
Abstract
Le Build with Gemini : Developers Summit de Google est l'occasion de présenter les nouveautés autour de Gemini par des experts à la communautés. Les sujets liés à l'intelligence artificielle et notamment l'IA générative évoluent très vite. Cette conférence est l'occasion pour moi de voir l'état de l'art sur ce qu'il se fait et se fera dans les mois à venir. Que cela soit conceptuel ou pratique, il y a des conférences pour toutes les approches. Cette conférence m'a également fait réaliser que des concepts d'IA jugés utile uniquement dans le monde de la recherche sont aujourd'hui en train d'être industrialisés. Notamment, la volonté de mettre en place des agents et des "plateforme d'intelligence artificielle" sonne comme la naissance de système multi-agents en entreprise.
Système Multi-Agents : kezako
Une redécouverte populaire
Lors de la création du terme "intelligence artificielle" dans les années 50, plusieurs concepts ont émergé :
- Les IA de type symbolique. Ce sont des IA totalement programmées, sans réseaux de neurones et sans boîte noire. Ce sont les premières "IA" à voir le jour car peu gourmandes en ressources. Les représentants les plus connues sont probablement les systèmes experts. Il s'agit d'un ensemble de règles explicites et d'un moteur d'inférence permettant un raisonnement. Les premiers à être crées sont DRANDAL et MYCIN.
- Les IA de type numériques. Ce sont ces IA là que nous côtoyons maintenant, à base de réseaux de neurones et de machine learning. Ces derniers sont en constante évolution avec de nouvelles méthodes pour être toujours plus performants.
- L'approche hybride. L'intelligence n'est pas unique, et à chaque problème une résolution différente peut être nécessaire. On confie alors des missions à des processus spécifiques, des agents. Dans la littérature scientifique, on parle notamment des Système multi-agents (SMA).
Le besoin des agents
Les LLM que l'on possède aujourd'hui sont de plus en plus performants. En revanche, ils auront toujours une faiblesse : les données d’entraînement ne constituent pas l'ensemble des champs d'interrogation. Dit autrement, c'est le problème des cut-off date ou encore des données privées, interne aux entreprises.
Le concept de Retrieval Augmented Generation (RAG) a été créé pour palier à ce problème, cependant un LLM seul n'est pas capable de faire ce travail. On commence à avoir besoin de plusieurs types de réseaux de neurones et/ou applications mathématiques avec des tâches spécifiques afin de proposer des IA de plus en plus performantes : un ensemble d'agents.
Cette nouvelle approche, qui gagne en popularité, donne naissance à des outils dédiés. On peut citer crewAI à titre d'exemple, mettant en avant la notion de "plateforme multi-agent".
Cas d'usage au Summit
Difficile de ne parler que d'un talk tant ceux auxquels j'ai assisté semblent liés par ce concept d'agents. De la conception d'une plateforme d'IA évolutive à trier ses collections de cartes Pokémon, de nombreux sujets ont attirés mon attention. Mais celui dont je souhaite parler se concentre plutôt sur comment avoir une IA experte en règles de jeux de sociétés, même sorti demain.
Créer son chatbot expert en jeux
Présenté par Matt Cornillon, ce talk est, à mon sens, un cas d'usage qui illustre le mieux ce besoin croissant d'agents dans un système complexe. La problématique est simple : pouvoir interroger un chatbot sur des points de règles précis avec preuve à l'appui de la réponse.
Vu la quantité de nouveaux jeux sortant régulièrement, on se heurte de plein fouet à la problématique principale des LLM et la cut-off date. Très vite, le speaker nous emmène vers le concept du RAG, mais pas seulement. A base de chunk et d'embedded, il illustre comment forcer un LLM à répondre dans un contexte précis et à jour. On lui fournit les données sur lesquelles il doit nous répondre.
Avant tout, à quoi correspondent les termes "chunk" et "embedded". Commençons par le chunk. Si vous avez joué à Minecraft, ce terme doit vous parler. Il s'agit d'un morceau de quelque chose. On peut aussi l'utiliser comme verbe pour indiquer que l'on découpe quelque chose.
La notion d'embedded est un peu plus complexe. Il faut remonter au début des modèles LLM basés sur BERT. Il s'agit d'une technique qui vise à convertir un mot en vecteur multidimensionnel mathématique. Les calculs sont toujours plus simple sur des objets mathématiques que les mots. L'intérêt de la méthode est sa capacité à saisir "l'essence" d'un terme par les vecteurs. Ainsi, les vecteurs "homme" + "royauté" donneront celui pour "roi", et ceux pour "femme" + "royauté" donneront celui pour "reine".
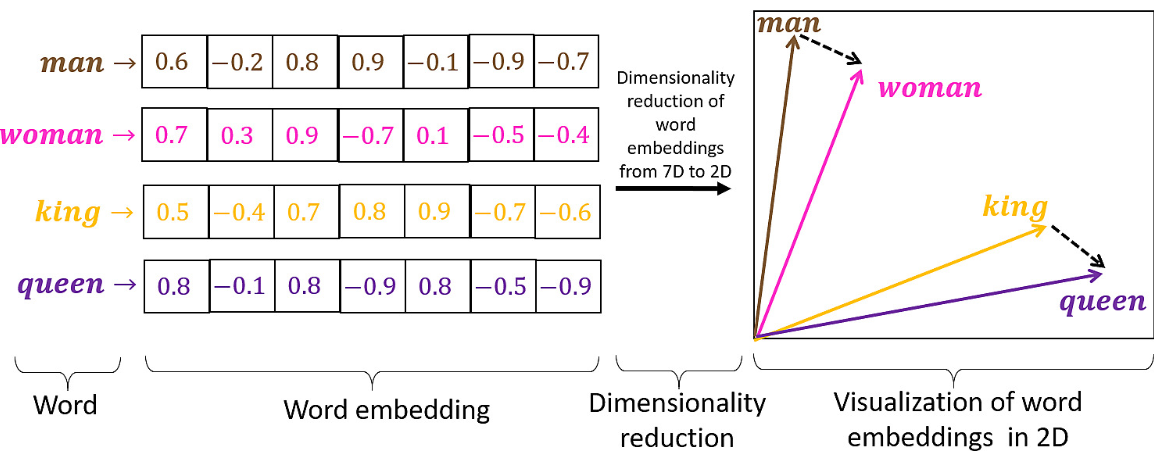
(source: https://airbyte.com/data-engineering-resources/sentence-word-embeddings)
Ces notions vont donc être utilisées afin de segmenter les règles d'un jeu et permettre d'identifier quelles sections vont être utiles à la réponse. La question de l'utilisateur sera convertie en embedded afin de pouvoir faire un calcul de distance vectoriel entre celle ci et les différents points de règles ayant été converties en embedded.
Cette logique permet la création d'une application avec un chatbot pour l'utilisateur qui lui donne la possibilité d'interroger directement les règles. Le chatbot aura ainsi un rôle d'orchestrateur.
Il faut en effet:
- retrouver les notions de règles utiles dans la question de l'utilisateur
- améliorer le prompt utilisateur, définir un contexte restreint et enrichi en données
- interroger un LLM pour que ce dernier fasse le travail de "recherche" dans les règles fourni dans le prompt enrichi
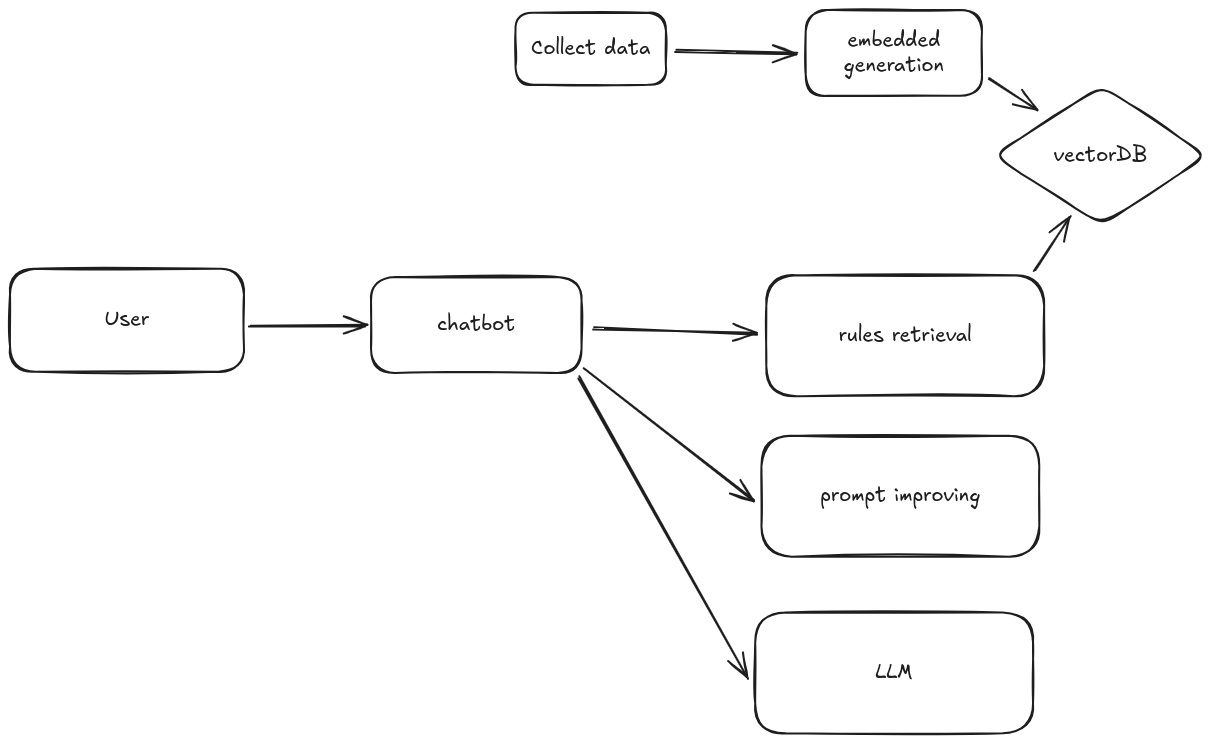
Tout cela ne concerne cependant que les éléments permettant la réponse finale à l'utilisateur. Il manque maintenant la construction de la base de données permettant de retrouver les sections de règles pertinentes.
Une partie de ce travail se fait de façon manuelle. Sur un site de référence, on télécharge les pdf des règles que l'on passe ensuite dans un système (ici Document AI, soit de l'OCR avec Gemini et structured output) afin d'obtenir un texte exploitable (en markdown par exemple, les LLM aiment bien ce format parait-il). Il y a ensuite les phases de chuncking et de conversion en embedded qui peuvent être automatisées avec un script dans votre langage favori avant d'être stocké.
Dans cet exemple, pas de notion d'agents, mais on peut très facilement en ajouter si l'on souhaite pousser le concept. On peut, par exemple, avoir des agents qui cherchent d'eux même les nouvelles règles, d'autres agents qui surveillent les sites officiels pour voir si des "amend" existent. Un cas d'usage serait pour le monde des TCG (Magic The Gathering, Yu-Gi-Oh ou encore Pokémon pour les plus connus. Notre speaker à d'ailleurs présenté un autre talk avec les mêmes outils pour identifier et vendre efficacement des collections de cartes Pokémons). Dans le cas des jeux plus classiques, il existe des jeux avec des combinaisons tellement complexes qu'elles n'ont pas forcément toutes pu être prédites par les concepteurs. Quand cela arrive, des points de règles sont crées sur ces jeux et il s'agit de les trouver sur les sites officiels. S'il existe un agent pour trouver des amends sur des règles, d'autres peuvent avoir pour tâches de s'assurer que les règles actuellement stockés ne sont pas contradictoires et assurer l'intégrité de la base de connaissances.
Au sommet
La genAI a encore beaucoup de nouveautés qui arrivent. La notion d'agents va permettre de créer des systèmes complets et non plus seulement des modèles qui, même s'ils sont multi-modaux ne pourront résoudre toutes les tâches. Au delà de ça, ils sont aussi très énergivore.
Dans le contexte actuel, les orchestrateurs permettent déjà la création de systèmes complexes qui savent décider si il est nécessaire d'interroger des modèles plus performant ou rendre de lui même des réponses simple. Les agents vont permettre à ces systèmes d'être force de proposition et ne plus se contenter uniquement de nous assister.




{kind=link}