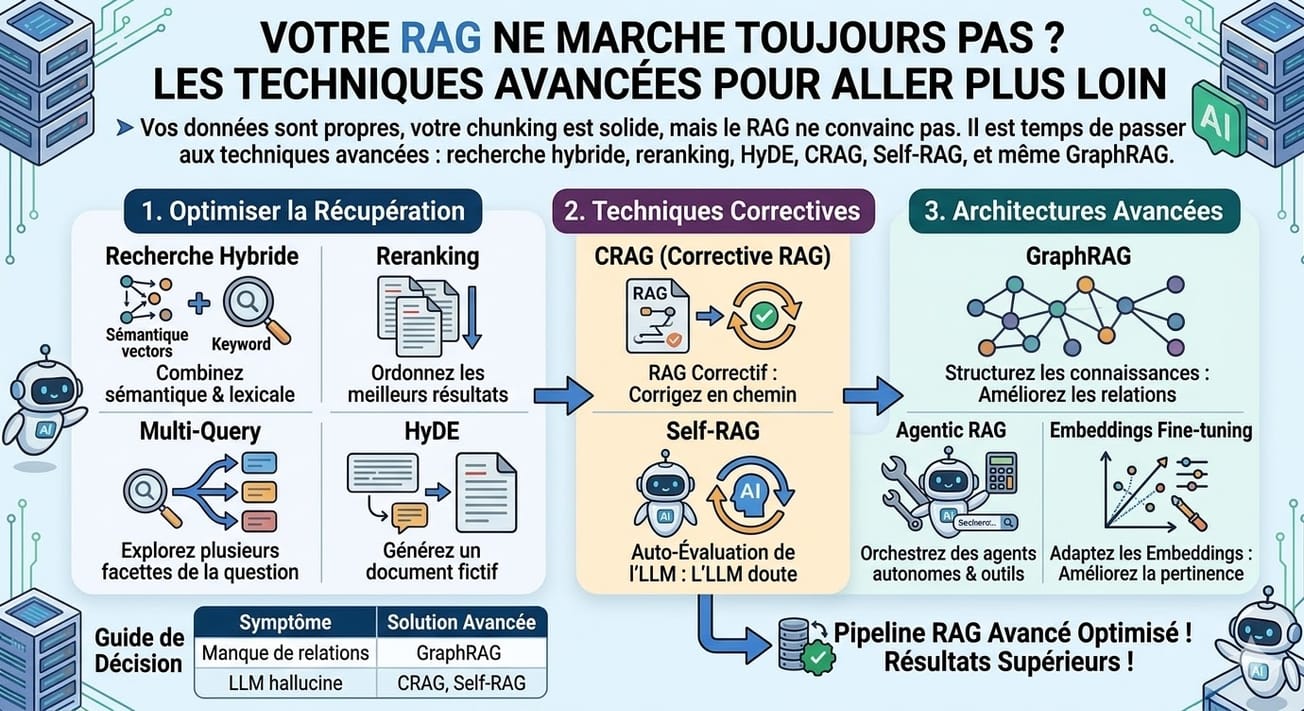
Vos données sont propres, votre chunking est solide, mais le RAG ne convainc pas. Il est temps de passer aux techniques avancées : recherche hybride, reranking, HyDE, CRAG, Self-RAG, et même GraphRAG.
Introduction
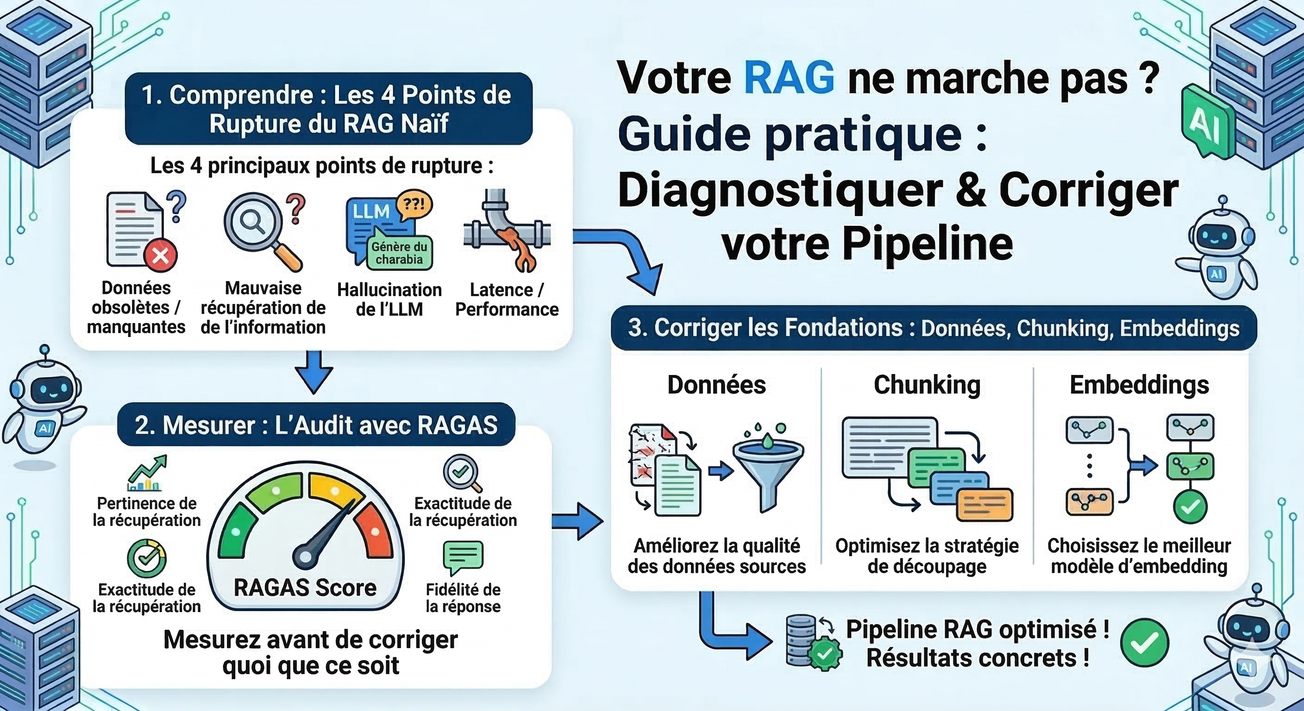
Dans la première partie, on a posé les bases : identifier les 4 points de rupture d'un RAG naïf, mesurer avec RAGAS, puis corriger les fondations — données, chunking, embeddings.
Pour rappel, les étapes 1 et 2 couvraient : nettoyer vos données sources et optimiser le chunking (étape 1), puis choisir et évaluer vos embeddings avec RAGAS (étape 2).
Si vous avez fait ce travail et que vos métriques RAGAS progressent mais stagnent, c'est normal. Les fondations ne suffisent pas toujours. Certains problèmes nécessitent de modifier le pipeline lui-même.
Dans cette deuxième partie, on monte en puissance :
- Corriger le pipeline — recherche hybride, reranking, HyDE, multi-query
- Les approches correctives — CRAG et Self-RAG, quand le RAG apprend à douter
- Au-delà du RAG classique — GraphRAG, Agentic RAG, fine-tuning des embeddings
- Guide de décision — quelle technique pour quel symptôme
Même logique que la partie 1 : on mesure avec RAGAS, on identifie le problème, on applique le bon correctif.
Étape 3 — Corriger le pipeline RAG
Les fondations sont solides mais les métriques plafonnent. Le problème n'est plus dans vos données — c'est dans la façon dont le pipeline les cherche et les classe. Quatre techniques permettent d'améliorer le retrieval sans tout réécrire. Le but, à ce stade, n’est pas de "tester des techniques avancées" pour le principe. Le but est de choisir le bon levier en fonction du symptôme observé dans la partie 1.
Si votre Context Recall reste basse, cela veut dire qu’une partie des documents pertinents n’arrive toujours pas jusqu’au modèle : il faut élargir ou diversifier la recherche : avec la recherche hybride, le multi-query, ou HyDE par exemple.
Si votre Context Precision est basse, les bons documents sont peut-être déjà présents, mais noyés dans trop de bruit : le problème n’est pas de retrouver plus large, mais de mieux classer : c’est exactement le rôle du reranking.
Les quatre approches ci-dessous répondent à deux besoins différents :
- retrouver des documents que le retrieval sémantique seul laisse passer ;
- mieux ordonner les documents déjà retrouvés pour remonter les plus pertinents en tête.
C’est cette logique qui permet d’éviter le piège classique du RAG avancé : ajouter de la complexité sans corriger le vrai problème.
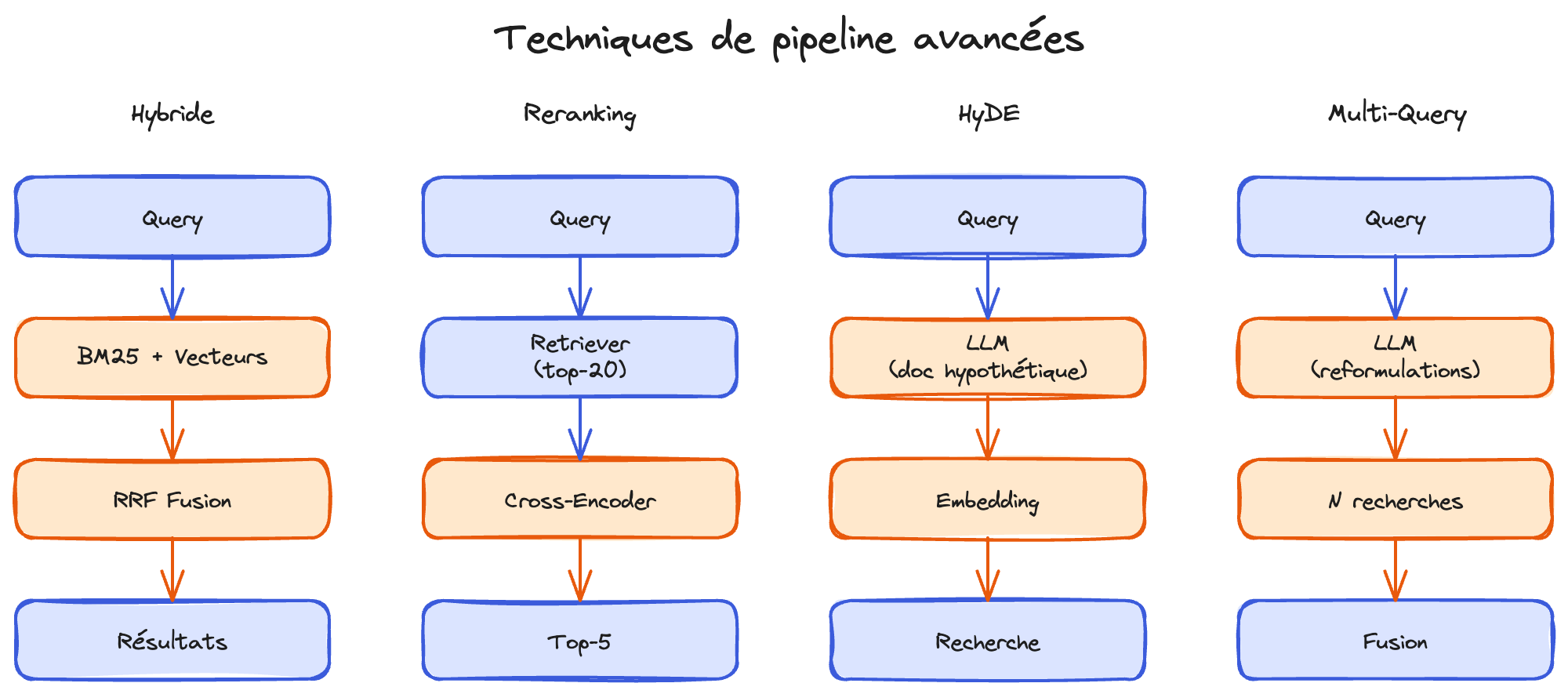
Recherche hybride : BM25 + vecteurs
Le problème : la recherche vectorielle capture le sens global, mais rate les correspondances lexicales exactes. Un employé cherche "formulaire AT-3B" — le retriever sémantique remonte des documents sur les accidents du travail en général, mais pas celui qui contient exactement "AT-3B".
Le principe : combiner deux types de recherche en parallèle. BM25 (lexical) retrouve les correspondances exactes de mots. La recherche vectorielle (sémantique) retrouve les concepts proches. Les résultats sont fusionnés via Reciprocal Rank Fusion (RRF) — un algorithme qui combine les classements sans avoir besoin d'un score commun.
Comme chercher un livre par son titre exact ET par son thème en même temps. Chaque méthode compense les faiblesses de l'autre.
Avec Vertex AI RAG Engine, la recherche hybride se configure directement dans le retrieval :
from vertexai import rag
retrieval_config = rag.RagRetrievalConfig(
top_k=10,
# alpha : 0.0 = full BM25 (lexical), 1.0 = full vecteurs (sémantique)
hybrid_search=rag.HybridSearch(alpha=0.5),
)
response = rag.retrieval_query(
rag_resources=[rag.RagResource(rag_corpus=CORPUS_NAME)],
text="formulaire AT-3B accident du travail",
rag_retrieval_config=retrieval_config,
)
Recherche hybride avec Vertex AI RAG Engine — alpha=0.5 pour un équilibre BM25/sémantique
alpha à 0.5 donne un poids égal aux deux approches. En pratique, commencez par 0.5, puis ajustez : montez vers 0.7 si vos questions sont conceptuelles, descendez vers 0.3 si elles contiennent souvent des codes, acronymes ou noms propres.HyDE — générer un faux document pour mieux chercher
Le problème : une question courte ("congés maladie longue durée ?") produit un embedding très différent d'un document détaillé de 500 mots sur le sujet. Le fossé sémantique entre la question et le document cible est trop large.
Le principe : avant de chercher, demander au LLM de générer un document hypothétique qui répondrait à la question. Ce faux document, même imparfait, ressemble bien plus aux vrais documents de votre base. On utilise son embedding pour la recherche à la place de celui de la question.
import os
import google.generativeai as genai
from vertexai.language_models import TextEmbeddingModel
# 1. Générer un document hypothétique
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
model = genai.GenerativeModel("gemini-2.5-flash")
prompt = """Génère un extrait de document RH interne qui répondrait
à cette question : {query}
Écris comme un document d'entreprise, pas comme une réponse conversationnelle."""
hypothetical_doc = model.generate_content(
prompt.format(query="congés maladie longue durée ?")
).text
# 2. Embedder le document hypothétique (pas la question)
embedding_model = TextEmbeddingModel.from_pretrained("text-embedding-001")
hyde_embedding = embedding_model.get_embeddings([hypothetical_doc])[0].values
# 3. Chercher avec cet embedding dans votre vector store
# Remplacez par votre client (Vertex AI Vector Search, Pinecone, Weaviate...)
results = vector_store.search(hyde_embedding, top_k=10)
Multi-Query — reformuler pour couvrir plus large
Le problème : une seule formulation de question ne capture qu'un seul angle. "Comment fonctionne le télétravail ?" pourrait chercher la politique, les outils, la fréquence autorisée, ou la procédure de demande.
Le principe : le LLM génère 3 à 5 reformulations de la question originale, chacune sous un angle différent. On lance une recherche par reformulation, puis on fusionne et déduplique les résultats. Le retrieval couvre ainsi un périmètre plus large.
import google.generativeai as genai
from vertexai import rag
model = genai.GenerativeModel("gemini-2.5-flash")
# 1. Générer des reformulations
prompt = """Génère 3 reformulations de cette question, chacune sous un angle différent.
Retourne uniquement les questions, une par ligne.
Question : {query}"""
original_query = "Comment fonctionne le télétravail ?"
reformulations = model.generate_content(
prompt.format(query=original_query)
).text.strip().split("\n")
# 2. Rechercher pour chaque reformulation
all_results = []
for query in [original_query] + reformulations:
results = rag.retrieval_query(
rag_resources=[rag.RagResource(rag_corpus=CORPUS_NAME)],
text=query,
rag_retrieval_config=rag.RagRetrievalConfig(top_k=5),
)
all_results.extend(results.contexts.contexts)
# 3. Dédupliquer et fusionner (RRF ou simple déduplication)
unique_results = deduplicate(all_results)
Multi-Query avec Gemini — 3 reformulations par question pour un retrieval plus large
Cross-Encoder Reranking
Le problème : le classement par cosine similarity est approximatif. Le bi-encoder (utilisé pour l'embedding) encode la question et le document séparément — il ne peut pas comparer finement leur relation.
Le principe : un pipeline en deux étapes. D'abord, le retriever classique ramène un large ensemble de candidats (top-20). Ensuite, un cross-encoder analyse chaque paire (question, document) ensemble et produit un score de pertinence beaucoup plus précis. On ne garde que le top-5.
L'analogie : le bi-encoder lit les CV en diagonale pour faire une première sélection. Le cross-encoder fait passer un entretien à chaque candidat retenu.
Vertex AI propose un Ranking API intégré au RAG Engine :
from vertexai import rag
retrieval_config = rag.RagRetrievalConfig(
top_k=15,
hybrid_search=rag.HybridSearch(alpha=0.5),
ranking=rag.Ranking(
rank_service=rag.RankService(
model_name="semantic-ranker-default@latest"
)
),
)
response = rag.retrieval_query(
rag_resources=[rag.RagResource(rag_corpus=CORPUS_NAME)],
text="politique de télétravail pour les managers",
rag_retrieval_config=retrieval_config,
)
Cross-Encoder Reranking avec Vertex AI Ranking API — 15 candidats en entrée, top-5 en sortie
Étape 4 — Les approches correctives
Les techniques précédentes améliorent la capacité du pipeline à retrouver les bons documents. Dans beaucoup de cas, cela suffit à corriger un RAG qui fonctionne mal.
Mais même avec un bon retrieval, un problème persiste : le pipeline n’a aucun mécanisme pour reconnaître quand il se trompe.
Si les documents retrouvés sont hors sujet, incomplets, ou simplement insuffisants pour répondre correctement, le modèle générera quand même une réponse. C’est une propriété fondamentale des LLM : ils préfèrent produire quelque chose plutôt que dire qu’ils ne savent pas.
Les approches suivantes changent cette logique. Au lieu de supposer que le retrieval est toujours bon, elles introduisent une étape de vérification dans le pipeline.
Autrement dit : le système ne se contente plus de chercher et répondre, il évalue la qualité de ce qu’il a trouvé avant de continuer.
C’est précisément le rôle de CRAG et Self-RAG.
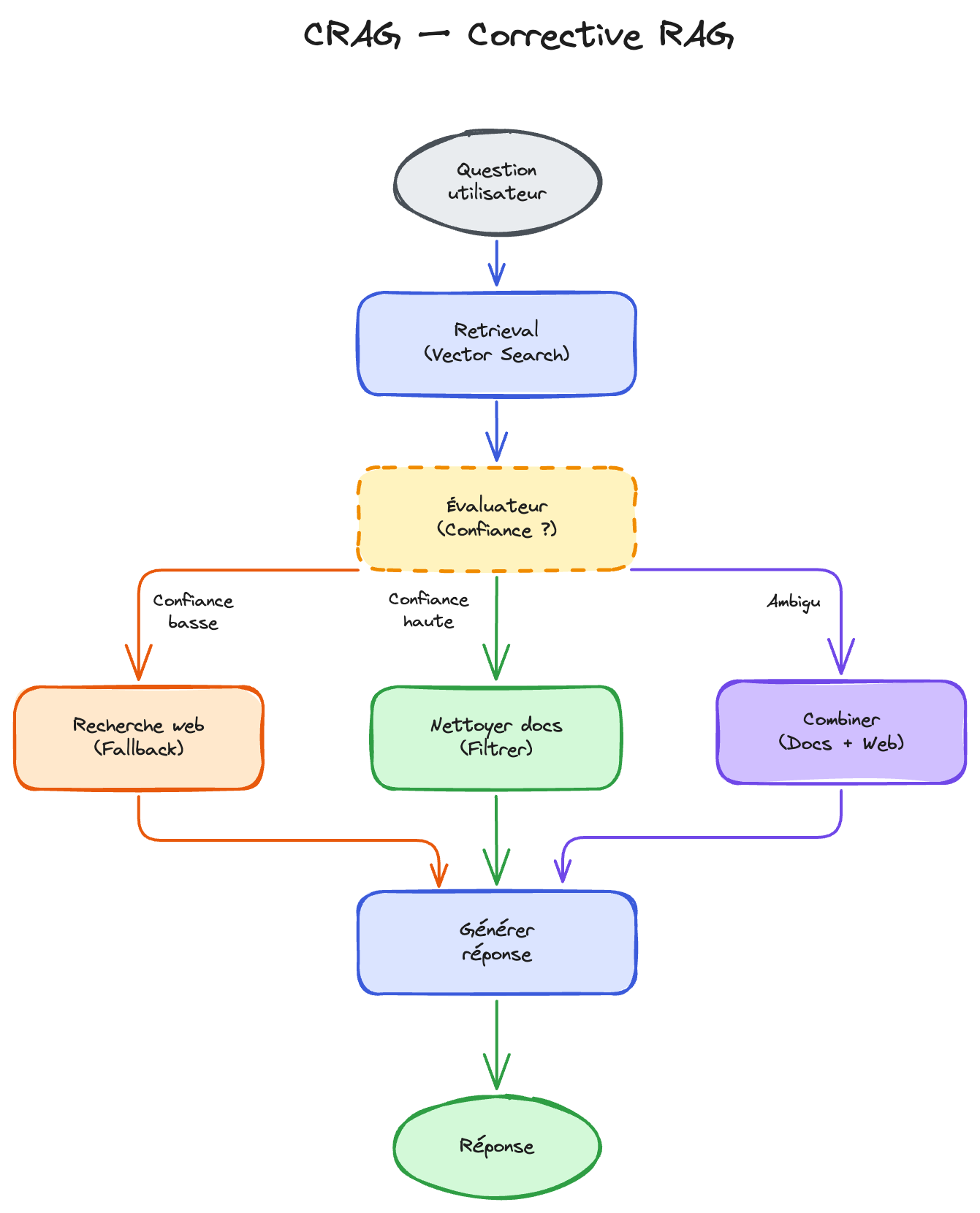
CRAG — le RAG qui sait quand il se trompe
CRAG (Corrective Retrieval-Augmented Generation) ajoute un évaluateur entre le retrieval et la génération. Cet évaluateur — un petit modèle spécialisé, bien moins coûteux qu'un appel à Gemini ou GPT-4 (type T5 fine-tuné par exemple) — note la pertinence des documents retrouvés et déclenche une action selon sa confiance :
- Confiance haute → les documents sont pertinents. On les nettoie (suppression des passages non pertinents dans chaque chunk) et on génère la réponse
- Confiance basse → les documents sont hors sujet. On les jette et on lance une recherche web comme fallback pour trouver de meilleures sources
- Confiance moyenne → c'est ambigu. On combine les documents internes nettoyés avec les résultats de la recherche web
L'analogie : un élève qui, avant de rédiger sa dissertation, vérifie s'il a les bons documents de cours. S'il a les mauvais, il va chercher à la bibliothèque au lieu de répondre n'importe quoi.
Ce qui rend CRAG intéressant en pratique :
- Plug-and-play : il se branche sur n'importe quel pipeline RAG existant sans modifier le reste. L'overhead est de 2-5% de calcul supplémentaire
- Fallback web : pour une base documentaire d'entreprise, le fallback peut être une recherche dans un second corpus (base de connaissances publique, intranet) plutôt que le web ouvert
- Mesurable : le taux de déclenchement du fallback est un indicateur direct de la couverture de votre base documentaire. Si 40% des questions tombent en "confiance basse", c'est votre corpus qui est incomplet, pas votre pipeline
Self-RAG — le RAG qui se relit
CRAG corrige un problème : détecter quand les documents retrouvés sont mauvais.
Mais même avec de bons documents, un second problème subsiste : le modèle peut toujours mal les utiliser.
Un LLM peut ignorer un passage pertinent, interpréter un document de travers, ou générer une réponse partiellement fidèle aux sources. Dans RAGAS, ce problème apparaît souvent dans la métrique Faithfulness.
Self-RAG attaque ce problème différemment : au lieu d’évaluer les documents avant la génération comme CRAG, il introduit des mécanismes d’auto-vérification directement pendant la génération.
Pour faire cela, Self-RAG entraîne le modèle avec des tokens de réflexion qui structurent son raisonnement pendant la génération.
Ces tokens fonctionnent comme des checkpoints : à chaque étape, le modèle évalue ce qu’il fait et décide de la suite.
Quatre tokens de réflexion, chacun avec un rôle précis :
| Token | Question qu'il pose | Réponses possibles |
|---|---|---|
[Retrieve] |
Est-ce que j'ai besoin de chercher des documents ? | Oui / Non |
[ISREL] |
Ce document est-il pertinent pour la question ? | Pertinent / Non pertinent |
[ISSUP] |
Ma réponse est-elle soutenue par le document ? | Totalement / Partiellement / Pas du tout |
[ISUSE] |
Ma réponse est-elle utile au final ? | Score de 1 à 5 |
Le modèle ne retrieve pas systématiquement, il décide quand c'est nécessaire.
Quand il retrieve, il vérifie la pertinence du document, puis vérifie que sa réponse est fidèle au document, puis évalue la qualité globale.
À chaque étape, il peut décider de retrieve à nouveau, de changer de stratégie, ou de continuer.
CRAG vs Self-RAG — la distinction clé :
| CRAG | Self-RAG | |
|---|---|---|
| Agit sur | Les documents (entrée) | La génération (sortie) |
| Granularité | Pipeline-level (une décision par requête) | Token-level (décisions continues) |
| Modification requise | Aucune (plug-and-play) | Modèle fine-tuné avec les tokens de réflexion |
| Coût | +2-5% overhead | Intégré dans la génération |
| Quand l'utiliser | Corpus incomplet, besoin de fallback | Besoin de fidélité maximale aux sources |
En pratique, les deux approches sont complémentaires : CRAG nettoie les documents en amont, Self-RAG vérifie la fidélité en aval. Les expériences montrent des gains de 20-36% quand les deux sont combinés.
Étape 5 — Au-delà du RAG classique
Les techniques précédentes améliorent progressivement un pipeline RAG classique : mieux chercher les documents, mieux les classer, mieux vérifier les réponses.
Mais certaines situations demandent simplement une architecture différente. Non pas parce que le pipeline classique est mauvais, au contraire, il couvre déjà la majorité des cas, mais parce que certains problèmes nécessitent d’autres structures de données ou d’autres modes d’orchestration.
C’est là qu’entrent en jeu des approches qui sortent du RAG classique : GraphRAG pour raisonner sur des relations entre entités, Agentic RAG pour orchestrer plusieurs sources ou outils, ou encore le fine-tuning d’embeddings pour adapter le retrieval à un domaine métier spécifique.
Ces techniques ne remplacent pas le pipeline vu précédemment, elles l’étendent pour des cas d’usage particuliers.
GraphRAG — connecter les points
Le problème : le RAG classique retrouve des chunks isolés. Il ne sait pas raisonner sur les relations entre entités. "Quels projets dépendent du service d'authentification maintenu par l'équipe Infra ?" — cette question nécessite de connecter trois informations réparties dans des documents différents : les projets, le service d'authentification, et l'équipe qui le maintient.
Le principe : au lieu de chercher des bouts de texte similaires, on construit un knowledge graph à partir des documents :
- Extraction : un LLM lit chaque document et extrait les entités (personnes, équipes, projets, services) et les relations entre elles ("maintient", "dépend de", "travaille sur")
- Construction du graphe : les entités deviennent des nœuds, les relations des arêtes
- Community summaries : le graphe est organisé en clusters sémantiques, et un résumé est pré-généré pour chaque communauté
- Retrieval : selon la question, on interroge le graphe localement (entité précise) ou globalement (synthèse sur un thème)
Quand l'utiliser : questions de synthèse multi-documents, données relationnelles (organigrammes, dépendances entre services, chaînes de processus). Si vos utilisateurs posent des questions du type "qui fait quoi" ou "qu'est-ce qui dépend de quoi", GraphRAG excelle !
Le trade-off : l’indexation est plus coûteuse qu’un RAG classique, car chaque document doit passer par un LLM pour extraire les entités et relations. Selon les implémentations publiées, le coût peut être plusieurs fois supérieur à une indexation vectorielle simple.
Microsoft a introduit LazyGraphRAG en 2025 pour réduire ce coût en construisant certaines parties du graphe à la demande, avec des résultats proches du GraphRAG original.
Agentic RAG — le RAG intelligent
Le RAG classique repose sur une pipeline statique : une question, une recherche, une réponse, toujours dans le même ordre. Il ne sait ni router une requête vers différentes sources, ni raisonner en plusieurs étapes.
Or dans la pratique, certaines questions nécessitent de croiser des informations provenant de plusieurs domaines — par exemple des documents RH, techniques ou de conformité — ou simplement d’exposer plusieurs bases de connaissances derrière un même point d’entrée.
Dans ces situations, on introduit un agent qui orchestre le retrieval. C’est le principe de l’Agentic RAG : le système décide quoi chercher, où chercher, et quand s’arrêter. Au lieu d’un pipeline figé, on obtient un raisonnement dynamique.
Exemple avec Google ADK — un agent qui route entre différentes bases de connaissances :
from google.adk.agents import Agent
# Outils de recherche sur différentes sources
def search_hr_docs(query: str) -> str:
"""Recherche dans la documentation RH (congés, contrats, avantages).
Utilise cet outil pour les questions liées aux ressources humaines."""
return rag_query(corpus="hr-docs", query=query)
def search_tech_docs(query: str) -> str:
"""Recherche dans la documentation technique (architecture, API, runbooks).
Utilise cet outil pour les questions techniques."""
return rag_query(corpus="tech-docs", query=query)
def search_policies(query: str) -> str:
"""Recherche dans les politiques d'entreprise (sécurité, conformité, RGPD).
Utilise cet outil pour les questions de conformité et de politique interne."""
return rag_query(corpus="policies", query=query)
agent = Agent(
name="knowledge_assistant",
model="gemini-2.5-flash",
instruction="""Tu es un assistant de documentation interne.
Analyse la question de l'utilisateur et choisis la bonne source.
Si la question couvre plusieurs domaines, interroge plusieurs sources.
Cite toujours la source de tes informations.""",
tools=[search_hr_docs, search_tech_docs, search_policies],
)
Agentic RAG avec Google ADK — routage dynamique entre 3 bases de connaissances via les docstrings
L'agent lit la question, décide quel outil appeler (voire plusieurs), et synthétise les résultats. Le routage se fait par le LLM grâce aux docstrings des fonctions — c'est elles qui servent de "documentation" pour que l'agent comprenne quand utiliser chaque outil.
Quand l'utiliser : données fragmentées sur plusieurs sources, questions qui nécessitent du raisonnement multi-étapes, workflows où le contexte de la question influence la stratégie de recherche.
Fine-tuning des embeddings
Le problème : les modèles d'embedding génériques (text-embedding-001, NV-Embed) sont entraînés sur du texte générique. Votre jargon métier — acronymes internes, noms de produits, vocabulaire spécifique — n'est pas dans leurs données d'entraînement. Le retriever rate des correspondances évidentes pour un humain du domaine.
Le principe : entraîner le modèle d'embedding sur vos données. Concrètement : des paires (question, document pertinent) issues de votre base réelle. Le modèle apprend que "demande de TT" est sémantiquement proche de "formulaire de télétravail", même si un modèle générique ne ferait pas ce lien.
Les résultats sont significatifs :
| Entraînement | Dimensions | Amélioration retrieval |
|---|---|---|
| 6 300 paires | 768 (baseline) | +7,4% |
| 6 300 paires | 128 (Matryoshka) | +13,1% |
| 6 300 paires | 64 (Matryoshka) | +22,5% |
Le plus surprenant : grâce au Matryoshka learning, un modèle fine-tuné à 128 dimensions surpasse le modèle baseline à 768 dimensions — tout en étant 6x plus petit. Moins de stockage, moins de latence, meilleure performance. Le coût d'entraînement ? Environ 3 minutes et 0,07 $ sur une instance GPU.
Quand le faire :
- Vocabulaire métier unique que les modèles génériques ne connaissent pas
- Au moins ~6 000 paires question/document pour l'entraînement (générables avec un LLM à partir de vos documents existants)
- Context Recall RAGAS basse malgré un bon chunking — signe que l'embedding ne capture pas bien votre domaine
Quelle technique choisir ?
Voici le guide de décision. Partez du symptôme, identifiez la métrique RAGAS concernée, et appliquez le correctif correspondant.
| Symptôme | Métrique RAGAS basse | Première action (Partie 1) | Technique avancée (Partie 2) |
|---|---|---|---|
| Les docs retrouvés ne sont pas les bons | Context Precision | Chunking + embeddings | Cross-encoder reranking |
| Des docs pertinents manquent à l'appel | Context Recall | Metadata filtering | Recherche hybride, Multi-query |
| La réponse invente des informations | Faithfulness | Prompt engineering | Self-RAG |
| La réponse ne répond pas à la question | Answer Relevancy | Reformulation de la query | HyDE, Multi-query |
| Rien de pertinent dans les résultats | Toutes basses | Vérifier les données sources | CRAG (fallback) |
| Questions de synthèse multi-docs | N/A | — | GraphRAG |
| Questions multi-sources ou multi-étapes | N/A | — | Agentic RAG |
| Vocabulaire métier non reconnu | Context Recall basse | — | Fine-tuning embeddings |
Le message clé : commencez TOUJOURS par les données et le chunking (Partie 1). Les techniques avancées ne compensent pas des fondations bancales. Un reranking sur des chunks mal découpés ne fera pas de miracles. Un GraphRAG sur des documents mal extraits produira un graphe de mauvaise qualité.
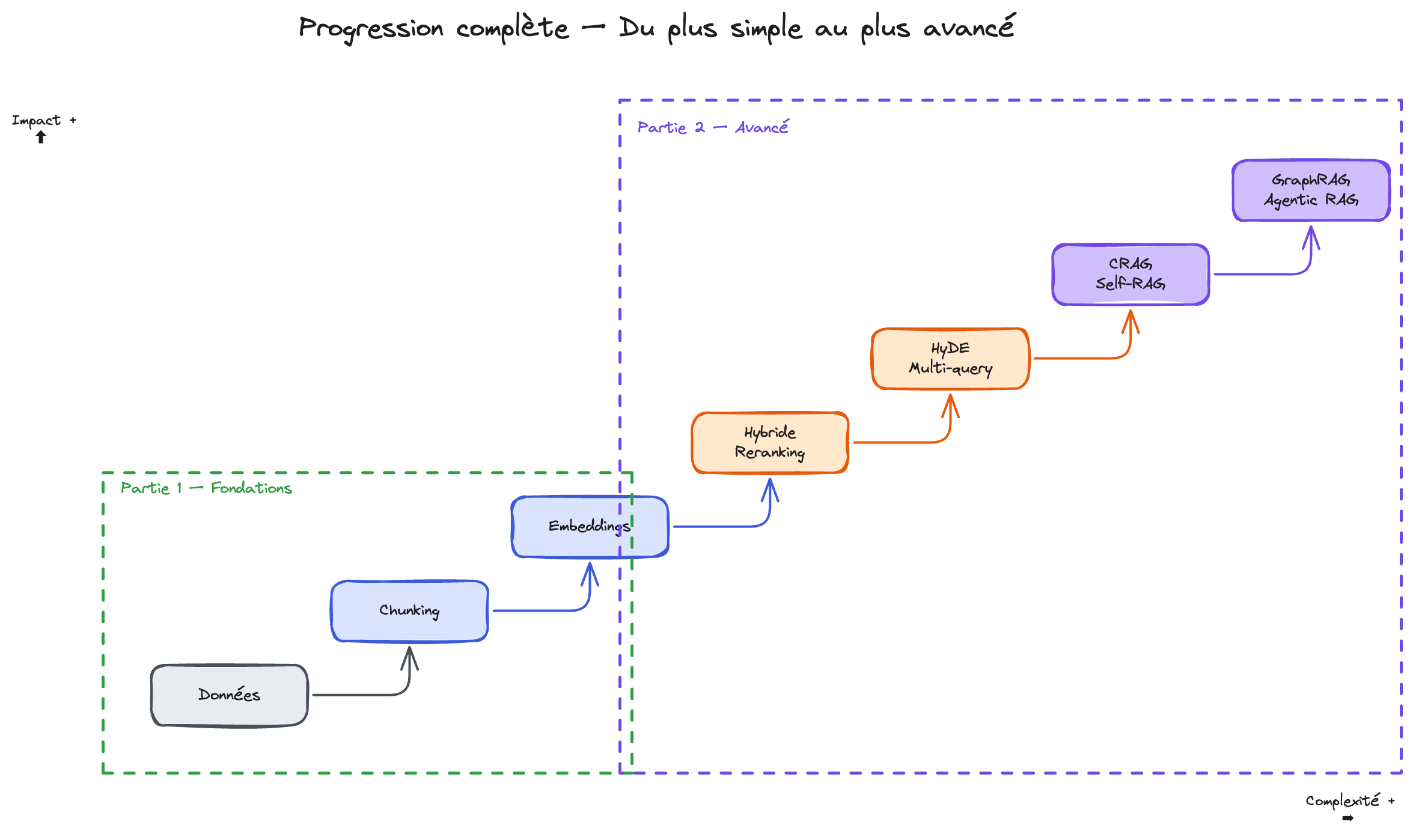
L'ordre d'application compte aussi. Voici une progression type :
- Nettoyez vos données et ajustez le chunking — 80% des gains sont là
- Évaluez vos embeddings avec RAGAS, changez de modèle si nécessaire
- Activez la recherche hybride le quick win le plus rentable côté pipeline
- Ajoutez le reranking si la Context Precision reste basse
- Testez HyDE ou multi-query si le Context Recall stagne
- Implémentez CRAG si votre corpus a des trous de couverture
- Envisagez GraphRAG ou Agentic RAG pour des besoins structurels que le pipeline classique ne peut pas couvrir
Chaque étape se mesure avec RAGAS. Si une technique n'améliore pas vos métriques, ne la gardez pas — elle ajoute de la complexité pour rien.
Conclusion
En deux articles, on a couvert le chemin complet :
- Comprendre les 4 points de rupture d'un RAG naïf
- Mesurer avec RAGAS — transformer des impressions en données
- Corriger les fondations — données, chunking, embeddings
- Améliorer le pipeline — recherche hybride, reranking, HyDE, multi-query
- Ajouter des garde-fous — CRAG quand le corpus est incomplet, Self-RAG quand la fidélité est non négociable
- Repenser l'architecture — GraphRAG pour les relations, Agentic RAG pour le routage intelligent
Le RAG parfait n'existe pas. Mais un RAG mesuré et itérativement amélioré, c'est un RAG qui produit de la valeur.
Le réflexe à garder : lancez RAGAS sur votre pipeline actuel. Identifiez les métriques basses. Appliquez le correctif correspondant dans le tableau ci-dessus. Mesurez à nouveau. Répétez.
Sources :
- RAGAS Documentation
- Vertex AI RAG Engine — Retrieval and Ranking
- Google ADK — Agent Development Kit
- GraphRAG — Microsoft Research
- LazyGraphRAG — Microsoft Research
- CRAG — Corrective Retrieval Augmented Generation (arXiv)
- Self-RAG — Learning to Retrieve, Generate, and Critique (arXiv)
- Fine-tune Embedding Models for RAG — Philipp Schmid
- Matryoshka Representation Learning — Hugging Face
- HyDE — Hypothetical Document Embeddings (arXiv)
- Vertex AI Ranking API





{kind=link}