Si vous n’avez pas vu la partie 1 de cette série d’articles, la voici !
Précédemment, nous avons pu faire des choses qui sont relativement similaires à ce que l’on trouve actuellement sur internet, à savoir rédiger un prompt pour générer une image, la différence est simplement que celle-ci est opérée localement sur notre machine, et est gratuite.
De plus, la génération n’est basée que sur un prompt textuel. Pourtant ce que l’on peut (et allons faire), ce sera d’utiliser d’autres canaux d’informations pour donner du contexte au modèle IA.
Pour guider et conditionner notre modèle, nous allons voir les techniques et nodes suivantes :
- Les LoRA, pour orienter vers un thème ou un style précis.
- ControlNet, pour affiner avec les informations structurelles de l'image
- L'Inpainting, pour effectuer des retouches sur des zones très précises de l'image
- L'Outpainting, pour étendre les bords de l'image avec une génération cohérente
- L'Upscaling, pour agrandir la résolution sans sacrifier de temps de traitement
Donner une thématique grâce aux LoRAs
LoRA ? Kézaco ?
Le principe du LoRA, ou Low RAnk adapter, est une technique qui consiste à étendre la capacité d’une intelligence artificielle à générer des images dans un thèmes spécifiques, sans avoir à réentraîner depuis le début notre modèle. Cela permet donc d’avoir un modèle très adapté à des tâches précises, et sans forcément limiter ses capacités ailleurs. Par exemple, si je veux réaliser une IA capable de générer des images dans un style d’estampe japonaise, je peux utiliser un LoRA, qui a été entraîné sur la base d’un modèle existant, spécifiquement pour cette tâche.
Quelques indications :
- Le LoRA se déclenche souvent par l’intermédiaire d’un “trigger word”, qui permet à l’IA de conditionner l’activation de la node. Par exemple, pour un style cyberpunk, le trigger word pourrait être “cyberpunk style”.
- On peut décider avec quelle “intensité” appliquer notre LoRA, ça peut être très utile, si on décide d’en combiner plusieurs par exemple, ou si on souhaite avoir une version “atténuée” du LoRA
- Les modèles LoRA, ne sont compatibles qu’avec le modèle de base sur lequel ils ont été entraînés. Par exemple, un modèle entraîné sur Stable Diffusion XL, pourra fonctionner sur SDXL 1.0, et ses dérivés (comme SDXL Turbo, Lightning, LCM, etc…), mais pas sur flux.dev, qui aura ses propres LoRAs.
Et concrètement ça donne quoi ?
Pour se simplifier la vie, on peut partir sur ce workflow de base. Il s’agit du workflow proposé de base par comfyUi, alors autant en profiter.
Note : Si vous partez d’absolument zéro, le workflow est accessible ici :
et importable en allant sur (Flux de travail => Ouvrir => Puis sélectionnez le fichier .json téléchargé). Sinon vous pouvez faire comme dans la partie 1 pour générer un workflow utilisable.
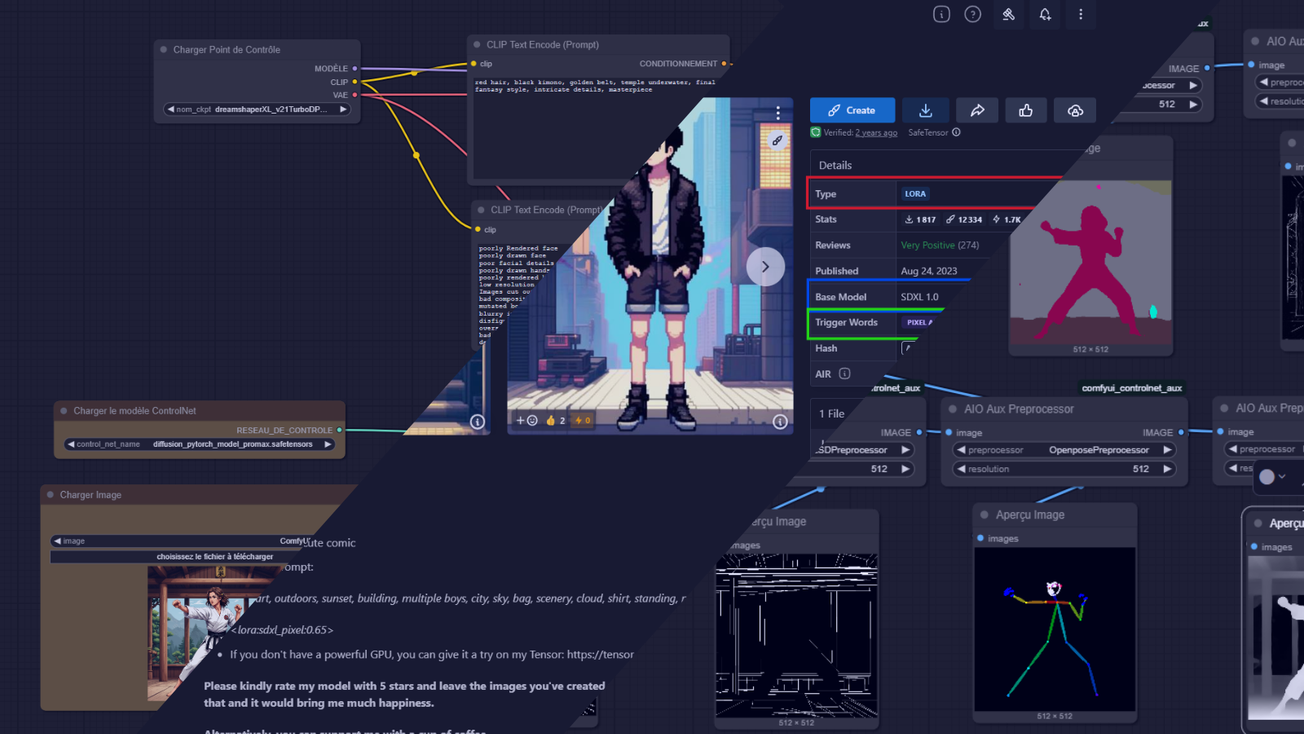
Une fois ceci fait, vous pouvez aller sur le site civit.ai, pour trouver un LoRA qui vous fait plaisir. Pour notre exemple nous allons prendre un LoRA pixel art, qui est disponible ici
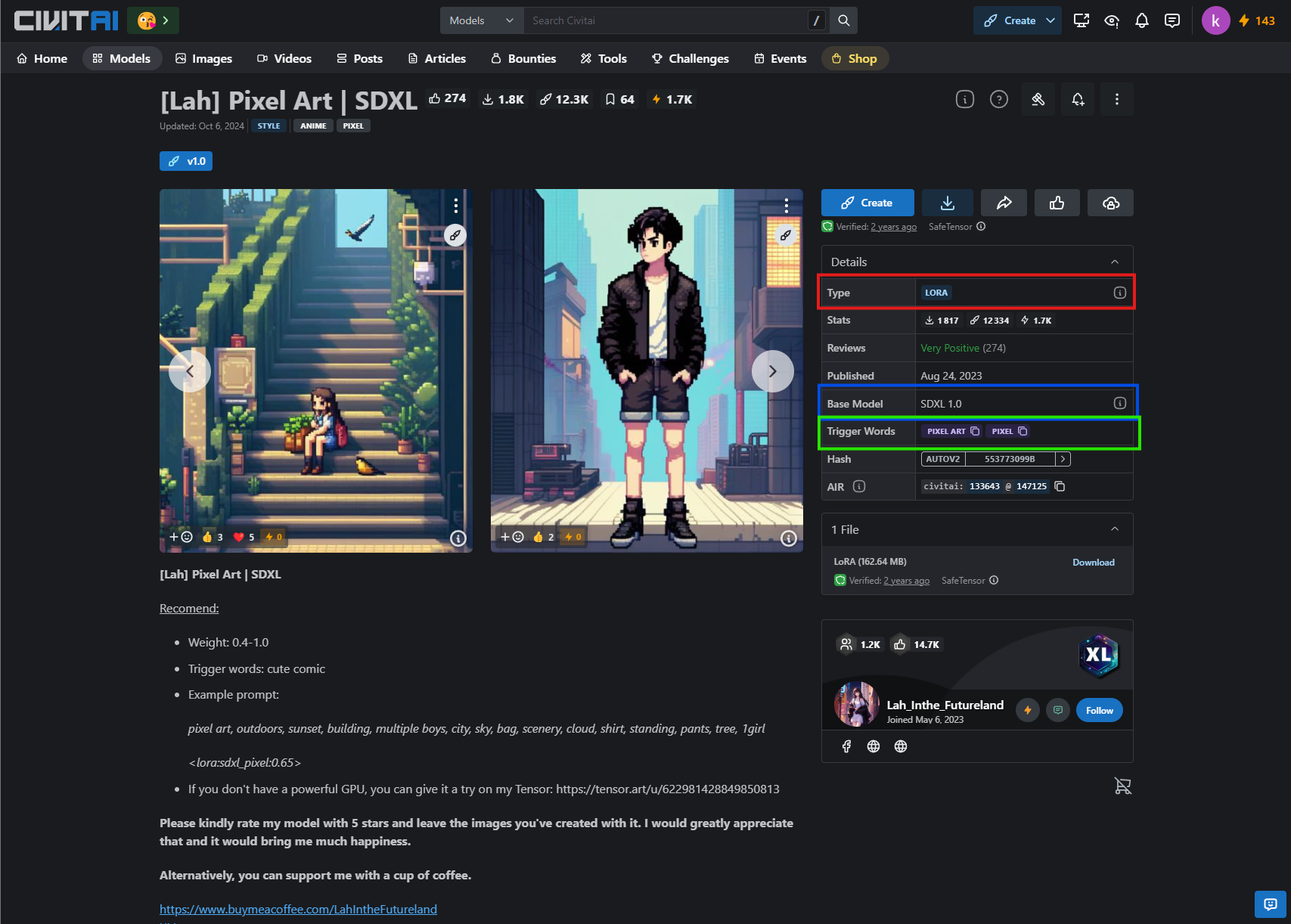
Après téléchargement, déplacez le fichier d’extension “.safetensor”, dans le dossier suivant : “comfyUI/models/loras” Une fois ceci fait, nous allons charger le LoRA dans notre workflow, et pour cela rien de plus simple. Double-cliquez sur le workflow, pour activer la barre de recherche, et tapez “lora”.Vous allez trouver dans la liste “Charger LoRA”, sélectionnez-le. Vous devriez voir cette node apparaître :
Elle n’a que 3 paramètres :
- model_name: Le modèle que l’on souhaite intégrer
- strength_model: “L’intensité” du modèle, cela permet d’accentuer ou d’atténuer le style si besoin
- strength_clip: Pareil que l’intensité du modèle, mais pour le CLIP (le prompt en gros), généralement on peut le laisser à 1, dans la plupart des cas
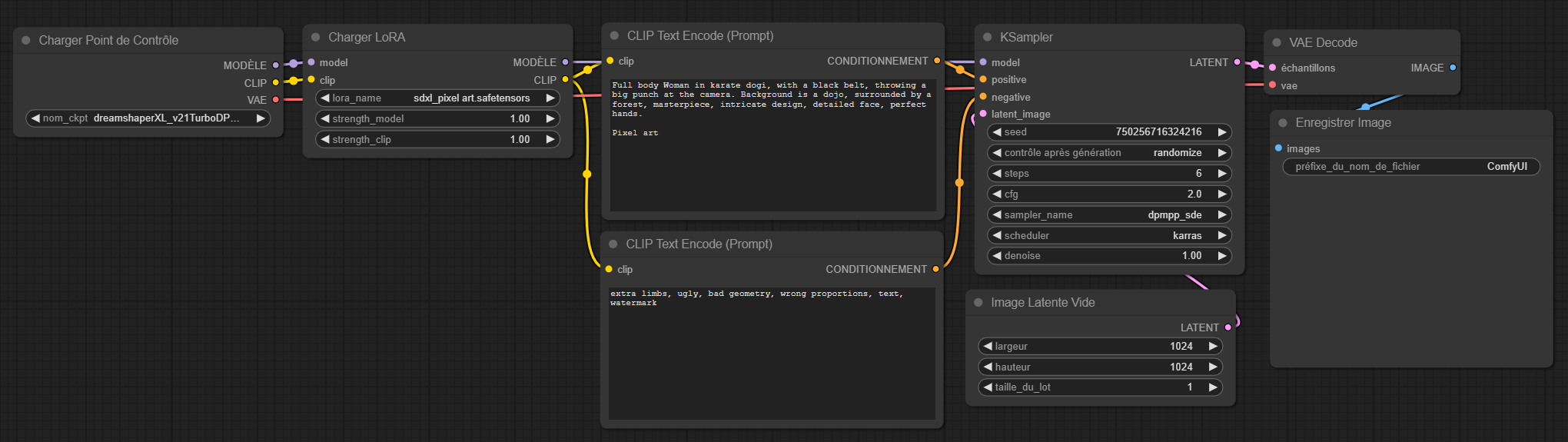
Il suffit ensuite de la connecter aux différents points, donc model, sur le checkpoint et le Ksampler, clip sur la sortie du checkpoint et à l’entrée des prompts. Comme sur l’image ci-dessous.
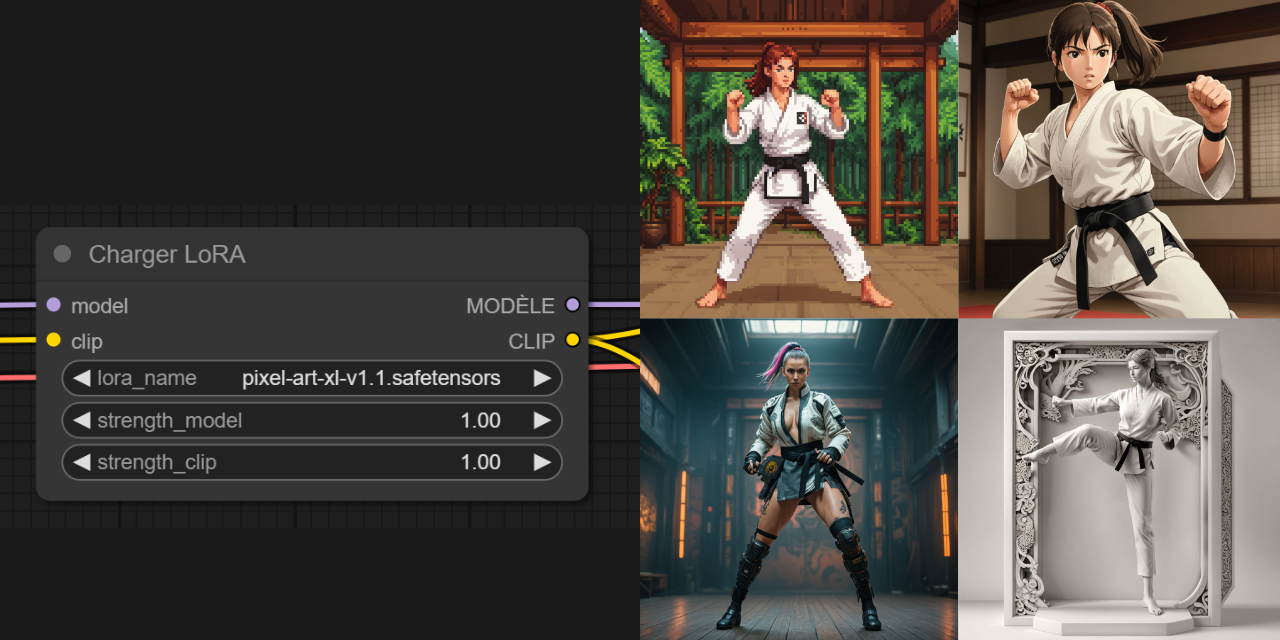
Dernière étape : l’activation du LoRA. Comme expliqué précédemment, il suffit d’ajouter le trigger word dans le prompt positive pour que cela fonctionne ! :).
Exemple de prompt :
Pixel art (Le trigger word)
Félicitations ! Vous avez réussi à orienter un modèle pour un thème ou un style précis !
Proposer une structure d’image avec ControlNet
Structurer son image, c'est-à-dire ?
Après quelques générations, vous avez sans doute remarqué que les résultats sont un peu aléatoires, même en fournissant de bonnes prompts, mais par exemple si j'ai besoin que :
- Mon verre ait une forme bien spécifique.
- Le décor soit structuré d’une manière précise
- Mon personnage respecte une posture particulière
Eh bien c’est assez difficile de le décrire avec des mots, et ce serait tellement bien de pouvoir fournir directement l’image et demander : “Voilà, mon image doit ressembler dans l’idée générale à ce que je te fournis”.
Ne pleurez pas mes aïeux, ControlNet est là !
Cette technologie permet exactement de faire ce que je viens d’énoncer, récupérer une image et en extraire sa structure (de différentes manières en fonction du besoin), pour ensuite guider le processus de génération.
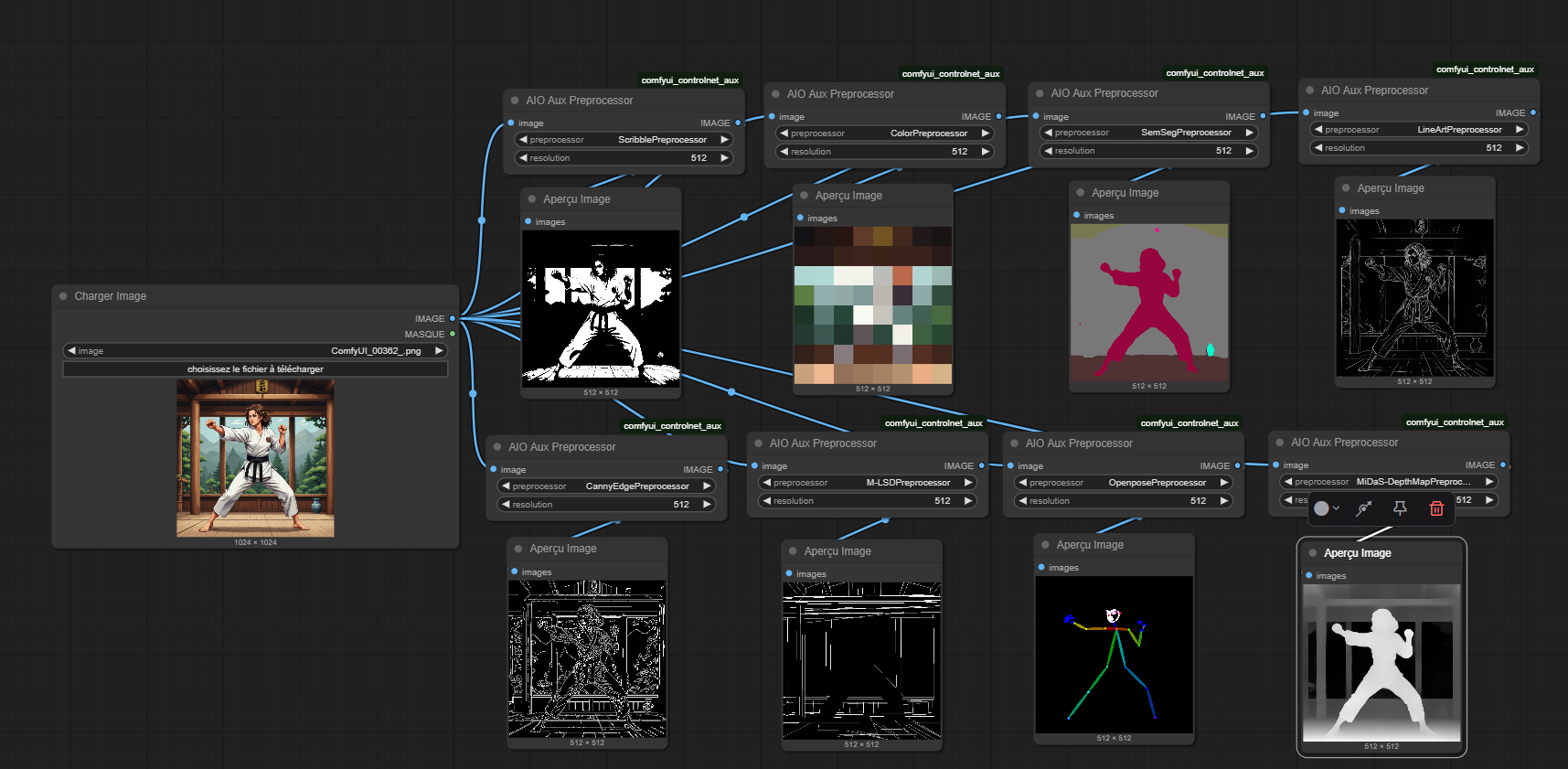
Les images utilisées pour un controlNet sont très différentes, mais on va s'attarder sur quelques types d'informations que l'on peut récupérer sur une image :
Les contours (Canny):
Comme son nom l'indique, on récupère les contours, sous forme d'une image en noir et blanc, l'algorithme arrive à repérer les contours en fonction des différences de contraste entre les pixels, tout simplement.
C'est très pratique pour faire du restyling par exemple, comme ci-dessous :

La pose (OpenPose) :
On utilise ici l'algorithme "OpenPose", pour détecter et récupérer les informations de posture du sujet (humain ou animal). Cela peut être super utile pour générer des personnages multiples, ou d'avoir une posture précise pour le sujet.
La composition de l'image (Segmentation):
Une image peut être segmentée en différentes parties, comme le fond, le sujet principal, et les objets de premier plan, par exemple. Cela est super pratique pour isoler une partie de l'image, pour la modifier.

Les informations de profondeur de champ (Depth):
Comme son nom l'indique, l'algorithme cartographie l'image, et la convertit en image en noir et blanc. Plus l'élément est au premier plan, plus il sera perçu comme blanc, donc proche. Cela a pour nom une "DepthMap".

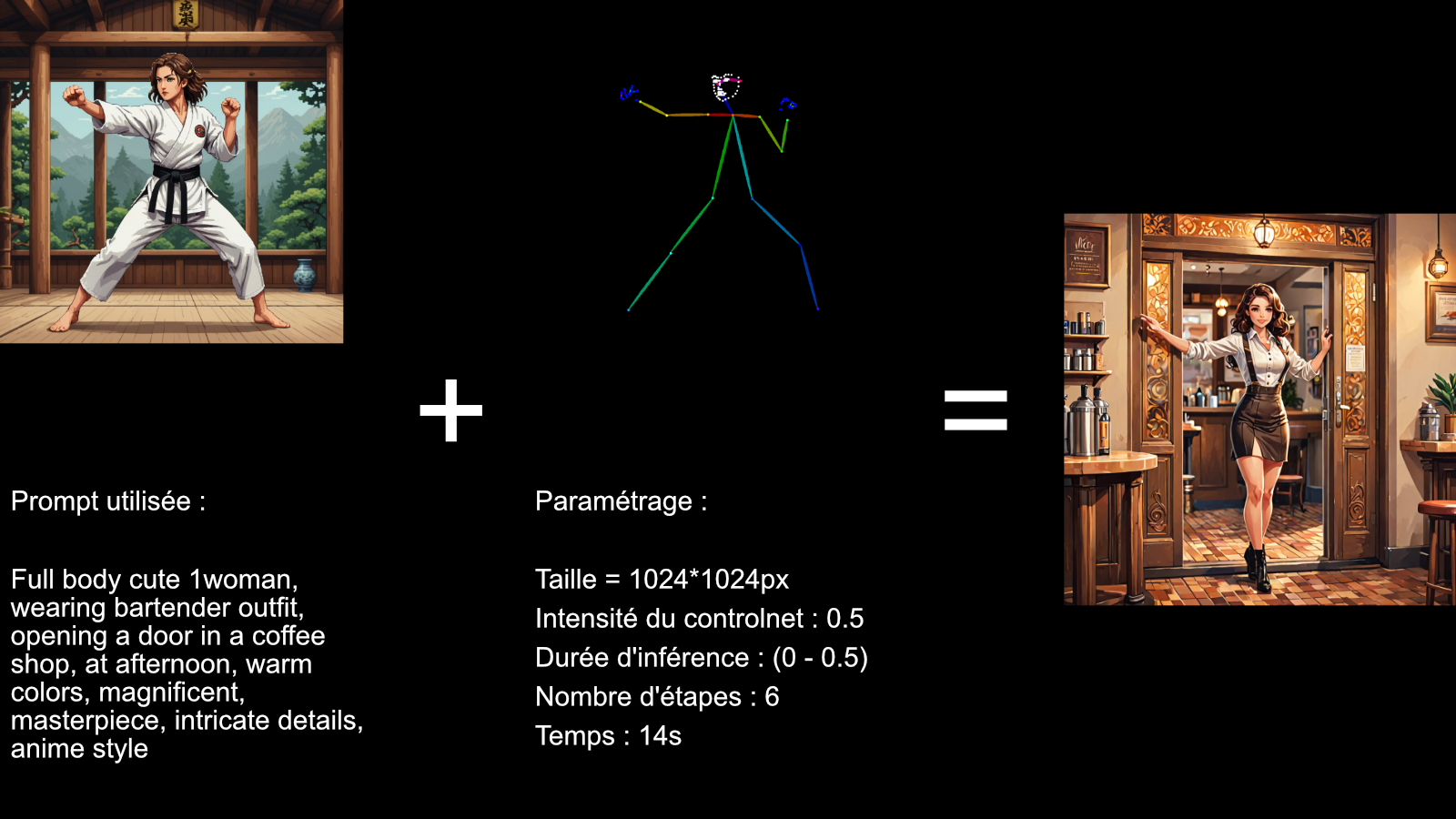
Ici on voit que l'on a pu faire des changements importants (la couleur de cheveux, le kimono, la ceinture, le background etc), sans toucher à la structure de l'image.
Trop cool ! Mais comment on implémente ça dans notre workflow ?
Prérequis :
- Télécharger la customNode "comfyui-controlnet-aux", en utilisant le manager, puis dans custom nodes manager, il se trouve ensuite dans la liste
- Télécharger le modèle controlNet, vous pouvez le trouver sur le ModelManager, en tapant "controlnet++", et en prenant la version promax (elle supporte l'inpainting et l'outpainting, ce qui sera utile pour la suite du tutoriel ! 😄).
- Prenez ensuite le workflow en .json) ajouté à l'article, et importez le dans comfyUi (vous pouvez le drag'n'drop dans la fenêtre, ou aller sur Flux de travail, puis Ouvrir)
Les nodes colorées en jaune sont celles qui nous intéressent :
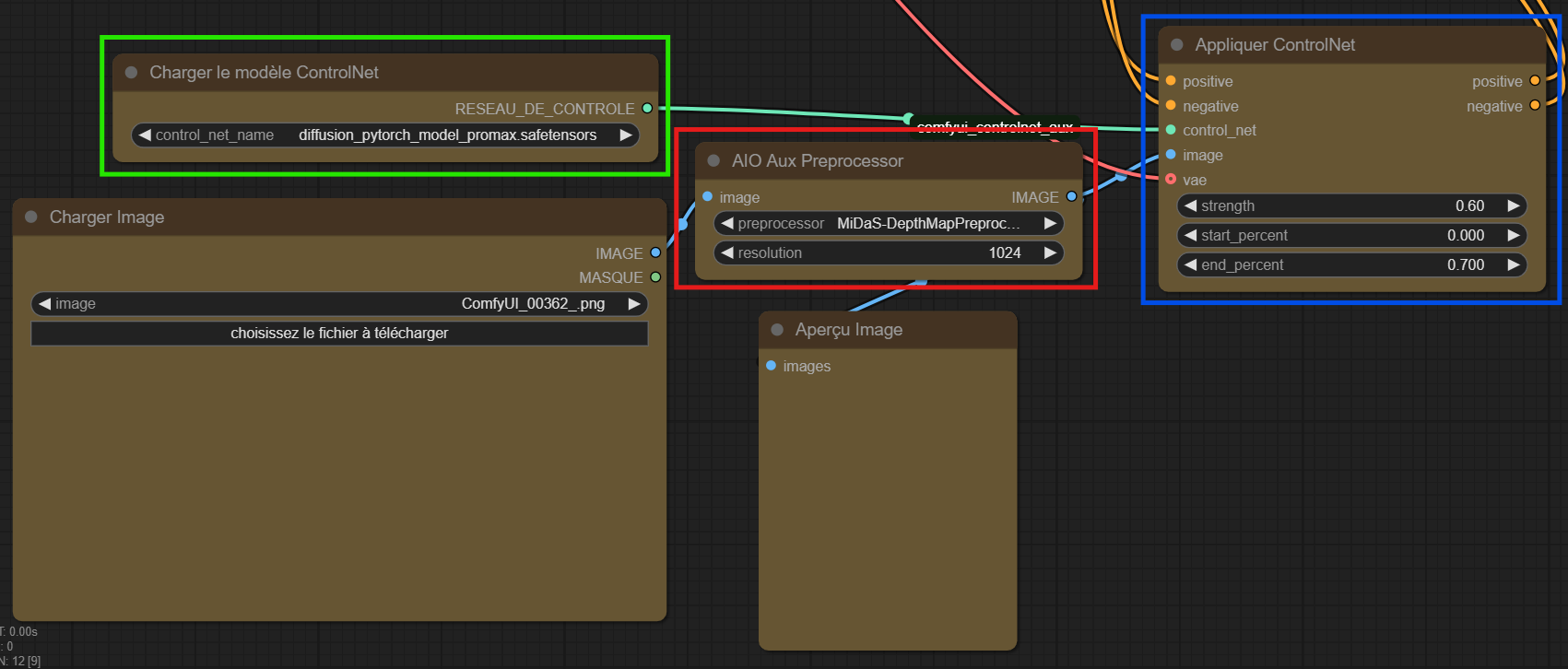
En vert : On charge le controlnet dont on a besoin, ici le controlnet++promax pour sdxl
En rouge : Le préprocesseur d'image pour le controlNet, il permet de décomposer une image "normale", en image pour le controlNet. Selon le type de préprocesseur utilisé, on aura des résultats différents (canny, openPose, depth, etc..) On peut également choisir la résolution de l'image.
En bleu : L'application du controlNet, On a besoin de le brancher au flux de conditionnement (d'ou le positive/negative), au modèle de controlNet chargé, d'y ajouter une image, et d'ajouter un VAE (parce que l'image sera encodée en latent space). 3 paramètres très utiles ici :
- strength : L'intensité d'application du controlNet, plus il est haut, plus on force le respect de la structure du controlNet
- start_percent et end_percent : On peut définir à quel moment le controlNet intervient dans le processus de débruitage, soit au tout début, soit vers la fin, ou tout du long !
Corriger ou modifier une région de l'image avec l'Inpainting
Le principe est super simple, il consiste à masquer la région d'une image, (en très gros, c'est juste remplir une zone de pixels noirs), pour la remplacer par quelque chose d'autre. Mais la partie intéressante de l'opération, c'est que l'on peut faire générer par notre IA, le remplacement de ce que l'on a masqué !
Par exemple :

Alors comment accomplit-on ce prodige sur comfyUI ?
Les prérequis (promis il n'y en a pas beaucoup).
Dans le node manager (custom nodes manager) recherchez :
- comfyui_controlnet_aux, si vous avez fait le tuto controlnet, vous l'avez déjà 😄
- ComfyUI-Advanced-ControlNet, celui ci sert à mieux gérer les controlnetUnion
- ComfyUI_LayerStyle : Il peut servir à pas mal de trucs, notamment à travailler en "couches" comme sur photoshop, mais dans notre cas, il va juste servir à retirer la couche alpha de notre image
Ensuite vous pouvez utiliser ce workflow :
Le workflow complet ressemble à ceci, globalement il est identique à celui de base, avec quelques nouvelles nodes, colorées en jaune ci-contre :
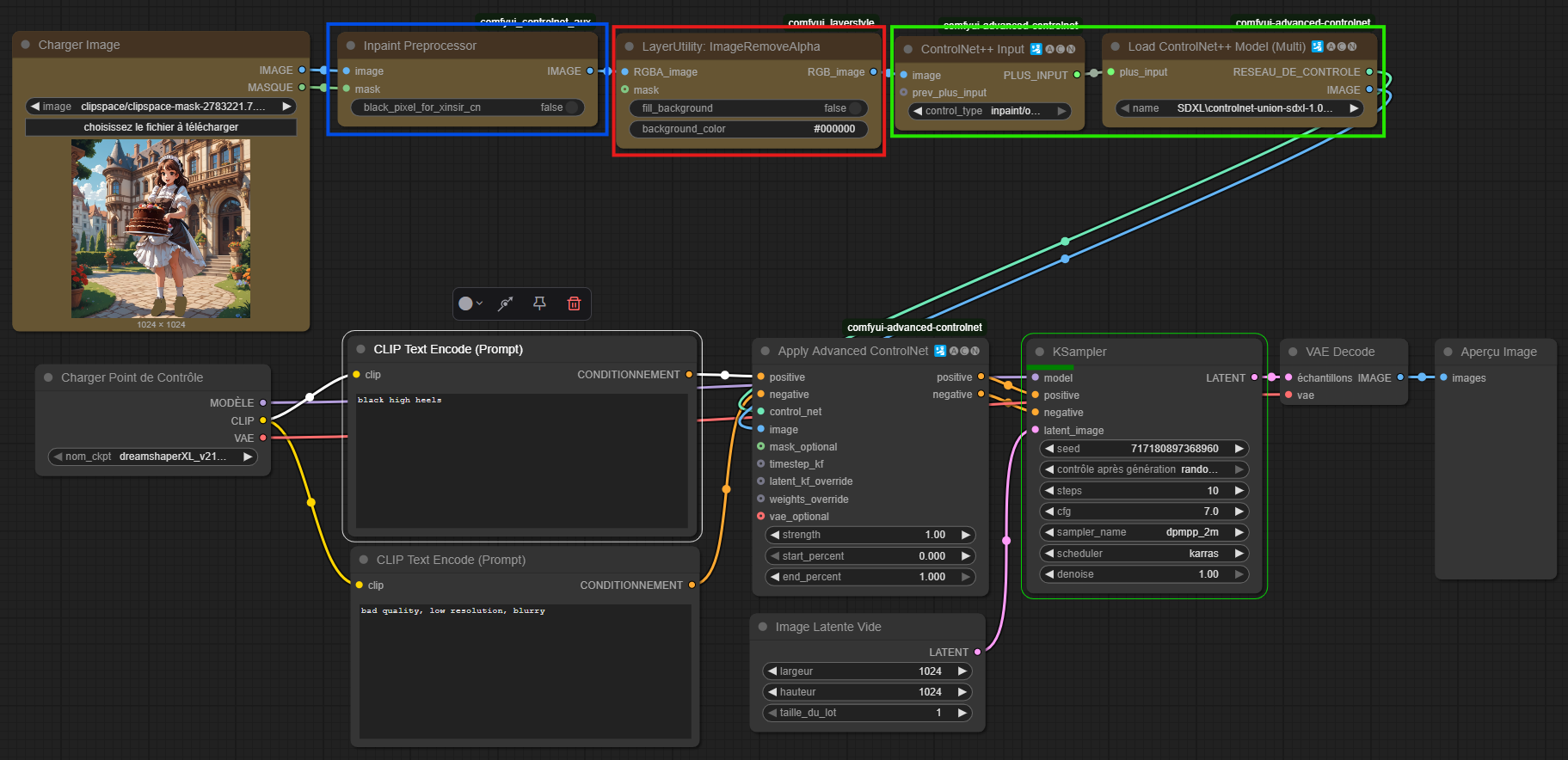
Dans l'ordre :
Inpaint Preprocessor : Prépare l'image à l'inpainting, plus précisément il marque les zones de pixels qui vont être générées, puis gère automatiquement les transitions, pour un résultat sans coutures.
Remove Image Alpha : Permet simplement de retirer la couche de transparence de l'image.
ControlnetInput et LoadControlNet ++ (Multi) : C'est ici que l'on sélectionne le type d'input (donc inpaint/outpaint pour notre cas), et que l'on fournit le modèle prévu. A savoir le controlnet union promax, provenant de la partie précédente sur les controlNet justement !
Etendre ses horizons avec l'Outpainting
Maintenant que l'on a vu l'inpainting, qui consiste à remplacer l'intérieur d'une image, imaginons que l'on "masque" les bords extérieurs d'une image. Le masque "s'étend". Ce qui permet de créer de l'espace de génération à notre IA ! C'est très pratique car on "imagine", ce qu'il peut y avoir au-delà l'image !
Un peu flou ? Voilà un exemple plus concret :

Pour le faire, on va partir du workflow d'inpainting, parce qu'il faut rajouter une seule et unique node, qui existe déjà de base dans comfyUI, il s'agit de padImageForOutPainting, ou en bon français : "Rembourrage d'image pour la peinture extérieure"
Elle se rajoute juste après le chargement de l'image et on utilise son masque dans l'inpaint Preprocessor
Le workflow mis à jour ressemble donc à cela :
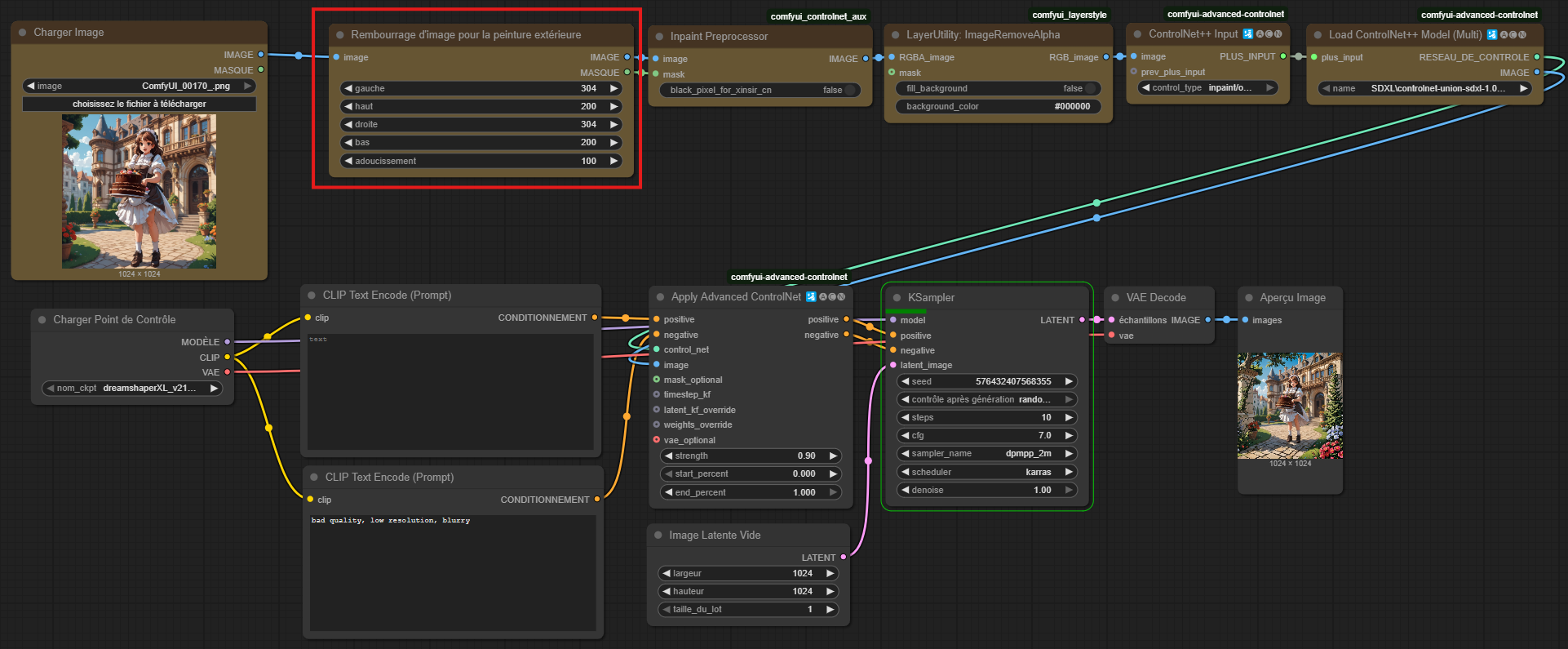
Dans cette nouvelle node on peut y paramétrer :
- Le nombre de pixels vers lequel on veut étendre le masque (vers la gauche, droite, haut, bas).
- L'adoucissement, cela permet de mettre un nombre de pixels pour gérer la transition entre l'image et le masque.
Pour des images plus grandes et détaillées, utilisez l’Upscaling !
Le souci avec la génération par IA, c'est que plus l'image que l'on souhaite est grande, plus cela prend du temps de traitement (logique, il y a plus d'informations dans l'image). Mais il existe une technique très intéressante pour obtenir des images immenses et détaillées, sans exploser les temps de calcul : l’upscaling.
Il s’agit d’un algorithme qui va détecter des motifs précis dans l’image, puis les étendre intelligemment.
Il comble les zones vides créées lors de l’agrandissement et, encore mieux, il peut ajouter des détails supplémentaires pendant le processus.
Pour l'implémenter rien de plus simple, il vous suffit de :
- Récupérer un modèle d'upscaling (RealESAGAN x2 ou x4 fonctionne très bien), pour cela, allez soit sur ce lien, puis placez le modèle téléchargé dans le dossier "comfyUi/models/upscaling".
- Ou alors, vous pouvez aussi passer par le Manager (en haut à droite dans l'interface de comfyUi), puis de cliquer sur Model manager. De là recherchez RealESAGAN puis installez le modèle.
- Puis de récupérer les nodes correspondantes. Les nodes jaunes sont celles qui ont été ajoutées, elles toutes sont disponibles dans la barre de recherche (double clic dans le workflow) avec le mot clé "upscaling".
Cela donne ce workflow dans notre pipeline :
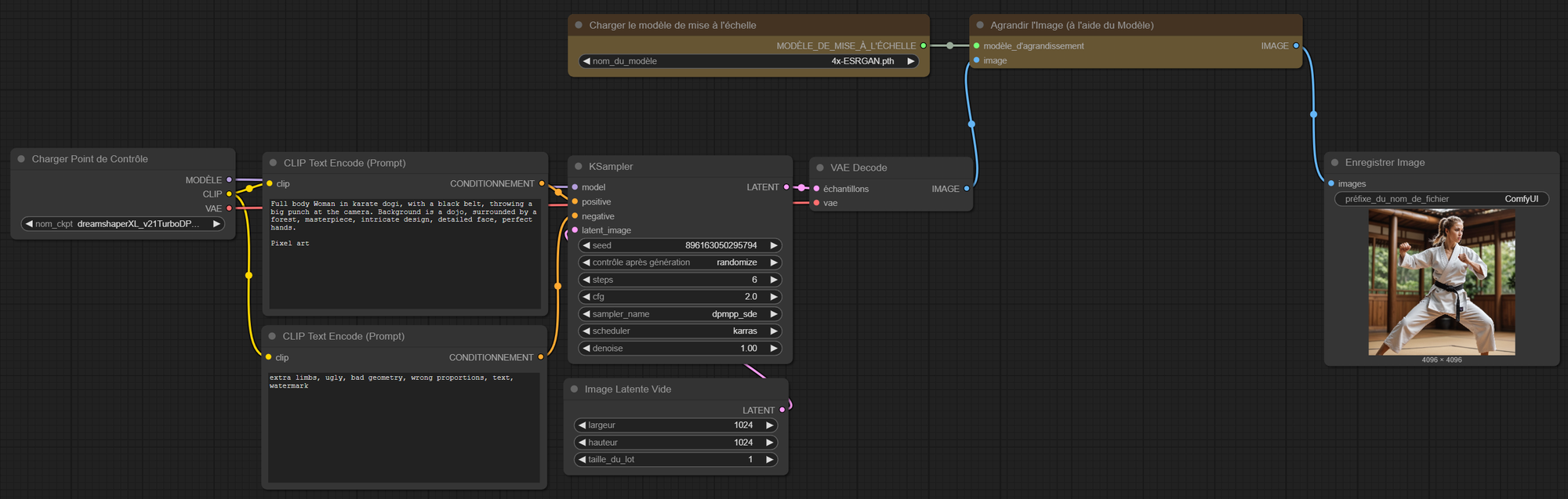
Comparatif des temps de génération :
Pour un même prompt, et une même seed :


De plus, les modèles ayant été entraînés avec une taille spécifique d'images, usuellement en 1024x1024, cela rend la génération vraiment difficile, voire juste buggée, comme ci-dessus.
Conclusion :
Ces techniques et outils permettent de personnaliser vos créations, de corriger des détails, d'étendre vos compositions et de produire des visuels haute résolution. Que vous soyez artiste numérique ou passionné de technologie, ces méthodes vous ouvriront de nouvelles perspectives pour exploiter pleinement le potentiel des modèles d'IA.






{kind=link}