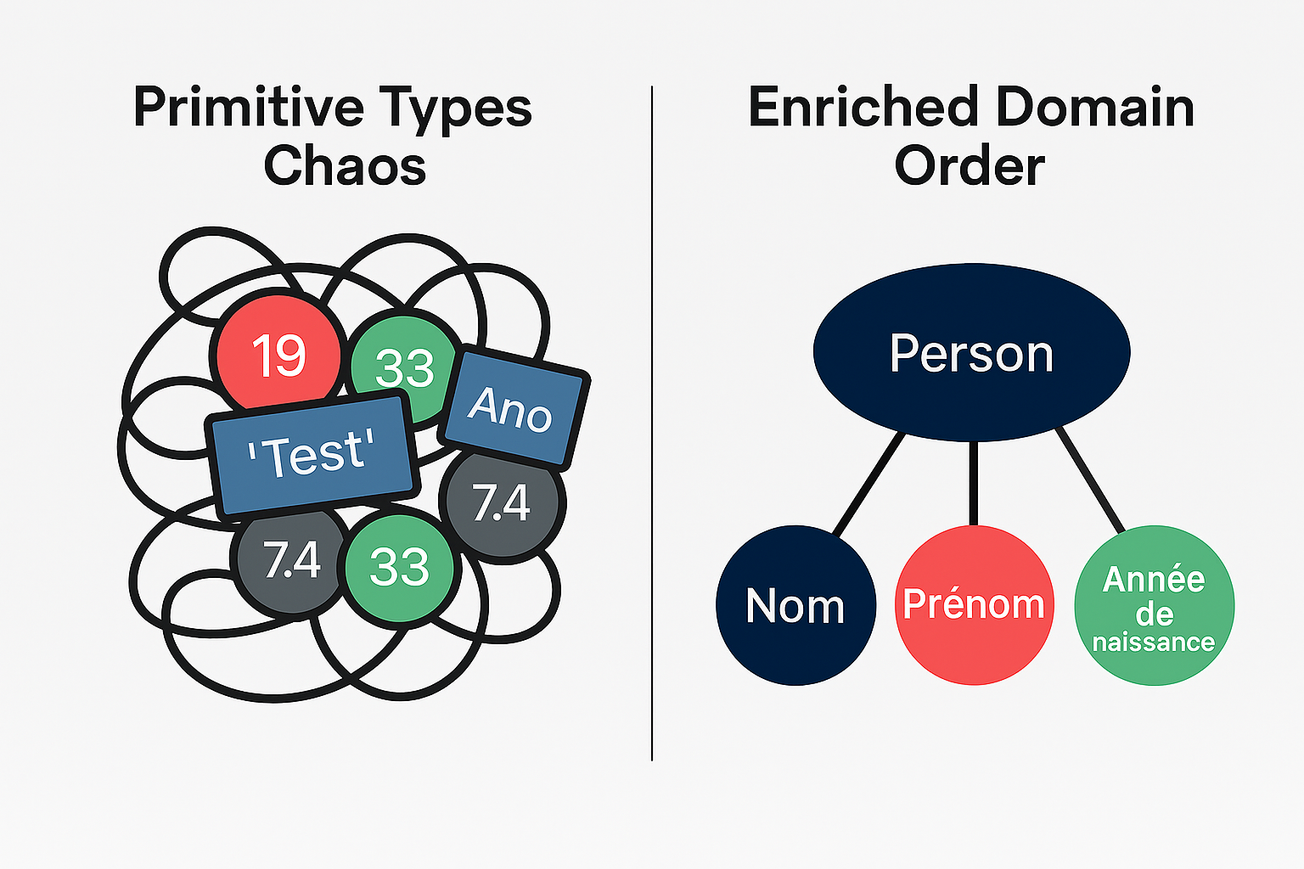
Introduction
Lorsque nous commençons nos premiers pas dans le développement logiciel, d'abord, on nous apprend à écrire un code qui réalise quelque chose, et souvent cela commence par afficher sur la sortie standard de l’ordinateur (que nous appellerons “écran” pour simplifier) la fameuse phrase : “Hello world!”. Ensuite, on nous apprend ce qu’est une instruction, une variable, une structure de contrôle, etc., afin de construire des programmes réalisant des tâches de plus en plus complexes.
Durant ce processus d’apprentissage, nous utilisons uniquement les types de base qu’un langage de programmation comme le C ou Java met à disposition.
Ainsi, nous pouvons nous remémorer un programme simple qui initialise quelques variables et les affiche à l’écran (pour simplifier, nous ne montrerons que les parties du code qui nous intéressent, sans les classes lorsque ce n’est pas nécessaire, et en utilisant Java 25 pour ses nouvelles facilités à destination des apprenants) :
Exemple de code en Java 25
void main() {
String nom = "Dupond";
String prenom = "Toto";
int age = 19;
int annee = 2026;
IO.println("%s %s aura %d ans en %d".formatted(nom, prenom, age, annee));
age += 2;
annee += 2;
IO.println("%s %s aura %d ans en %d".formatted(nom, prenom, age, annee));
}
Et le résultat attendu de ce simple programme est le suivant
Sortie d'écran
Dupond Toto aura 19 ans en 2026
Dupond Toto aura 21 ans en 2028
Tout simple et rien d'extraordinaire. Deux variables de types String pour représenter le nom et le prénom d'une personne et deux autres variables de type entier (int) pour représenter l'âge de celui-ci et l'année à laquelle l'âge est calculé. Enfin, une sortie pour afficher toutes ces données. Nous ajoutons 2 à l'âge et à l'année pour ensuite dupliquer l'instruction d'affichage avec les nouvelles valeurs de ces dernières.
Les types primitifs sont-ils suffisants ?
À premier abord, tout va pour le mieux et notre programme fait bien ce à quoi il est destiné. Mais comme de bons développeurs qui avons appris un peu plus sur la modularisation du code et le rôle des fonctions (méthodes) dans nos programmes, nous allons extraire l'instruction d'affichage dans une fonction afficherInfosPersonne afin de la réutiliser.
Refactoring avec une fonction d'affichage
void afficherInfosPersonne(String nom, String prenom, int age, int annee) {
IO.println("%s %s aura %d ans en %d".formatted(nom, prenom, age, annee));
}
void main() {
String nom = "Dupond";
String prenom = "Toto";
int age = 19;
int annee = 2026;
afficherInfosPersonne(nom, prenom, age, annee);
age +=2;
annee +=2;
afficherInfosPersonne(nom, prenom, age, annee);
}
La sortie du programme ne change pas et c'est la preuve que notre refactor était correct (dans le vraie vie, les changements doivent être guidés par les tests).
Sortie d'écran
Dupond Toto aura 19 ans en 2026
Dupond Toto aura 21 ans en 2028
Mais avec un peu de chance (ou malchance), nous allons devoir ajouter 10 à l'âge et à l'année et réafficher tout en saisissant le code :
Ajouter 10 à l'âge et à l'année
void main() {
// mêmes instructions que l'exemple d'avant et en plus les suivantes
annee +=10;
age +=10;
afficherInfosPersonne(nom, prenom, annee, age);
}
La sortie cette fois-ci est la suivante :
Sortie d'écran erronée
Dupond Toto aura 19 ans en 2026
Dupond Toto aura 21 ans en 2028
Dupond Toto aura 2038 ans en 31
On se rend compte que l'affichage n'est pas bon à la troisième ligne et qu'on affiche l'année à la place de l'âge. Une petite erreur facile à corriger mais on aurait aussi pu écrire par erreur (en remplaçant l'exemple d'avant) :
Addition inexacte et affichage erroné
void main() {
// mêmes instructions que l'exemple d'avant
age +=10;
annee +=age;
afficherInfosPersonne(nom, prenom, annee, age);
}
Et l'affichage sera le suivant :
Sortie d'écran erronée
Dupond Toto aura 19 ans en 2026
Dupond Toto aura 21 ans en 2028
Dupond Toto aura 2059 ans en 31
Encore pire, en plus de permuter l'âge et l'année à l'affichage, nous avons additionné l'âge à l'année ce qui donne des résultats inattendus. Ce dernier exemple nécessitera un peu plus d'attention pour le corriger et remettre les bonnes variables aux bons arguments et ne pas additionner deux "entités" non équivalentes à savoir l'année et l'âge.
Absence de sémantique et faible intégrité
Avec la simple représentation de l'âge en entier (int), nous n'avons aucun contrôle sur la vraie sémantique de cette entité. En effet, nous pouvons nous retrouver avec un code correct mais sémantiquement incorrect comme celui-ci :
Absence de sémantique et faible intégrité
void main() {
// mêmes instructions que l'exemple d'avant
age = -10;
afficherInfosPersonne(nom, prenom, age, annee);
}
Rien ne nous empêche de donner une valeur négative à l'âge, mais est-ce que c'est une valeur acceptable pour ce type de données ? Probablement non. Un âge est défini depuis la naissance et donc un entier positif et ne peut pas avoir une valeur négative.
Nous pouvons ajouter des fonctions de contrôle pour s'assurer que l'âge est toujours positif, mais cela reste à la bonne volonté du développeur de l'utiliser ou plutôt de ne pas oublier de l'utiliser.
Notre seul repère dans ce type de code sont les noms des variables qui nous indiquent le sens que nous voulons donner à chacun de ces types génériques.
Compilateur "inutile"
En effet, avec une signature aussi simpliste que la nôtre et avec des arguments interchangeables d'un point de vue typage :
Signature simpliste
void afficherInfosPersonne(String nom, String prenom, int age, int annee);
Nous n'avons aucune chance que le compilateur Java, dans notre cas, nous guide comme il le fait si bien avec le reste des types. Ceci en soi est un échec cuisant pour ceux qui choisissent des langages de programmation fortement typés comme Java qui permet de détecter au plus tôt les dangers liés à l'utilisation des variables de types différents.
Ce que nous venons de voir est ce qui est appelé un anti-pattern qualifié d'Obsession des types primitifs. Un modèle de programmation à éviter afin d'écrire du code plus lisible, facile à maintenir, auto-documenté et moins susceptible aux erreurs de saisie ou de logique de développeur dans les gros projets.
Value Object à la rescousse
Pour se prémunir de cet "enfer de types primitifs", nous avons à notre disposition les objets de valeur ou Value Object qui nous permettent d'enrichir notre domaine et donc nos types (ça vient du Domain-Driven Design - DDD). C'est une encapsulation des types simples et qui représenteront de par leurs valeurs le domaine que nous manipulons. Dans notre exemple, nous pouvons identifier quatre types : Nom, Prenom, Age et Annee.
Value Object Nom, Prenom, Age et Annee
record Nom(String valeur) {
}
record Prenom(String valeur) {
}
record Annee(int valeur) {
public Annee ajouter(Annee autre) {
return new Annee(valeur + autre.valeur());
}
public Annee soustraire(Annee annee) {
return new Annee(valeur - autre.valeur());
}
}
record Age(int valeur) {
public Age {
if (valeur < 0) {
throw new IllegalArgumentException("L'âge est négatif.");
}
}
public Age ajouter(Annee annee) {
return new Age(valeur + annee.valeur());
}
}
Nous avons créé quatre nouveaux types d'objets qui ont des opérations enrichies qui renforcent l'encapsulation de leurs valeurs que nous appellerons : Modèle de domaine riche en opposition à l'anti-pattern Modèle de domaine anémique. Nous pouvons maintenant réécrire notre fonction afficherInfosPersonne :
Refactoring avec le nouveau domaine
void afficherInfosPersonne(Nom nom, Prenom prenom, Age age, Annee annee) {
IO.println("%s %s aura %d ans en %d".formatted(nom.valeur(), prenom.valeur(), age.valeur(), annee.valeur()));
}
void main() {
final Nom nom = new Nom("Dupond");
final Prenom prenom = new Prenom("Toto");
final Age age = new Age(19);
final Annee annee = new Annee(2025);
afficherInfosPersonne(nom, prenom, age, annee);
Annee deuxAns = new Annee(2);
afficherInfosPersonne(nom, prenom, age.ajouter(deuxAns), annee.ajouter(deuxAns));
}
Après ce refactoring nous avons la certitude que l'ordre d'insertion des arguments est correct et que le développeur est obligé de donner les bons arguments. Pareil, nous avons la certitude que les données entrées sont intègres et que l'âge est toujours positif. De plus, nous ne pouvons plus additionner l'âge à l'année et les deux entités sont bien distinctes maintenant.
De plus, lorsque nous manipulons des objets de domaine nous forçons la sémantique indépendamment des noms des variables. Je ne sous-estime pas les noms des variables, fonctions, etc. mais je dis simplement que le nom devient naturel et la sémantique est forcée par le type de l'objet.
Les Value Objects sont caractérisés par :
- Ils sont immuables (idéalement)
- Ils ont des implémentations de toString, hashCode et equals basées uniquement sur les valeurs qu'ils contiennent
- Ils sont égaux uniquement sur la base de leurs valeurs pas sur leurs identités
- Ils sont interchangeables en toute transparence lorsqu'ils sont égaux
Nous manipulons et utilisons tous les jours ce type d'objets dans le JDK, à savoir : LocalDate, LocalDateTime, Optional, etc. et sont décorés par l'annotation @ValueBased.
Les vrais Value Objects Java arrivent
Les records Java c'est bien, mais ils ne sont pas tout à fait adaptés à notre enveloppe de type. En effet, notre type Age n'est qu'une enveloppe pour un entier et ça serait bien d'avoir une structure du langage qui nous évitera les surcoûts d'un objet standard Java à la création puis tout le cycle de vie lié à sa gestion dans la JVM.
Java avec son projet Valhalla arrivera avec cette nouveauté "value based class" qui changera le cœur des types Java. Cette nouvelle structure permettra une optimisation en faisant abstraction de l'identité des objets pour se concentrer uniquement sur les valeurs et par conséquent plus besoin de références (identités d'objets) et l'opérateur d'égalité == se réalisera sur les valeurs de l'objet de valeur. Voici à quoi ressemblera notre Age dans sa forme simpliste dans un futur lointain/proche :
Value Object Java
value record Age(int valeur) {}
Identifiants fortement typés
Nous utilisons souvent des objets avec des identifiants uniques qui peuvent être de différents types : Long, String, UUID, etc. Nous utiliserons Long dans nos exemples pour simplifier mais en aucun cas je ne le recommanderais (le choix du type d'ID peut être le sujet d'un autre article).
Nous avons l'habitude de nous retrouver avec des services ou stores avec des APIs comme suit :
Identifiant primitif
public interface PersonneService {
Optional<Personne> findOne(Long id);
}
À l'utilisation, nous pouvons facilement nous tromper et utiliser l'âge ou toute autre variable de type Long à la place de l'ID attendu ici, celui de la personne. Ceci dit, nous avons les mêmes problèmes que tout ce que nous avons vu précédemment.
Et pour vous rappeler de ne pas utiliser des types primitifs comme IDs, souvenez-vous de ce nom de design pattern : Strongly typed IDs (Identifiants fortement typés). Par conséquent, notre service s'écrira comme suit :
Identifiant fortement typé
public interface PersonneService {
Optional<Personne> findOne(PersonneID id);
}
Cette écriture auto-documente le service et le rend moins sujet aux erreurs, plus propre et plus robuste et nous évite des heures de débugage.
Conclusion
Dans cet article nous avons discuté du chaos et "L'enfer des types primitifs" qu'on a qualifié d'anti-pattern Obsession des types primitifs dans les grosses bases de code et comment y remédier en mettant de l'ordre, de la sémantique et de renforcer l'intégrité dans nos données avec les Value Objects et "le modèle de domaine riche" en opposition au "Modèle de domaine anémique".
Nous avons aussi évoqué le design pattern Identifiants fortement typés qui permet d'utiliser un type dédié pour les identifiants des objets métier.
Enfin, il va de soi que l'utilisation des records Java est coûteuse pour juste envelopper un type primitif, c'est pourquoi nous avons évoqué la nouveauté prochaine du projet Valhalla "value based class" qui réduira le surcoût lié à l'utilisation actuellement des records pour représenter nos enveloppes de domaine.





{kind=link}