
La mise en cache est une pratique incontournable pour améliorer les performances d’une application en réduisant les accès coûteux à la base de données ou à une API externe.
Dans un précédent article, nous avons exploré Caffeine, une solution de cache local en mémoire. Cette fois-ci, intéressons-nous à Redis, un cache distribué particulièrement adapté aux environnements scalables où plusieurs instances de l’application doivent partager les mêmes données en mémoire.
Présentation de Redis
Redis (REmote DIctionary Server) est un moteur de stockage en mémoire très rapide, utilisé principalement comme cache, broker de messages ou base de données NoSQL. Contrairement aux bases de données traditionnelles, Redis stocke toutes les données en RAM, ce qui lui permet de répondre à des requêtes en quelques microsecondes, même sous des charges très importantes.
Redis n’est pas limité au simple stockage clé-valeur. Il prend en charge une variété de structures de données : listes, ensembles, hachages, sorted sets, bitmaps, hyperloglogs, et streams. Cette richesse le rend très flexible et lui permet de gérer des cas d’usage variés, allant de la mise en cache classique à des systèmes de files d’attente ou de comptage en temps réel.
De plus, Redis offre des fonctionnalités avancées comme la persistance des données sur disque, la réplication maître-esclave, le clustering, et des mécanismes de pub/sub pour la communication en temps réel. Ces caractéristiques en font un outil apprécié dans des architectures modernes, distribuées et scalables, où la rapidité et le partage des données entre plusieurs instances sont essentiels.
Mise en place technique avec Docker
Pour démarrer rapidement, on peut utiliser Redis avec Docker et l’outil RedisInsight pour visualiser son contenu :
services:
redis:
image: "redis:alpine"
ports:
- "6379:6379"
redisinsight:
image: redis/redisinsight:latest
ports:
- "5540:5540"
volumes:
- redisinsight-data:/data
volumes:
redisinsight-data:- redis : le moteur Redis, accessible sur le port
6379. - redisinsight : une interface graphique pratique pour explorer et analyser les données.
⚖️ Les avantages et inconvénients de Redis
➕ Avantages
- Cache distribué : partagé entre toutes les instances d’une application.
- Performances élevées : latence très faible, même avec de fortes charges.
- Expiration fine (TTL) : évite de conserver des données obsolètes.
- Fonctionnalités avancées : réplication, clustering, persistance, pub/sub.
- Polyvalence : support de nombreuses structures de données.
➖ Inconvénients
- Dépendance à un service externe : Redis doit être déployé et maintenu.
- Surcharge réseau : chaque requête implique un aller-retour avec Redis.
- Complexité supplémentaire : sécurité, haute disponibilité, monitoring.
- Consommation mémoire : Redis stocke tout en RAM, ce qui peut coûter cher.
Installation de Redis dans votre projet
Dépendances
Dans votre fichier pom.xml, ajoutez les dépendances suivantes :
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>Configuration dans Spring Boot
Pour un démarrage rapide, on peut se contenter des propriétés suivantes, et laisser faire la magie de l'auto-configuration de Spring Boot.
spring.data.redis.host=localhost
spring.data.redis.port=6379Dans une application plus avancée, l'on peut également ajouter une classe de configuration pour affiner un peu plus notre système de cache :
@Configuration
@EnableCaching
public class RedisConfig {
@Bean
public RedisCacheConfiguration cacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(10))
.disableCachingNullValues()
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())
);
}
}Cela nous permet de gérer :
- la durée de vie des données en cache.
- de ne pas mettre en cache des valeurs nulles
- la sérialisation des données
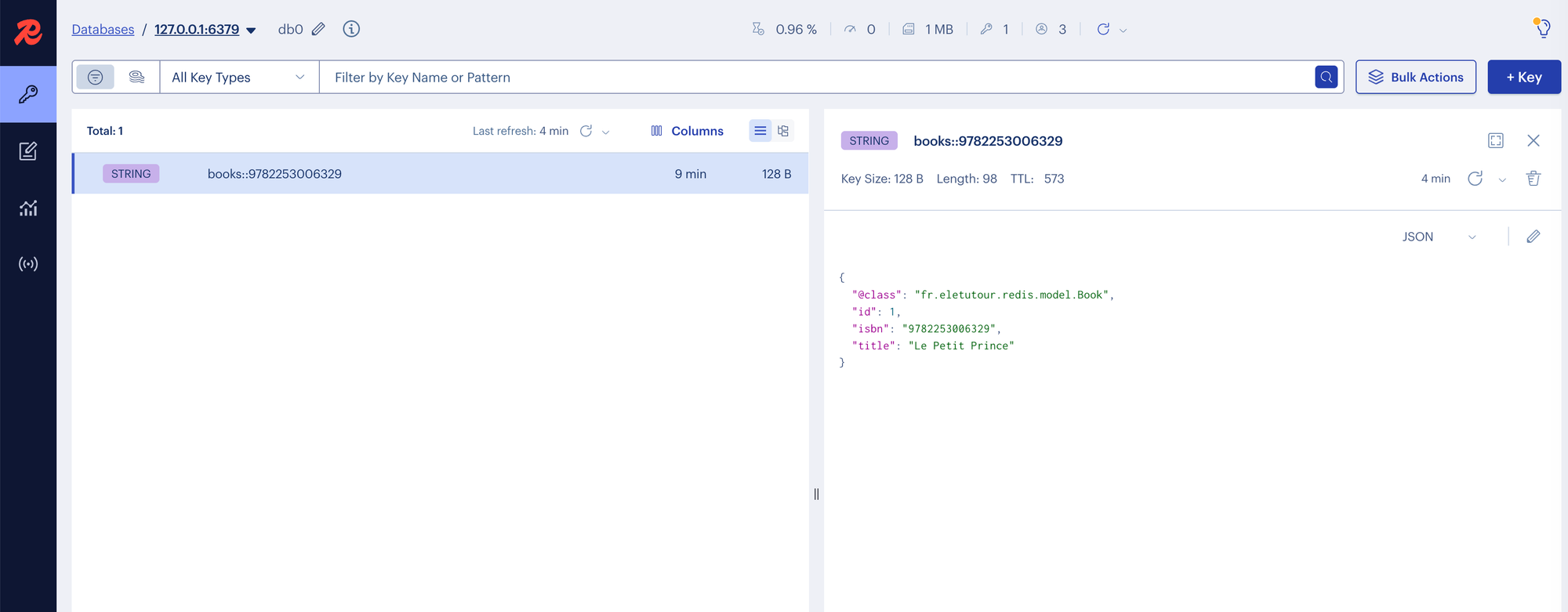
Le service
Nous allons réutiliser le même service que lors des articles précédents traitant du cache :
@Service
public class BookService {
private static final Logger LOG = LoggerFactory.getLogger(BookService.class);
private final BookRepository bookRepository;
public BookService(BookRepository bookRepository) {
this.bookRepository = bookRepository;
}
@Cacheable(value = "books", key = "#isbn")
public Book findBookByIsbn(String isbn) {
long start = System.currentTimeMillis();
simulateSlowService(); // simule un traitement lourd
Book book = bookRepository.findByIsbn(isbn);
long end = System.currentTimeMillis();
LOG.info("findBookByIsbn({}) exécuté en {} ms", isbn, (end - start));
LOG.info("Book : {}", book);
return book;
}
@CachePut(value = "books", key = "#book.isbn")
public Book saveOrUpdateBook(Book book) {
LOG.info("Mise à jour / ajout du livre [{}] en base et dans le cache", book.getIsbn());
return bookRepository.save(book);
}
@CacheEvict(value = "books", key = "#isbn")
public void deleteBookByIsbn(String isbn) {
Optional<Book> book = Optional.ofNullable(bookRepository.findByIsbn(isbn));
book.ifPresent(b -> {
bookRepository.delete(b);
LOG.info("Suppression du livre [{}] en base et invalidation du cache", isbn);
});
}
private void simulateSlowService() {
try {
Thread.sleep(3000L); // pause artificielle
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new IllegalStateException(e);
}
}
}Explications des annotations
@Cacheable- Met en cache le résultat d’une méthode.
- Premier appel → méthode exécutée et résultat stocké.
- Appels suivants avec la même clé → valeur renvoyée depuis le cache, pas d’exécution.
@CachePut- Met à jour le cache à chaque exécution de la méthode.
- Utilisé pour les opérations d’écriture (ajout ou modification).
@CacheEvict- Supprime une entrée du cache.
- Utilisé pour éviter de servir des données obsolètes après une suppression ou une modification.
- Possibilité de vider tout le cache avec
allEntries = true.
Comparatif des solutions de cache
| Solution | Localisation des données | Performance | Persistance | Fonctionnalités | Cas d’usage idéal |
|---|---|---|---|---|---|
| Cache simple (Spring @Cacheable par défaut) | Mémoire locale de la JVM | Très rapide (accès direct mémoire) | Aucune (perdue au redémarrage) | Minimal (clé/valeur) | Projets simples, monolithiques, où chaque instance gère son propre cache |
| Caffeine | Mémoire locale de la JVM | Très rapide (optimisé en Java) | Aucune (perdue au redémarrage) | Gestion fine : LRU, expiration par taille ou temps, statistiques | Applications nécessitant un cache local performant avec stratégies avancées d’éviction |
| Redis | Stockage en mémoire externe (serveur Redis) | Très rapide (mais via réseau) | Optionnelle (snapshot ou log AOF) | Structures riches (listes, sets, streams…), clustering, réplication, TTL, pub/sub | Applications distribuées, microservices, partage de cache entre plusieurs instances |
Conclusion
Redis est un cache distribué puissant et polyvalent, capable de bien plus que stocker des données temporaires. Sa rapidité, ses fonctionnalités avancées et son adaptabilité aux environnements distribués en font une solution incontournable dans de nombreux projets modernes.
Avec Spring Boot, son intégration est simple grâce aux starters et à l’auto-configuration, et RedisInsight permet de visualiser et comprendre en un coup d’œil ce qui se passe côté cache.
Tout le code relatif à cet article est disponible ici :










{kind=link}