos coûts. Pour cela, je vous invite à lire mon article sur les tokens afin de mieux comprendre les grands principes.
Intégration des vecteurs dans le contexte du LLM
SeekDB propose aussi d'interroger un LLM à partir d'une question et d'un contexte :
-- 1. Stocker le contexte
SET @question = 'Quelles sont les infos que tu as sur nos avions?';
SET @q = AI_EMBED('gemini_embed', @question);
SET @ctx = (
SELECT GROUP_CONCAT(phrase SEPARATOR '\n---\n')
FROM (
SELECT phrase
FROM similarite
ORDER BY l2_distance(embedding, @q)
LIMIT 3
) AS docs
);
-- 2. Vérifier le contexte
SELECT @ctx AS contexte;
-- 3. Appeler le LLM
SELECT AI_COMPLETE(
'gemini_llm',
CONCAT(
'Tu es un assistant technique Air France.\n\n',
'Documentation:\n', @ctx, '\n\n',
'Question: ', @question, '\n\n',
'Reponse:'
)
) AS reponse;requête complète pour poser une question et avoir une réponse du LLM
La réponse magique de gemini :
Réponse: J'ai deux informations concernant nos avions :
* Le moteur d'un avion necessite une revision.
* La turbine d'un avion necessite une maintenance.réponse du LLM
Conclusion
SeekDB simplifie considérablement l'implémentation d'un pipeline RAG en intégrant directement les fonctions d'IA dans le moteur de base de données. Plus besoin de jongler entre plusieurs services : l'embedding, la recherche vectorielle et l'appel au LLM se font en quelques lignes de SQL.
SeekDB ouvre la voie à une nouvelle génération de bases de données "AI-native" où le SQL devient le langage d'orchestration des pipelines d'IA.
Le projet est encore jeune (v1.0) et certaines fonctionnalités restent à peaufiner, mais c'est clairement un outil à suivre de près. Pour une PME ou un développeur indépendant qui veut intégrer du RAG dans un projet sans monter une infrastructure complexe, SeekDB offre une solution pragmatique et accessible. À garder dans sa boîte à outils.







{kind=link}