Votre RAG retourne des réponses à côté de la plaque ? Avant de tout reconstruire, mesurez le problème avec RAGAS, puis appliquez les bons correctifs — du plus simple au plus avancé. Voici la méthode.
Introduction
Vous avez connecté vos documents à un LLM, envoyé votre première question... et la réponse est à côté de la plaque ! Le modèle invente des chiffres, cite un document qui ne répond pas à la question, ou pire, répond avec aplomb quelque chose de faux.
Bienvenue dans la réalité du RAG en production.
Le pipeline classique : découper des documents ➡ les transformer en vecteurs ➡ retrouver les top-k plus proches ➡ les injecter dans un prompt — fonctionne sur les démos. Trois PDF, des questions simples, des réponses convaincantes. Mais dès qu'on passe à 500 documents hétérogènes, des questions ambiguës et des utilisateurs qui ne formulent pas comme prévu... ça casse.
Le problème, c'est que ce pipeline fait confiance à chaque étape aveuglément. Comme chercher un livre dans une bibliothèque en ne lisant que les titres sur la tranche : parfois on tombe sur le bon, souvent on repart avec autre chose. Et personne ne vérifie...
Le réflexe classique, c'est de bricoler dans le mauvais ordre : ajouter des documents, retoucher le prompt, changer de modèle, augmenter top_k... sans jamais mesurer ce qui ne fonctionne pas. Le résultat est presque toujours le même : beaucoup d'itérations, peu de progrès, et une impression diffuse que "le RAG, c'est capricieux".
Cet article est le premier d'une série en deux parties. Voici ce qu'on va couvrir :
Partie 1 (cet article) — Diagnostiquer et poser les fondations :
- Comprendre pourquoi le RAG naïf casse (les 4 points de rupture)
- Mesurer avec RAGAS avant de corriger quoi que ce soit
- Corriger les fondations — données, chunking, embeddings — là où se jouent souvent les premiers gains
Partie 2 — Les techniques avancées :
- Corriger le pipeline (recherche hybride, reranking, HyDE, multi-query)
- Les approches correctives (CRAG, Self-RAG)
- et au-delà (GraphRAG, Agentic RAG)
Le RAG naïf — pourquoi ça casse
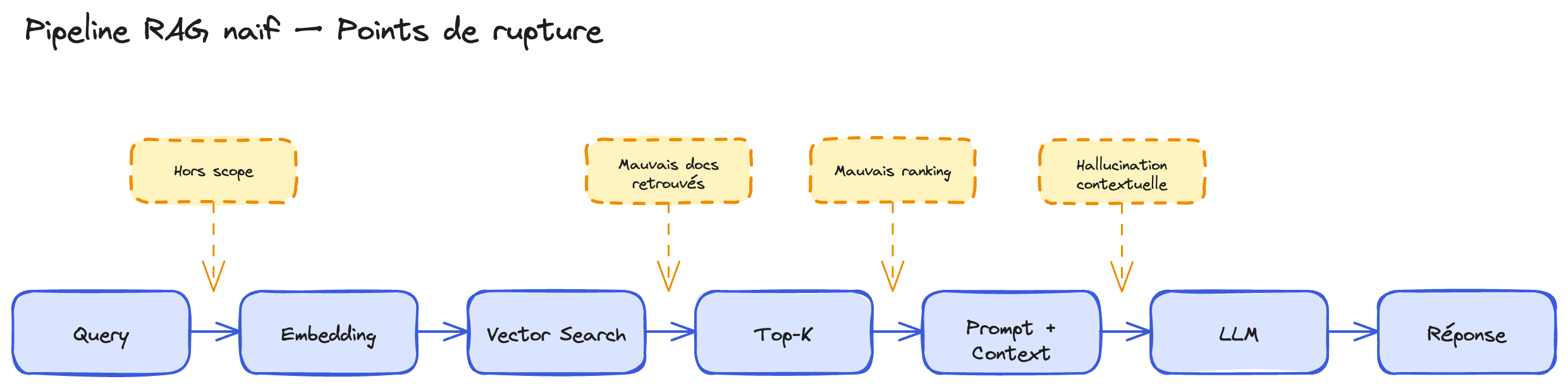
Avant de corriger quoi que ce soit, il faut comprendre où ça casse. Un pipeline RAG classique a quatre points de rupture. Les identifier permet de cibler le bon correctif au lieu de tout changer à l'aveugle.
1. Mauvais documents retrouvés
Le retriever ramène des documents qui ne répondent pas à la question. C'est le problème le plus fréquent.
Exemple : un employé demande "comment poser des congés exceptionnels ?". Le retriever remonte le document sur les congés payés classiques — les embeddings sont proches (même champ sémantique), mais le contenu ne correspond pas.
Le décalage vient souvent de la différence entre le vocabulaire de la question (court, informel) et celui du document (long, structuré, jargon RH). L'embedding de la question et celui du bon document ne sont pas assez proches dans l'espace vectoriel.
Diagnostic : les documents retournés parlent vaguement du sujet, mais pas du bon aspect.
2. Bons documents, mauvais ranking
Les documents pertinents sont dans les résultats de recherche — mais noyés en position 7 ou 12. Le top-k (souvent k=3 ou k=5) ne les inclut pas.
Exemple : pour la question "quelle est la politique de télétravail pour les managers ?", le retriever trouve 15 documents liés au télétravail. Le document spécifique aux managers est en position 9. Les 5 premiers parlent de la politique générale.
Le cosine similarity ne distingue pas la pertinence fine d'un document. Il mesure une proximité sémantique globale, pas un alignement précis avec l'intention de la question.
Diagnostic : la réponse est générique alors qu'une réponse précise existait dans la base.
3. Bons documents, mauvaise réponse
Le retriever a fait son travail. Les bons documents sont dans le contexte. Mais le LLM génère quand même une réponse incorrecte.
Exemple : le contexte contient deux chunks — l'un dit "les frais de déplacement sont remboursés sous 30 jours", l'autre dit "les notes de frais doivent être soumises sous 15 jours". Le LLM fusionne les deux et répond "les frais sont remboursés sous 15 jours".
C'est de l'hallucination contextuelle : le modèle mélange, extrapole ou reformule au-delà de ce que les documents disent réellement. Plus le contexte est long et dense, plus le risque augmente.
Diagnostic : la réponse semble plausible mais contredit ou déforme les documents sources.
4. Rien de pertinent dans la base
La question sort du périmètre de la documentation. Le RAG ne le sait pas et fabrique une réponse à partir de bribes vaguement liées, ou pire... à partir de ses connaissances générales.
Exemple : un employé demande "est-ce que l'entreprise propose un plan d'épargne retraite ?". Aucun document n'en parle. Le retriever remonte quand même les 5 chunks les plus proches (avantages sociaux, mutuelle...) et le LLM improvise une réponse à partir de ces fragments.
Le pipeline RAG naïf n'a aucun mécanisme de garde-fou. Il retourne toujours k documents, même quand aucun n'est pertinent. Et le LLM, alimenté par ce contexte hors sujet, génère une réponse confiante mais fausse.
Diagnostic : la réponse est inventée, le sujet n'existe pas dans la base documentaire.
Ces quatre points de rupture ne sont pas exclusifs, ils se combinent souvent. Mais les identifier séparément permet de mesurer chacun, et c'est exactement ce qu'on va faire avec RAGAS.
Étape 1 — Mesurez avant de corriger
On ne corrige pas ce qu'on ne mesure pas. C'est vrai pour le code (tests unitaires), pour la production (monitoring), et c'est vrai pour le RAG. Pourtant, la plupart des développeurs itèrent au feeling : "la réponse a l'air mieux, on continue".
C'est là qu'intervient RAGAS. C'est un framework open-source Python dédié à l'évaluation des pipelines RAG. Le principe : au lieu de juger manuellement si "la réponse a l'air correcte", RAGAS utilise un LLM comme juge pour noter automatiquement chaque étape de votre pipeline — retrieval et génération — avec des scores reproductibles.
On va se concentrer sur quatre métriques clés, chacune ciblant un des points de rupture qu'on vient de voir.
Les 4 métriques
| Métrique | Ce qu'elle mesure | Si elle est basse... | Point de rupture |
|---|---|---|---|
| Context Precision | Parmi les docs retrouvés, quelle proportion est pertinente ? | Le retriever ramène trop de bruit | #2 — Bons docs, mauvais ranking |
| Context Recall | A-t-on retrouvé tous les docs pertinents ? | Des documents clés manquent dans les résultats | #1 — Mauvais docs retrouvés |
| Faithfulness | La réponse est-elle fidèle aux documents fournis ? | Le LLM invente ou déforme | #3 — Bons docs, mauvaise réponse |
| Answer Relevancy | La réponse répond-elle vraiment à la question posée ? | La réponse est hors sujet, incomplète ou trop vague | #4 — Réponse peu utile pour l'utilisateur |
Pour simplifier : les deux premières métriques évaluent le retrieval (est-ce qu'on a trouvé les bons documents ?), les deux dernières évaluent la génération (est-ce que le LLM a bien répondu avec ce qu'on lui a donné ?).
Mise en place
RAGAS utilise un LLM comme juge pour évaluer les réponses de votre pipeline. Voici un setup minimal avec Gemini :
pip install ragas google-genai datasets jsonrefInstallation des dépendances RAGAS et du client Gemini
import os
from datasets import Dataset
from google import genai
from ragas import evaluate
from ragas.metrics import ContextPrecision, ContextRecall, Faithfulness, AnswerRelevancy
from ragas.llms import llm_factory
from ragas.embeddings import GoogleEmbeddings
class RagasGoogleEmbeddingsAdapter:
"""Compatibilité RAGAS 0.4.x pour AnswerRelevancy."""
def __init__(self, inner):
self.inner = inner
def embed_query(self, text):
return self.inner.embed_text(text)
def embed_documents(self, texts):
return self.inner.embed_texts(texts)
# LLM et embeddings — Gemini (n'importe quel provider fonctionne)
client = genai.Client(api_key=os.environ["GOOGLE_API_KEY"])
llm = llm_factory("gemini-2.5-flash", provider="google", client=client)
raw_embeddings = GoogleEmbeddings(client=client, model="gemini-embedding-001")
embeddings = RagasGoogleEmbeddingsAdapter(raw_embeddings)
# Dataset d'évaluation — vos questions, les docs retrouvés, les réponses générées
dataset = Dataset.from_dict(
{
"question": [
"Comment poser des congés exceptionnels ?",
],
"answer": [
"Pour poser des congés exceptionnels, faites une demande via "
"l'outil RH en joignant un justificatif. Vous avez droit à 4 "
"jours pour un mariage, 3 jours pour une naissance.",
],
"contexts": [[
"Les congés exceptionnels sont accordés pour mariage (4 jours), "
"naissance (3 jours), décès d'un proche (3 jours). La demande "
"se fait via l'outil RH avec justificatif.",
]],
"ground_truth": [
"Les congés exceptionnels se demandent via l'outil RH avec "
"justificatif. Durées : mariage 4j, naissance 3j, décès 3j.",
],
}
)
# Évaluation
results = evaluate(
dataset=dataset,
metrics=[
ContextPrecision(llm=llm),
ContextRecall(llm=llm),
Faithfulness(llm=llm),
AnswerRelevancy(llm=llm, embeddings=embeddings),
],
# Évite les NaN silencieux en cas de quota, auth ou problème réseau
raise_exceptions=True,
show_progress=False,
)
print(results)
# {'context_precision': 1.0, 'context_recall': 1.0, 'faithfulness': 1.0, 'answer_relevancy': 0.81}Configuration complète de RAGAS avec Gemini comme LLM évaluateur
Le reference est la réponse attendue (ground truth). C'est la partie la plus coûteuse à produire : il faut des paires question/réponse validées par un humain. Commencez avec 20-30 exemples représentatifs de vos cas d'usage réels : ce n'est pas statistiquement parfait, mais c'est largement suffisant pour faire émerger les premiers problèmes.
Exemple de lecture sur un petit jeu de tests
Prenons un cas simple : vous constituez un jeu de 25 questions réelles issues de votre support interne. Vous lancez RAGAS et obtenez :
context_precision = 0.41
context_recall = 0.78
faithfulness = 0.89
answer_relevancy = 0.67
Exemple de scores RAGAS sur un jeu de 25 questions
Comment lire ça ?
context_recallcorrect +context_precisionfaible : les bons documents sont souvent retrouvés, mais noyés dans trop de bruitfaithfulnessplutôt bon : quand le LLM a la bonne matière, il l'utilise correctementanswer_relevancymoyenne : la réponse reste souvent trop large ou pas assez ciblée
Dans ce cas, le vrai problème n'est probablement pas le modèle. Il faut d'abord travailler le retrieval : qualité des chunks, metadata, top-k, puis éventuellement reranking. Changer de LLM à ce stade risque surtout de masquer le problème.
Comment lire les résultats
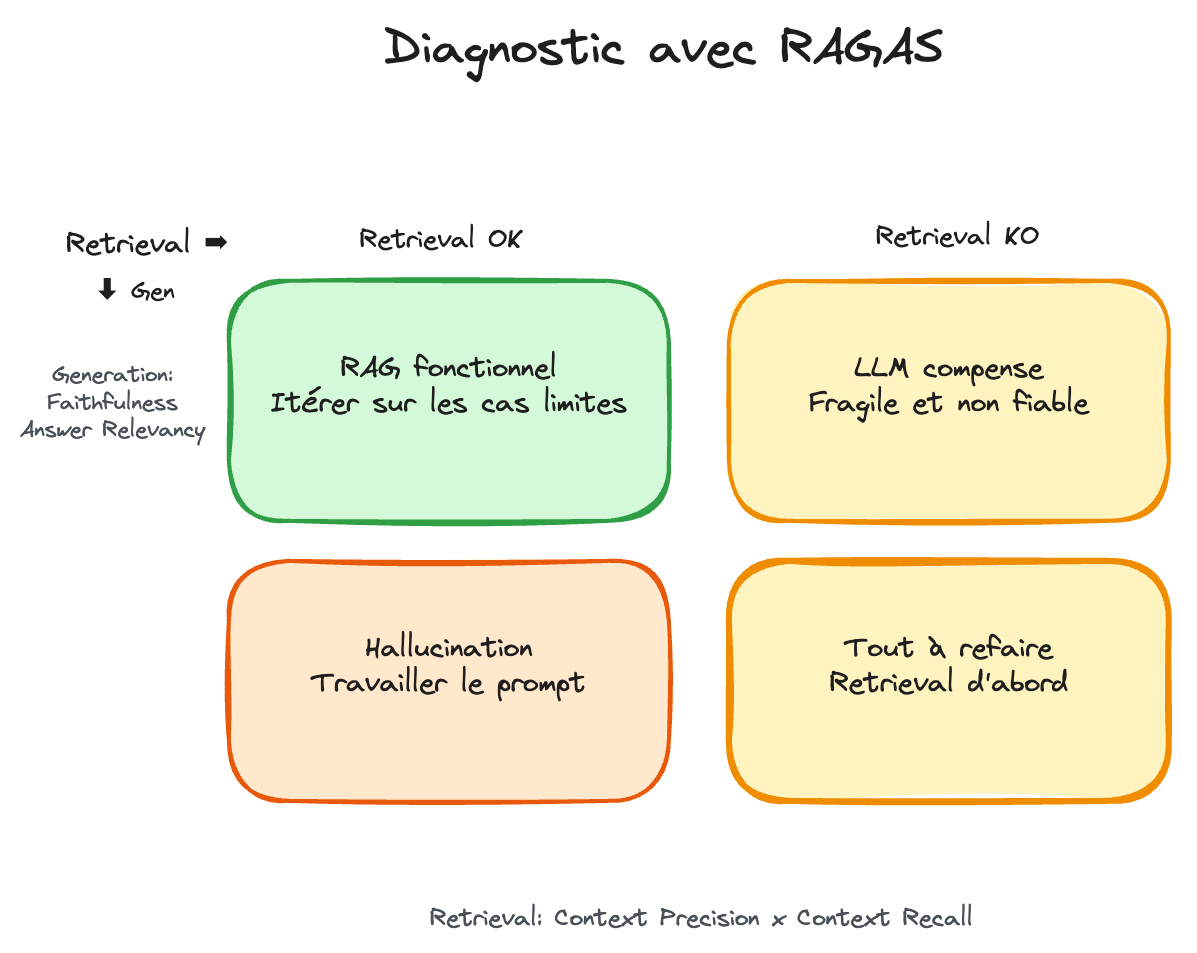
Deux axes, quatre quadrants :
- Retrieval OK + Generation OK → votre RAG fonctionne, itérez sur les cas limites
- Retrieval KO + Generation OK → le LLM compense un mauvais retrieval avec ses connaissances — c'est fragile et non fiable
- Retrieval OK + Generation KO → les bons docs sont là mais le LLM hallucine — travaillez le prompt ou le modèle
- Retrieval KO + Generation KO → commencez par le retrieval, c'est la priorité
En pratique : corrigez d'abord le retrieval dans la majorité des cas. Un LLM ne peut pas bien répondre avec de mauvais documents. À l'inverse, avec les bons documents, il peut déjà produire une réponse correcte sans prompt engineering sophistiqué.
Maintenant que vous savez où ça casse, voyons comment corriger, en commençant par ce qui a le plus d'impact.
Étape 2 — Corriger les fondations
Vous avez vos métriques RAGAS. Avant de modifier le pipeline (recherche hybride, reranking...), commencez par ce qui a généralement le plus d'impact avec le moins d'effort : la qualité des données, le chunking, et le choix de l'embedding.
La qualité des données
C'est le levier le moins sexy et le plus efficace. Si vos documents sont mal structurés, aucun algorithme de retrieval ne compensera.
Les problèmes classiques sur une base documentaire d'entreprise :
- Du bruit dans les documents : headers, footers répétés sur chaque page, tables des matières, numéros de page. Un PDF de 50 pages avec le même header "Politique RH — Confidentiel" injecte ce texte dans des dizaines de chunks → du bruit pur pour le retriever
- Pas de metadata : un chunk qui dit "la durée est de 3 jours" sans savoir qu'il vient du document "Congés exceptionnels" perd tout son contexte. Enrichissez chaque chunk avec : titre du document source, catégorie, date de dernière mise à jour
- Extraction brute depuis PDF : les tableaux deviennent du texte illisible, les listes perdent leur structure, les images avec du texte sont ignorées. Utilisez des extracteurs spécialisés (comme Document AI sur GCP) plutôt qu'un simple
PyPDF2
Voici un exemple typique de chunk inutilisable :
...la durée est de 3 jours. Voir annexe 4.
Politique RH - Confidentiel - v2.1
Page 12 sur 38
Chunk brut extrait d'un PDF — bruit de pagination et absence de contexte
Et sa version exploitable après nettoyage + enrichissement :
Document: Congés exceptionnels
Catégorie: RH
Dernière mise à jour: 2025-11-03
En cas de décès d'un proche, le salarié dispose de 3 jours de congé exceptionnel.
Même contenu, nettoyé et enrichi avec des metadata exploitables par le retriever
Le contenu métier est le même. Mais du point de vue d'un retriever, ces deux chunks n'ont rien à voir.
Le chunking — là où ça se joue
Le chunking, c'est la façon dont vous découpez vos documents avant de les transformer en vecteurs. Un mauvais chunking sabote tout le reste : l'embedding représente un bout de texte incohérent, et le retriever ne peut pas retrouver ce qui n'a jamais été correctement indexé.
Le problème du chunking naïf : découper à taille fixe (500 caractères, par exemple) coupe au milieu d'une phrase, sépare une question de sa réponse, ou isole un paragraphe de son titre. Le chunk résultant n'a pas de sens en isolation.
Trois stratégies, par ordre de sophistication :
- Recursive — le bon défaut. On découpe d'abord par sections (
\n\n), puis par paragraphes (\n), puis par phrases (.). Chaque niveau ne s'active que si le chunk dépasse la taille cible. La structure du document est préservée autant que possible.
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
separators=["\n\n", "\n", ". ", " "],
)
chunks = splitter.split_text(document)
Chunking récursif avec LangChain — découpe hiérarchique par sections, paragraphes, puis phrases
- Semantic — guidé par le sens. Au lieu de couper sur des caractères, on calcule la similarité sémantique entre phrases consécutives. Quand le sujet change (la similarité chute), on coupe. Plus coûteux (un appel d'embedding par phrase), mais les chunks sont sémantiquement cohérents.
from langchain_experimental.text_splitter import SemanticChunker
from langchain_google_vertexai import VertexAIEmbeddings
embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001")
splitter = SemanticChunker(embeddings, breakpoint_threshold_type="percentile")
chunks = splitter.create_documents([document])
Chunking sémantique avec Vertex AI Embeddings — coupe quand le sujet change
- Avec overlap — quelle que soit la stratégie, ajoutez un chevauchement entre chunks (10-20% de la taille). Un chunk qui commence par "Dans ce cas, le remboursement est de..." n'a aucun sens sans la phrase d'avant. L'overlap garantit qu'on ne perd pas le fil.
La règle d'or : la taille de vos chunks doit correspondre à la granularité des questions de vos utilisateurs. Des questions précises ("quel est le délai de carence ?") → des chunks courts (300-500 tokens). Des questions larges ("explique-moi la politique de mobilité interne") → des chunks plus longs (800-1200 tokens).
Un bon signal d'alerte : si vos réponses citent souvent le bon document mais ratent le bon paragraphe, votre chunking est probablement trop grossier. Si au contraire les réponses manquent de contexte et semblent "couper une phrase en deux", vos chunks sont probablement trop petits ou sans overlap suffisant.
chunk_size (défaut : 1024 tokens) et chunk_overlap (défaut : 256 tokens). Si vous utilisez ce service, ajustez ces paramètres plutôt que de gérer le chunking vous-même.Le choix du modèle d'embedding
Le modèle d'embedding transforme vos chunks en vecteurs. Deux chunks sémantiquement proches doivent produire des vecteurs proches. Si le modèle ne capture pas bien le sens de vos documents, le retriever échoue avant même de chercher.
Le réflexe : consulter le MTEB Leaderboard (Massive Text Embedding Benchmark), une bonne référence pour comparer les modèles d'embedding sur des dizaines de jeux de données de retrieval, classification et clustering. Mais n'en faites pas une vérité absolue : un leaderboard généraliste ne remplace pas une évaluation sur vos documents.
| Modèle | Dimensions | Type | À noter |
|---|---|---|---|
| gemini-embedding-001 (Google) | jusqu'à 3072 | API managée | Modèle Google recommandé pour l'anglais, le multilingue et le code |
| text-multilingual-embedding-002 (Google) | jusqu'à 768 | API managée | Option spécialisée pour les cas multilingues |
| text-embedding-005 (Google) | jusqu'à 768 | API managée | Spécialisé anglais et code, moins adapté comme choix par défaut pour un corpus français |
Quelques repères :
- Plus de dimensions ≠ toujours mieux. Un modèle plus compact mais bien adapté à votre domaine peut battre un modèle plus gros sur votre corpus
- Dense vs sparse : les embeddings denses (ceux du tableau) capturent le sens global. Les embeddings sparse (type BM25) capturent les mots exacts. On verra en partie 2 comment les combiner
- Le vrai test : évaluez sur vos données avec RAGAS. Un modèle excellent sur un benchmark public peut être médiocre sur du jargon RH français
gemini-embedding-001. Si vous cherchez une option plus ciblée sur le multilingue, comparez-la à text-multilingual-embedding-002. Gardez text-embedding-005 surtout pour des usages anglais ou orientés code.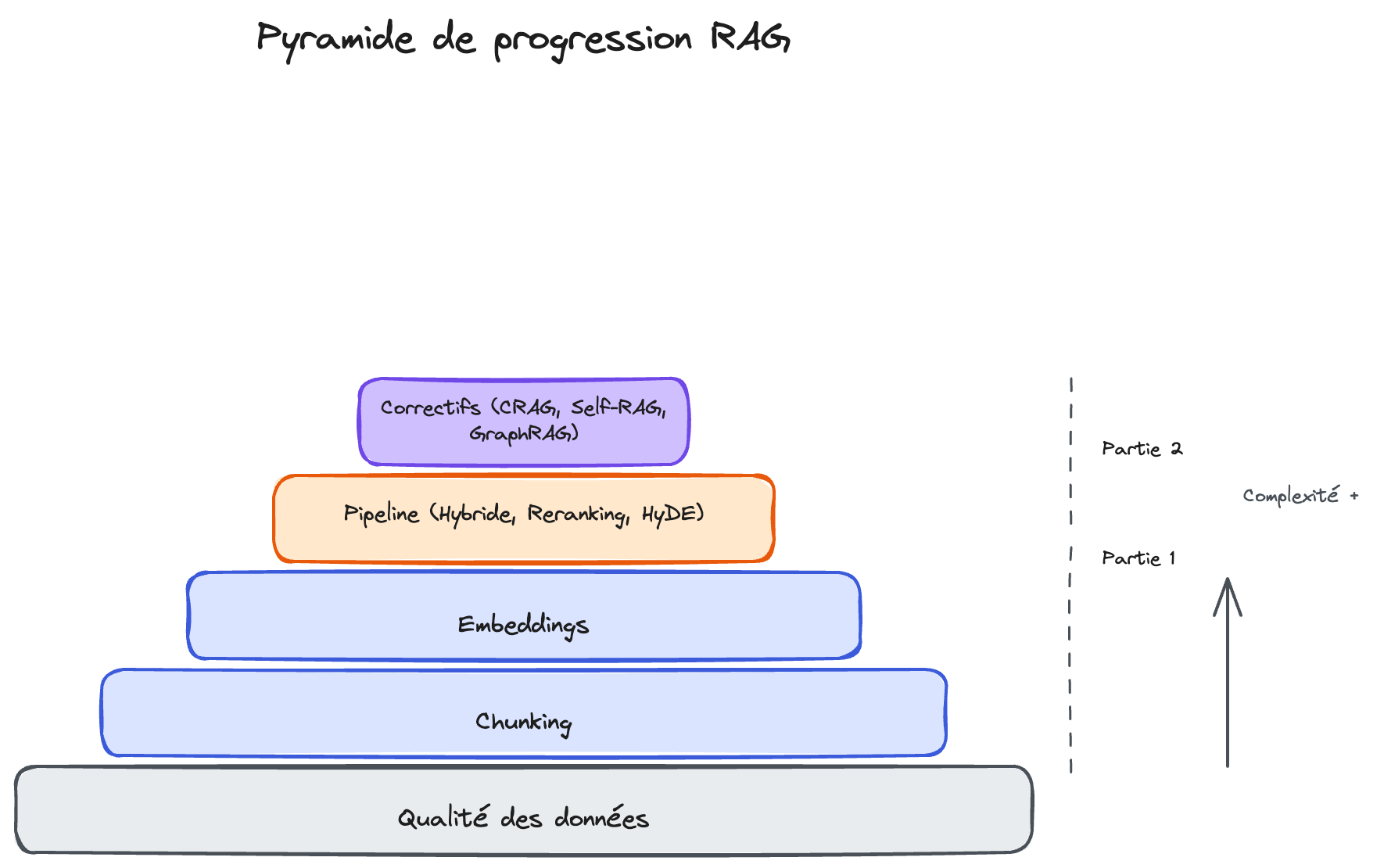
Conclusion
Récapitulons le chemin parcouru :
- Comprendre les 4 points de rupture d'un RAG naïf → pour savoir où chercher
- Mesurer avec RAGAS → pour transformer des impressions en données
- Corriger les fondations → données propres, chunking adapté, embeddings évalués
Ces trois étapes ne sont pas spectaculaires. Pas de nouvelle architecture, pas d'algorithme dernier cri. Mais c'est précisément là que se jouent les premiers gains. Dans la pratique, un RAG avec des données propres et un chunking adapté bat très souvent une pipeline plus sophistiqué construit sur des fondations bancales.
Si après ces corrections vos métriques RAGAS sont toujours basses : Context Precision qui stagne, Context Recall insuffisant, Faithfulness fragile, alors il est temps de toucher au pipeline lui-même.
Dans la partie 2, on passe aux techniques avancées :
- Recherche hybride (BM25 + vecteurs) pour ne plus rater les correspondances lexicales
- Reranking avec cross-encoder pour un classement précis des résultats
- HyDE et multi-query pour combler le fossé entre questions courtes et documents longs
- CRAG et Self-RAG des approches correctives où le RAG sait quand il se trompe
- GraphRAG et Agentic RAG pour aller au-delà du retrieve-and-generate
Le fil conducteur reste le même : mesurer, identifier, corriger. Pas empiler des techniques "parce qu'elles ont l'air avancées" et RAGAS vous aide justement à garder cette discipline.
Par où commencer dès maintenant ? Lancez RAGAS sur 20 exemples représentatifs, identifiez votre quadrant (retrieval vs generation), et commencez par les fondations. Vous serez surpris de ce que des données propres et un bon chunking peuvent débloquer avant même de toucher au pipeline.
Sources :





{kind=link}