
Pour ceux qui lisent régulièrement notre super média tech et IA, vous êtes probablement déjà tombés sur la vignette d'un de mes très nombreux articles.
De nombreux sujets traité :
- design patterns
- spring Boot
- une incursion dans l'univers Quarkus
- de l'IA
- et même des histoires dont vous êtes le héros !
Bref, pour m’aider à garder une vue d’ensemble sur tout ça, j’utilise Obsidian.
Ça me permet notamment de visualiser ce qu’on appelle un “cocon sémantique”.
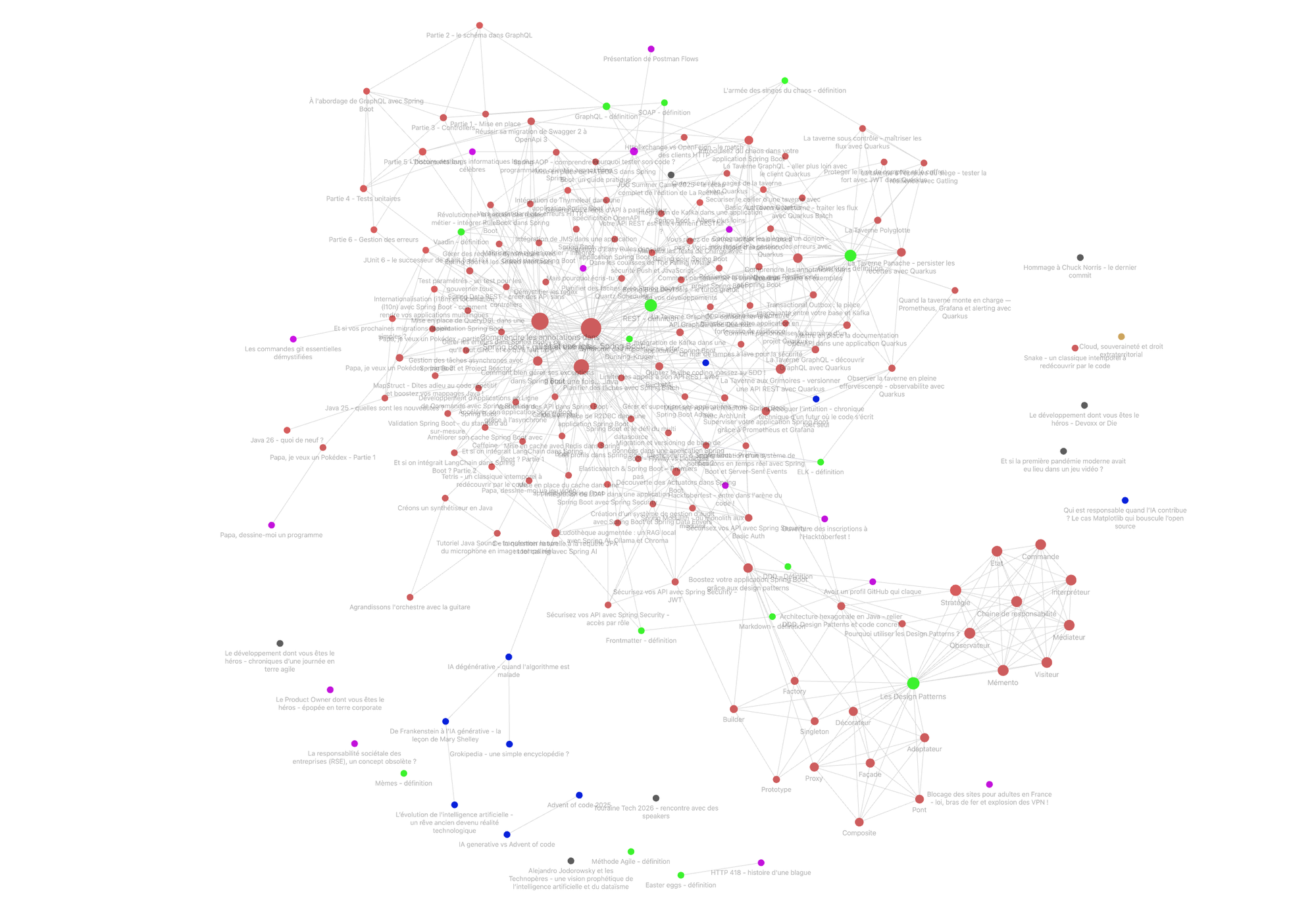
Et en regardant cette cartographie, une idée m’est venue :
Et si je pouvais discuter directement avec sfeir.dev en langage naturel ?
Pas faire une recherche classique avec trois mots-clés.
Non. Réellement poser une question.
Comme à quelqu’un qui connaîtrait déjà tout le contenu du site.
C’est exactement là qu’entre en scène le MCP.
Mais c'est quoi déjà MCP ?
Le MCP, pour Model Context Protocol, est une manière standardisée de permettre à une IA de dialoguer avec des outils ou des sources de données externes.
Dit autrement, au lieu de limiter une IA à ce qu’elle connaît déjà, on lui donne la possibilité d’aller chercher des informations ailleurs : dans des fichiers, des bases de données, des API, des dépôts Git… ou, dans notre cas, directement dans le contenu du site média tech et IA.
On peut voir le MCP comme une sorte de traducteur universel entre un modèle d’intelligence artificielle et le reste du système d’information.
Sans MCP, une IA reste enfermée dans sa conversation et dans le contexte qu’on lui fournit manuellement. Avec lui, elle peut récupérer des informations dynamiques, consulter des ressources ou même déclencher certaines actions.
C’est précisément ce qui rend cette approche particulièrement intéressante pour créer des assistants spécialisés.
Dans notre cas, l’objectif est assez simple : permettre à une IA de parcourir, comprendre et interroger l’ensemble des articles du média comme le ferait un lecteur qui aurait tout lu… et surtout tout retenu (on vous voit ceux qui partent au bout de 30 secondes 👀).
Créer un server MCP avec Spring Boot
L’idée est donc de construire une petite application Spring Boot qui va faire le pont entre deux mondes :
- d’un côté, un client MCP, par exemple Claude Desktop, qui sait appeler des outils ;
- de l’autre, Ghost, qui expose le contenu du média en ligne via ses API Content et Admin.
Le serveur MCP va se placer au milieu. Il reçoit une demande formulée par l’IA sous forme d’appel d’outil, appelle Ghost si nécessaire, puis renvoie une réponse structurée.
Dans le projet, l’architecture reste volontairement classique :
Ce découpage a un avantage très concret : le MCP reste une couche d’exposition. Toute la logique utile reste dans du code Java normal, testable normalement, avec des services, des clients HTTP et des modèles.
Les dépendances nécessaires
La dépendance importante du projet, c’est le starter MCP server fourni par Spring AI :
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server</artifactId>
</dependency>starter mcp server
C’est lui qui permet à Spring Boot d’exposer des méthodes Java comme outils MCP.
Le projet s’appuie aussi sur spring-boot-starter-webflux, principalement pour utiliser WebClient afin d’appeler les API Ghost :
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>starter webflux
Enfin, l’API Admin de Ghost nécessite de générer un JWT. Pour ça, le projet utilise la librairie jjwt :
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt-api</artifactId>
<version>0.13.0</version>
</dependency>dépendance jwt
Une application Spring Boot sans serveur web
On pourrait croire qu’un serveur MCP est forcément une API HTTP. En réalité, dans ce cas précis, l’application est lancée comme un simple processus par Claude Desktop. La communication se fait via l’entrée/sortie standard.
La configuration Spring Boot reflète ça :
spring:
application:
name: ghost-mcp-server
main:
banner-mode: off
web-application-type: none
ai:
mcp:
server:
enabled: true
name: "ghost-mcp-server"
version: "1.0.0"extrait des properties de l'application
Le point le plus important est ici :
web-application-type: noneOn indique à Spring Boot qu’il ne doit pas démarrer de serveur web embarqué.
Pas de Tomcat, pas de Netty HTTP exposé en local, pas de port à ouvrir. L’application vit comme un programme en ligne de commande, piloté par le client MCP.
L’autre partie importante est celle-ci :
spring:
ai:
mcp:
server:
enabled: trueElle active le serveur MCP fourni par Spring AI.
La classe principale reste donc très simple :
@SpringBootApplication
@EnableConfigurationProperties(GhostProperties.class)
public class GhostMcpServerApplication {
static void main(String[] args) {
SpringApplication.run(GhostMcpServerApplication.class, args);
}
}notre main
Rien de spectaculaire, et c’est plutôt une bonne nouvelle.
On reste dans un projet Spring Boot très standard.
Configurer l’accès à Ghost
Le serveur a besoin de connaître trois choses :
- l’URL du média en ligne Ghost
- la clé de l’API Content
- éventuellement la clé de l’API Admin.
Ces valeurs sont externalisées dans application.yaml :
ghost:
url: ${GHOST_URL}
admin-api-key: ${GHOST_ADMIN_API_KEY}
content-api-key: ${GHOST_CONTENT_API_KEY}
log-file: ${GHOST_LOG_FILE:src/logs/mcp-server.log}extrait du fichier de properties
Puis elles sont exposées côté Java via un record annoté avec @ConfigurationProperties :
@ConfigurationProperties(prefix = "ghost")
public record GhostProperties(
String url,
String adminApiKey,
String contentApiKey,
String logFile) {
public boolean hasAdminKey() {
return adminApiKey != null
&& !adminApiKey.isBlank()
&& !adminApiKey.equals("${GHOST_ADMIN_API_KEY}");
}
public boolean hasContentKey() {
return contentApiKey != null
&& !contentApiKey.isBlank()
&& !contentApiKey.equals("${GHOST_CONTENT_API_KEY}");
}
}Les méthodes hasAdminKey() et hasContentKey() peuvent sembler anecdotiques, mais elles vont servir à décider quels outils MCP doivent être exposés.
Si on fournit uniquement la clé Content, l’IA pourra lire les articles publics.
Si on fournit aussi la clé Admin, elle pourra accéder aux brouillons, aux articles planifiés et aux métadonnées plus complètes.
C’est une manière simple de faire varier les capacités du serveur selon l’environnement.
Exposer une méthode Java comme outil MCP
La partie la plus agréable avec Spring AI, c’est qu’un outil MCP ressemble beaucoup à une méthode Java normale.
Prenons un exemple dans GhostContentTools :
@Component
public class GhostContentTools {
private final GhostService ghostService;
public GhostContentTools(GhostService ghostService) {
this.ghostService = ghostService;
}
@Tool(
name = "getContentPostBySlug",
description = """
Récupère un article unique par son slug (partie friendly de l'URL) via l'API Content.
C'est la méthode recommandée pour afficher le contenu d'un article à partir de son lien.
"""
)
public Post getPostBySlug(String slug) {
return ghostService.getContentPostBySlug(slug);
}
}extrait du tool qui utilise l'API content
L’annotation @Tool transforme cette méthode en outil utilisable par le client MCP.
Deux informations sont particulièrement importantes :
name: qui donne le nom technique de l’outildescription: qui explique au modèle quand et pourquoi utiliser cet outil.
Il faut vraiment soigner cette description. Pour nous, c’est de la documentation. Pour le modèle, c’est une partie de son interface de décision.
Si la description est vague, l’IA risque d’appeler le mauvais outil, ou de ne pas l’appeler du tout.
Dans ce projet, les outils Content permettent notamment de :
- récupérer tous les articles publics
- récupérer un article par identifiant
- récupérer un article par slug
- lister les auteurs
- lister les tags.
Et les outils Admin permettent de :
- récupérer tous les articles, y compris les brouillons et les articles planifiés
- filtrer les articles par auteur
- filtrer les articles par tag
- récupérer un article avec ses informations administratives.
Déclarer les outils disponibles
Annoter des méthodes ne suffit pas. Il faut aussi les fournir à Spring AI via un ToolCallbackProvider.
C’est le rôle de McpConfig :
@Configuration
public class McpConfig {
@Bean
public ToolCallbackProvider ghostToolsProvider(
GhostProperties ghostProperties,
GhostAdminTools ghostAdminTools,
GhostContentTools ghostContentTools) {
MethodToolCallbackProvider.Builder builder =
MethodToolCallbackProvider.builder();
if (ghostProperties.hasAdminKey()) {
builder.toolObjects(ghostAdminTools);
}
if (ghostProperties.hasContentKey()) {
builder.toolObjects(ghostContentTools);
}
return builder.build();
}
}on enregistre les tools disponibles
Le détail intéressant, c’est que les outils sont enregistrés conditionnellement.
Pas de clé Admin ? On n’expose pas les outils Admin.
Pas de clé Content ? On n’expose pas les outils Content.
Ce n’est pas seulement plus propre techniquement. C’est aussi plus clair pour l’IA. Elle ne voit que les actions réellement disponibles.
Concevoir des tools simples et spécialisés
Les classes GhostContentTools et GhostAdminTools ne font presque rien elles-mêmes.
Elles traduisent un appel MCP en appel de service.
Par exemple :
@Tool(
name = "findAdminPostsByAuthor",
description = """
Recherche les articles de blog écrits par un auteur spécifique (par exemple 'erwan') via l'API Admin.
Permet d'accéder aux articles (publiés ou non) d'un auteur particulier.
Retourne une liste contenant les objets Post complets.
"""
)
public List<Post> getAdminPostsByAuthor(String author) {
return ghostService.getAdminPostsByAuthor(author);
}extrait du tool utilisant l'API admin
Le tool ne sait pas comment Ghost filtre par auteur. Il ne sait pas comment fonctionne la pagination. Il ne sait pas comment est généré le JWT Admin.
Et c’est très bien comme ça.
Un serveur MCP devient vite difficile à maintenir si les outils contiennent toute la logique.
Ici, les tools restent une façade.
La vraie orchestration est dans GhostService.
Gérer la pagination côté serveur
L’API Ghost renvoie les listes sous forme paginée. C’est logique pour une API, mais ce n’est pas ce qu’on veut exposer directement au modèle.
Quand on demande à l’IA “liste-moi les articles du média”, on ne veut pas qu’elle récupère la page 1, puis qu’elle comprenne toute seule qu’il existe une page 2, puis une page 3.
Cette logique est donc placée dans GhostService :
public List<Post> getAllContentPosts() {
log.info("Fetching all posts from Content API");
List<Post> allPosts = new ArrayList<>();
int currentPage = 1;
PostResponse response;
do {
response = contentApiClient.getPosts(currentPage);
if (response != null && response.posts() != null) {
allPosts.addAll(response.posts());
currentPage++;
}
} while (response != null && response.meta().pagination().next() != null);
return allPosts;
}gestion de la pagination
Le service appelle les pages les unes après les autres tant que Ghost indique une page suivante dans meta.pagination.next.
Même principe pour les auteurs, les tags et les appels Admin.
C’est typiquement le genre de détail qu’un serveur MCP doit absorber.
Le modèle exprime une intention. Le serveur se charge de la mécanique.
Interroger les articles du blog via l’API Content
Les appels à Ghost sont isolés dans des clients dédiés.
Pour l’API Content, le projet utilise GhostContentApiClient.
Le client configure un WebClient avec l’URL de base du média :
this.webClient = WebClient.builder()
.baseUrl(ghostProperties.url() + "/ghost/api/content")
.defaultHeader("Accept-Version", "v5.0")
.codecs(configurer -> configurer
.defaultCodecs()
.maxInMemorySize(2 * 1024 * 1024))
.build();Puis il ajoute la clé Content dans les paramètres de requête :
public PostResponse getPosts(int page) {
return webClient.get()
.uri(uriBuilder -> uriBuilder
.path("/posts/")
.queryParam("key", ghostContentApiKey)
.queryParam("limit", limit)
.queryParam("page", page)
.queryParam("fields", "id,title,slug,status,published_at,url")
.queryParam("include", "tags,authors")
.build())
.retrieve()
.bodyToMono(PostResponse.class)
.block();
}Quelques choix sont importants ici :
Accept-Versionfixe explicitement la version de l’API Ghostlimitréduit le nombre d’appels nécessairesfieldsévite de récupérer trop de données dans les listesinclude=tags,authorsdonne plus de contexte à l’IA.
Le code utilise WebClient, mais termine par .block().
Dans le contexte d’un serveur MCP local, appelé ponctuellement par un client desktop, c’est un compromis très raisonnable : on garde une écriture simple, tout en utilisant un client HTTP moderne.
Appeler l’API Admin avec un JWT
L’API Admin de Ghost fonctionne différemment de l’API Content. Elle attend un token JWT signé à partir de la clé Admin, au format id:secret.
Le projet délègue ça à GhostJwtService :
public String generateToken() {
String[] parts = properties.adminApiKey().split(":");
String keyId = parts[0];
String secret = parts[1];
byte[] secretBytes = hexStringToByteArray(secret);
SecretKey key = Keys.hmacShaKeyFor(secretBytes);
Instant now = Instant.now();
return Jwts.builder()
.header()
.keyId(keyId)
.type("JWT")
.and()
.issuedAt(Date.from(now))
.expiration(Date.from(now.plusSeconds(300)))
.audience()
.add("/admin/")
.and()
.signWith(key, SignatureAlgorithm.HS256)
.compact();
}génération du jwt
Ce détail peut sembler étrange au premier abord, mais Ghost attend explicitement que le token JWT cible l’API Admin via l’audience /admin/.
Sans cette information, le token est considéré comme invalide par Ghost, même si la signature est correcte.
Le token est ensuite envoyé dans l’en-tête Authorization :
.header("Authorization", "Ghost " + jwtService.generateToken())L’intérêt, côté MCP, est évident : le modèle n’a jamais accès au secret. Il voit seulement un outil de haut niveau, par exemple findAdminPostsByTag. Toute la partie sensible reste côté serveur.
Brancher le server à des outils IA
Brancher le serveur dans Claude Desktop
Une fois le projet compilé :
mvn clean packageOn obtient un jar dans target/ghost-mcp-server-0.0.1-SNAPSHOT.jar.
Il peut ensuite être déclaré dans la configuration de Claude Desktop.
Pour ce faire, une fois l'application lancée, il suffit d'aller dans Paramètres -> Développeur -> Modifier la configuration.
Claude ouvre alors directement le fichier claude_desktop_config.json.
Il suffit d’y ajouter le bloc suivant :
{
"mcpServers": {
"ghost-mcp-server": {
"command": "java",
"args": [
"-Dio.netty.noUnsafe=true",
"--enable-native-access=ALL-UNNAMED",
"-jar",
"/chemin/vers/ghost-mcp-server-0.0.1-SNAPSHOT.jar"
],
"env": {
"GHOST_URL": "https://votre-blog.ghost.io",
"GHOST_ADMIN_API_KEY": "id:secret",
"GHOST_CONTENT_API_KEY": "content-key",
"GHOST_LOG_FILE": "/chemin/vers/mcp-server.log"
}
}
}
}vous espériez voir mes clé ? Et bien c'est raté :p
Au redémarrage de Claude Desktop, le serveur est lancé automatiquement.
Les outils déclarés par Spring AI deviennent alors disponibles dans la conversation.
À partir de là, on peut poser des questions beaucoup plus naturelles :
- “Quels articles parlent de Spring Boot ?”
- “Retrouve-moi les articles liés aux design patterns.”
- “Quels sujets reviennent souvent dans le média ?”
- “Quels brouillons sont associés à l’IA ?”
Et c’est précisément ce qu’on cherchait au départ : ne plus seulement chercher dans le média, mais discuter avec lui.

Brancher le serveur dans Codex
La aussi rien de compliquer, une fois Codex démarré, il suffit d'aller dans Paramètres -> Server MCP.
Une interface apparait et vous n'avez plus qu'a compléter les champs
Une fois les champs remplis, il faut attendre quelques instant pour que le server soit disponible et utilisable.
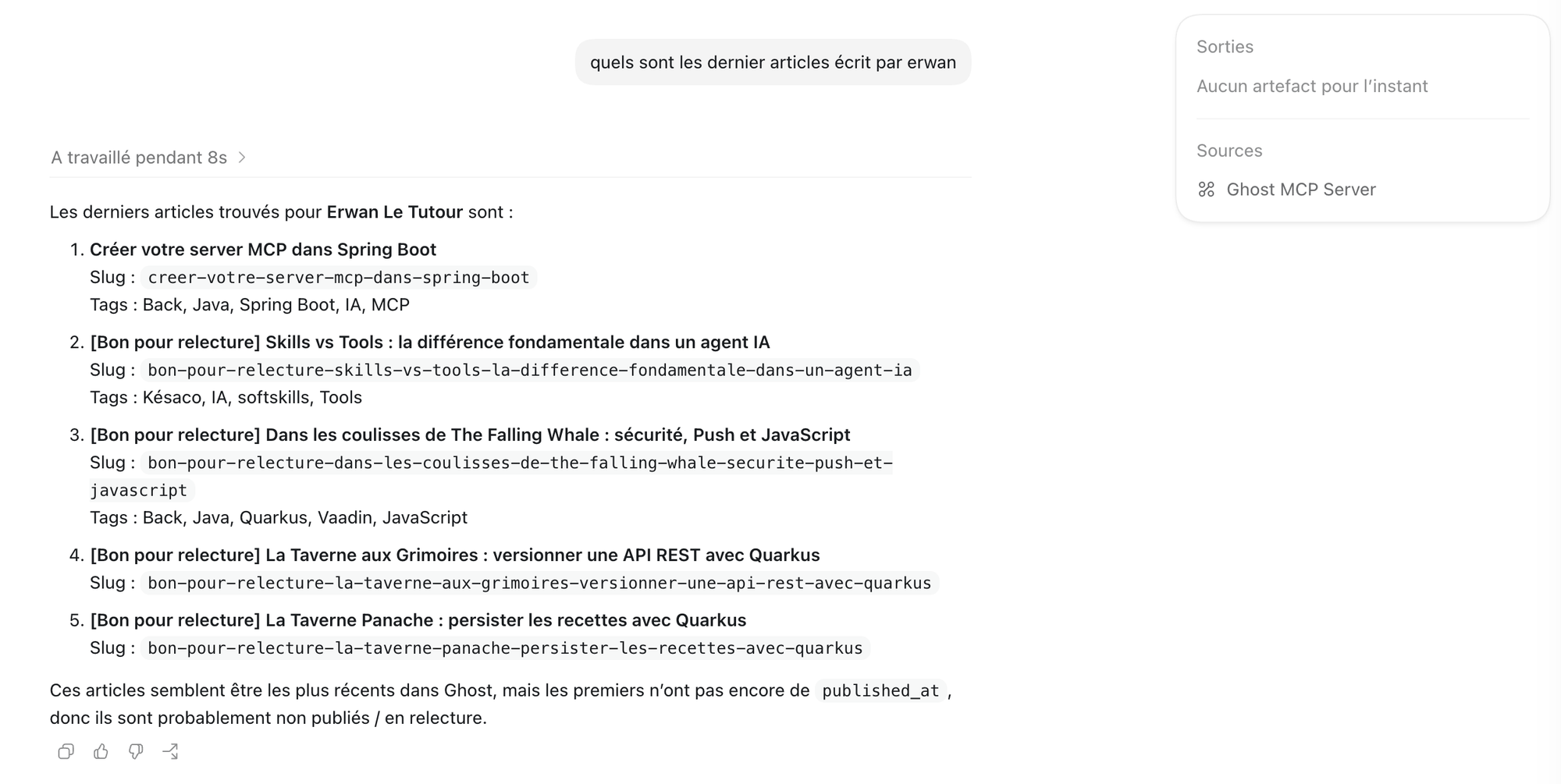
On voit bien ensuite que la source d'information provient de notre server MCP.
Les pièges à éviter
Avant de conclure, il y a quand même deux ou trois pièges qui méritent d’être mentionnés. Parce que le MCP donne une impression de simplicité, mais certains détails peuvent vous faire perdre pas mal de temps.
Ne polluez pas la sortie standard
Dans une configuration comme celle-ci, le client MCP communique avec le serveur via stdio. Autrement dit, ce qui passe dans la console n’est pas juste “du texte affiché pour faire joli”. C’est aussi le canal utilisé par le protocole.
Donc si votre application commence à écrire n’importe quoi dans stdout, par exemple avec des System.out.println, une bannière Spring Boot, ou des logs console, vous risquez de casser la communication entre le client MCP et le serveur.
C’est pour cette raison que le projet désactive la bannière Spring Boot :
spring:
main:
banner-mode: offdésactivation de la bannière
Et c’est aussi pour ça que les logs sont envoyés dans un fichier via logback-spring.xml :
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>${LOG_FILE}</file>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="FILE" />
</root>En clair : pour débugger, utilisez un fichier de logs. Pas la console. Votre futur vous dira merci.
Exposer trop d’outils
On pourrait être tenté de créer un outil pour chaque endpoint Ghost, puis de tout brancher au modèle. Ça marche, mais ce n’est pas forcément une bonne idée. Plus il y a d’outils, plus le modèle doit choisir entre des actions proches les unes des autres.
Il vaut mieux exposer des outils orientés usage :
- récupérer un article par slug ;
- lister les articles ;
- chercher les articles d’un auteur ;
- chercher les articles associés à un tag.
Pas simplement recopier toute l’API distante.
Oublier que les descriptions sont lues par le modèle
Une description comme “get post” n’aide pas beaucoup. Une description qui précise “récupère un article unique par son slug, recommandé quand on part d’une URL” donne beaucoup plus de signal. Dans un serveur MCP, le nom de l’outil compte, mais sa description compte presque autant.
Attention aux secrets
Le modèle ne doit jamais recevoir directement la clé Admin Ghost. Il n’a pas besoin de la connaître. Il doit seulement pouvoir appeler un outil de haut niveau. L’authentification, le JWT, les headers HTTP et les détails sensibles doivent rester côté serveur.
Ce qu’il faut retenir
Mettre en place un serveur MCP avec Spring Boot, ce n’est pas très éloigné de la création d’un service backend classique.
Il faut :
- ajouter le starter MCP de Spring AI ;
- configurer l’application comme un processus sans serveur web ;
- exposer des méthodes avec @Tool ;
- enregistrer ces tools via un ToolCallbackProvider ;
- garder la logique métier dans des services testables ;
- protéger les secrets et les appels sensibles côté serveur.
Le plus important, finalement, n’est pas la quantité de code. C’est la frontière que l’on dessine.
Le modèle ne doit pas connaître les détails de l’API Ghost. Il ne doit pas gérer la pagination. Il ne doit pas manipuler les clés. Il doit seulement disposer d’outils clairs, bien nommés, qui correspondent à des intentions humaines.
C’est là que le MCP devient intéressant : il transforme une application existante en terrain de dialogue pour l’IA.
Et dans notre cas, il transforme notre média Ghost en interlocuteur capable de nous aider à explorer tout ce qu’on y a déjà écrit.
Si ce projet vous à intéressé, que vous aussi vous publiez sur un site hébergé par ghost, ou que vous êtes tout simplement curieux, le code relatif à cet article est consultable juste ici :





{kind=link}